 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNatural Fingerprints of Large Language Models
Apr 21, 2025
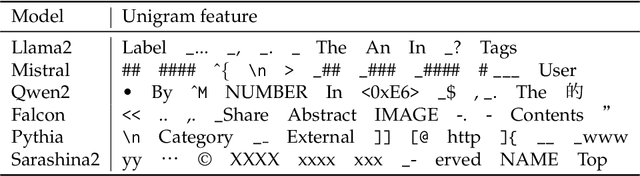
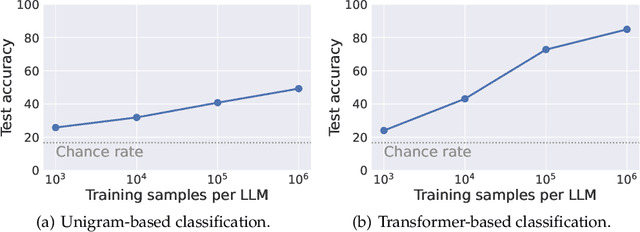

Large language models (LLMs) often exhibit biases -- systematic deviations from expected norms -- in their outputs. These range from overt issues, such as unfair responses, to subtler patterns that can reveal which model produced them. We investigate the factors that give rise to identifiable characteristics in LLMs. Since LLMs model training data distribution, it is reasonable that differences in training data naturally lead to the characteristics. However, our findings reveal that even when LLMs are trained on the exact same data, it is still possible to distinguish the source model based on its generated text. We refer to these unintended, distinctive characteristics as natural fingerprints. By systematically controlling training conditions, we show that the natural fingerprints can emerge from subtle differences in the training process, such as parameter sizes, optimization settings, and even random seeds. We believe that understanding natural fingerprints offers new insights into the origins of unintended bias and ways for improving control over LLM behavior.
Self-Preference Bias in LLM-as-a-Judge
Oct 29, 2024



Automated evaluation leveraging large language models (LLMs), commonly referred to as LLM evaluators or LLM-as-a-judge, has been widely used in measuring the performance of dialogue systems. However, the self-preference bias in LLMs has posed significant risks, including promoting specific styles or policies intrinsic to the LLMs. Despite the importance of this issue, there is a lack of established methods to measure the self-preference bias quantitatively, and its underlying causes are poorly understood. In this paper, we introduce a novel quantitative metric to measure the self-preference bias. Our experimental results demonstrate that GPT-4 exhibits a significant degree of self-preference bias. To explore the causes, we hypothesize that LLMs may favor outputs that are more familiar to them, as indicated by lower perplexity. We analyze the relationship between LLM evaluations and the perplexities of outputs. Our findings reveal that LLMs assign significantly higher evaluations to outputs with lower perplexity than human evaluators, regardless of whether the outputs were self-generated. This suggests that the essence of the bias lies in perplexity and that the self-preference bias exists because LLMs prefer texts more familiar to them.
Self-Translate-Train: A Simple but Strong Baseline for Cross-lingual Transfer of Large Language Models
Jun 29, 2024Cross-lingual transfer is a promising technique for utilizing data in a source language to improve performance in a target language. However, current techniques often require an external translation system or suffer from suboptimal performance due to over-reliance on cross-lingual generalization of multi-lingual pretrained language models. In this study, we propose a simple yet effective method called Self-Translate-Train. It leverages the translation capability of a large language model to generate synthetic training data in the target language and fine-tunes the model with its own generated data. We evaluate the proposed method on a wide range of tasks and show substantial performance gains across several non-English languages.
Large Vocabulary Size Improves Large Language Models
Jun 24, 2024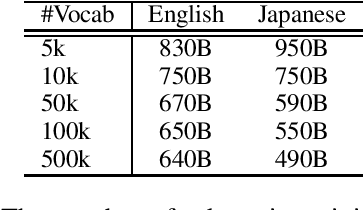
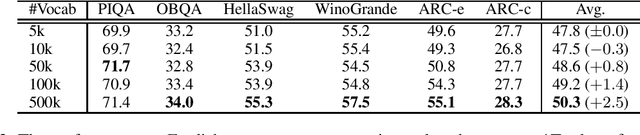
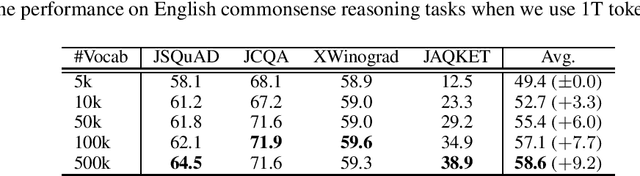

