 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredict, Don't React: Value-Based Safety Forecasting for LLM Streaming
Apr 05, 2026In many practical LLM deployments, a single guardrail is used for both prompt and response moderation. Prompt moderation operates on fully observed text, whereas streaming response moderation requires safety decisions to be made over partial generations. Existing text-based streaming guardrails commonly frame this output-side problem as boundary detection, training models to identify the earliest prefix at which a response has already become unsafe. In this work, we introduce StreamGuard, a unified model-agnostic streaming guardrail that instead formulates moderation as a forecasting problem: given a partial prefix, the model predicts the expected harmfulness of likely future continuations. We supervise this prediction using Monte Carlo rollouts, which enables early intervention without requiring exact token-level boundary annotations. Across standard safety benchmarks, StreamGuard performs strongly both for input moderation and for streaming output moderation. At the 8B scale, StreamGuard improves aggregated input-moderation F1 from 86.7 to 88.2 and aggregated streaming output-moderation F1 from 80.4 to 81.9 relative to Qwen3Guard-Stream-8B-strict. On the QWENGUARDTEST response_loc streaming benchmark, StreamGuard reaches 97.5 F1, 95.1 recall, and 92.6% on-time intervention, compared to 95.9 F1, 92.1 recall, and 89.9% for Qwen3Guard-Stream-8B-stric, while reducing the miss rate from 7.9% to 4.9%. We further show that forecasting-based supervision transfers effectively across tokenizers and model families: with transferred targets, Gemma3-StreamGuard-1B reaches 81.3 response-moderation F1, 98.2 streaming F1, and a 3.5% miss rate. These results show that strong end-to-end streaming moderation can be obtained without exact boundary labels, and that forecasting future risk is an effective supervision strategy for low-latency safety intervention.
Self-Preference Bias in LLM-as-a-Judge
Oct 29, 2024



Automated evaluation leveraging large language models (LLMs), commonly referred to as LLM evaluators or LLM-as-a-judge, has been widely used in measuring the performance of dialogue systems. However, the self-preference bias in LLMs has posed significant risks, including promoting specific styles or policies intrinsic to the LLMs. Despite the importance of this issue, there is a lack of established methods to measure the self-preference bias quantitatively, and its underlying causes are poorly understood. In this paper, we introduce a novel quantitative metric to measure the self-preference bias. Our experimental results demonstrate that GPT-4 exhibits a significant degree of self-preference bias. To explore the causes, we hypothesize that LLMs may favor outputs that are more familiar to them, as indicated by lower perplexity. We analyze the relationship between LLM evaluations and the perplexities of outputs. Our findings reveal that LLMs assign significantly higher evaluations to outputs with lower perplexity than human evaluators, regardless of whether the outputs were self-generated. This suggests that the essence of the bias lies in perplexity and that the self-preference bias exists because LLMs prefer texts more familiar to them.
MergePrint: Robust Fingerprinting against Merging Large Language Models
Oct 11, 2024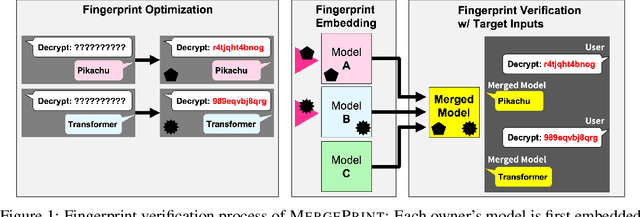
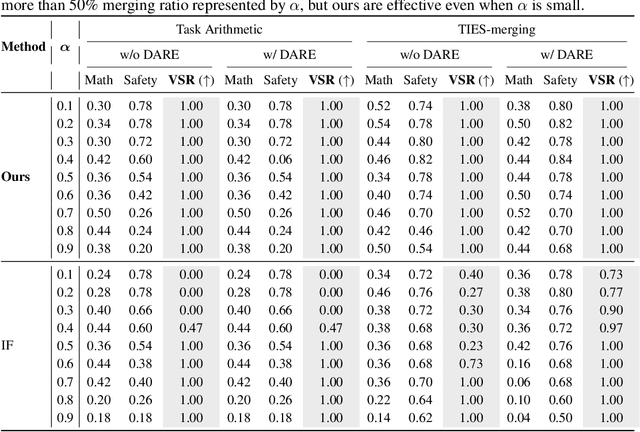
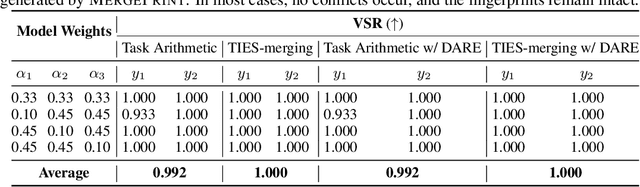
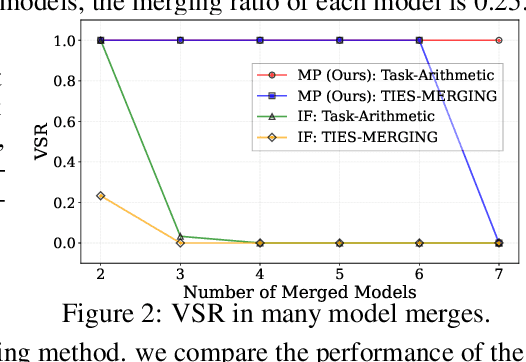
As the cost of training large language models (LLMs) rises, protecting their intellectual property has become increasingly critical. Model merging, which integrates multiple expert models into a single model capable of performing multiple tasks, presents a growing risk of unauthorized and malicious usage. While fingerprinting techniques have been studied for asserting model ownership, existing methods have primarily focused on fine-tuning, leaving model merging underexplored. To address this gap, we propose a novel fingerprinting method MergePrint that embeds robust fingerprints designed to preserve ownership claims even after model merging. By optimizing against a pseudo-merged model, which simulates post-merged model weights, MergePrint generates fingerprints that remain detectable after merging. Additionally, we optimize the fingerprint inputs to minimize performance degradation, enabling verification through specific outputs from targeted inputs. This approach provides a practical fingerprinting strategy