This paper empirically investigates the relationship between subword vocabulary size and the performance of large language models (LLMs) to provide insights on how to define the vocabulary size. Experimental results show that larger vocabulary sizes lead to better performance in LLMs. Moreover, we consider a continual training scenario where a pre-trained language model is trained on a different target language. We introduce a simple method to use a new vocabulary instead of the pre-defined one. We show that using the new vocabulary outperforms the model with the vocabulary used in pre-training.
LEIA: Facilitating Cross-Lingual Knowledge Transfer in Language Models with Entity-based Data Augmentation
Feb 18, 2024
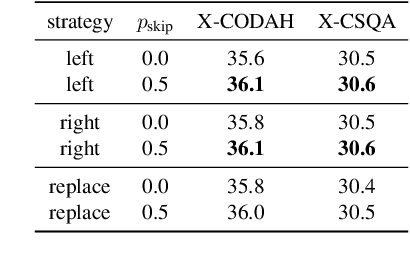

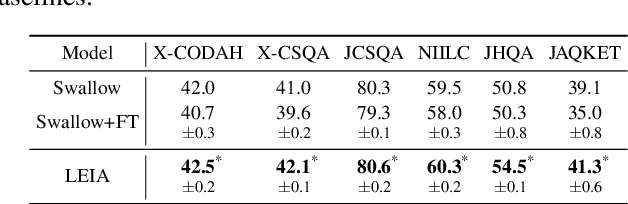
Adapting English-based large language models (LLMs) to other languages has become increasingly popular due to the efficiency and potential of cross-lingual transfer. However, existing language adaptation methods often overlook the benefits of cross-lingual supervision. In this study, we introduce LEIA, a language adaptation tuning method that utilizes Wikipedia entity names aligned across languages. This method involves augmenting the target language corpus with English entity names and training the model using left-to-right language modeling. We assess LEIA on diverse question answering datasets using 7B-parameter LLMs, demonstrating significant performance gains across various non-English languages. The source code is available at https://github.com/studio-ousia/leia.
Emergent Communication with Attention
May 18, 2023



To develop computational agents that better communicate using their own emergent language, we endow the agents with an ability to focus their attention on particular concepts in the environment. Humans often understand an object or scene as a composite of concepts and those concepts are further mapped onto words. We implement this intuition as cross-modal attention mechanisms in Speaker and Listener agents in a referential game and show attention leads to more compositional and interpretable emergent language. We also demonstrate how attention aids in understanding the learned communication protocol by investigating the attention weights associated with each message symbol and the alignment of attention weights between Speaker and Listener agents. Overall, our results suggest that attention is a promising mechanism for developing more human-like emergent language.
EASE: Entity-Aware Contrastive Learning of Sentence Embedding
May 09, 2022

We present EASE, a novel method for learning sentence embeddings via contrastive learning between sentences and their related entities. The advantage of using entity supervision is twofold: (1) entities have been shown to be a strong indicator of text semantics and thus should provide rich training signals for sentence embeddings; (2) entities are defined independently of languages and thus offer useful cross-lingual alignment supervision. We evaluate EASE against other unsupervised models both in monolingual and multilingual settings. We show that EASE exhibits competitive or better performance in English semantic textual similarity (STS) and short text clustering (STC) tasks and it significantly outperforms baseline methods in multilingual settings on a variety of tasks. Our source code, pre-trained models, and newly constructed multilingual STC dataset are available at https://github.com/studio-ousia/ease.
Pretraining with Artificial Language: Studying Transferable Knowledge in Language Models
Mar 22, 2022


We investigate what kind of structural knowledge learned in neural network encoders is transferable to processing natural language. We design artificial languages with structural properties that mimic natural language, pretrain encoders on the data, and see how much performance the encoder exhibits on downstream tasks in natural language. Our experimental results show that pretraining with an artificial language with a nesting dependency structure provides some knowledge transferable to natural language. A follow-up probing analysis indicates that its success in the transfer is related to the amount of encoded contextual information and what is transferred is the knowledge of position-aware context dependence of language. Our results provide insights into how neural network encoders process human languages and the source of cross-lingual transferability of recent multilingual language models.
mLUKE: The Power of Entity Representations in Multilingual Pretrained Language Models
Oct 15, 2021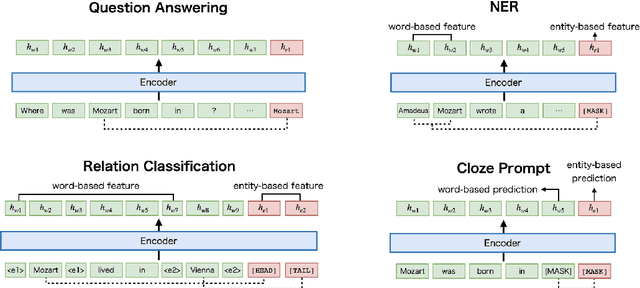


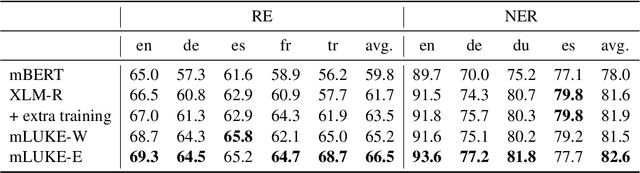
Recent studies have shown that multilingual pretrained language models can be effectively improved with cross-lingual alignment information from Wikipedia entities. However, existing methods only exploit entity information in pretraining and do not explicitly use entities in downstream tasks. In this study, we explore the effectiveness of leveraging entity representations for downstream cross-lingual tasks. We train a multilingual language model with 24 languages with entity representations and show the model consistently outperforms word-based pretrained models in various cross-lingual transfer tasks. We also analyze the model and the key insight is that incorporating entity representations into the input allows us to extract more language-agnostic features. We also evaluate the model with a multilingual cloze prompt task with the mLAMA dataset. We show that entity-based prompt elicits correct factual knowledge more likely than using only word representations.
Modeling Target-side Inflection in Placeholder Translation
Jul 01, 2021
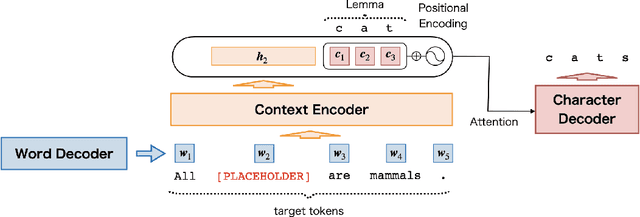
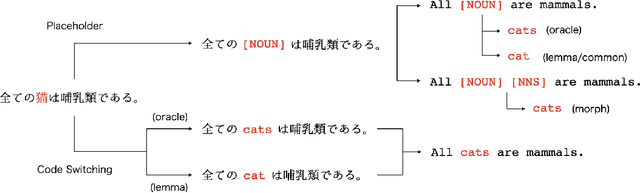
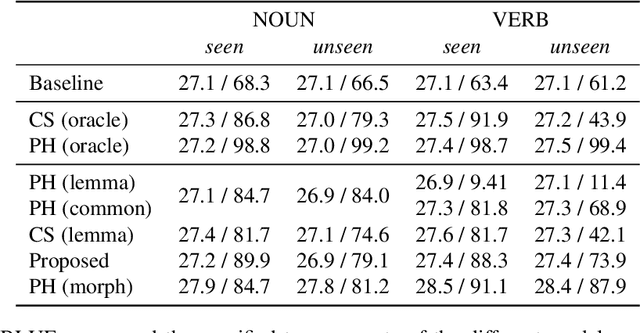
Placeholder translation systems enable the users to specify how a specific phrase is translated in the output sentence. The system is trained to output special placeholder tokens, and the user-specified term is injected into the output through the context-free replacement of the placeholder token. However, this approach could result in ungrammatical sentences because it is often the case that the specified term needs to be inflected according to the context of the output, which is unknown before the translation. To address this problem, we propose a novel method of placeholder translation that can inflect specified terms according to the grammatical construction of the output sentence. We extend the sequence-to-sequence architecture with a character-level decoder that takes the lemma of a user-specified term and the words generated from the word-level decoder to output the correct inflected form of the lemma. We evaluate our approach with a Japanese-to-English translation task in the scientific writing domain, and show that our model can incorporate specified terms in the correct form more successfully than other comparable models.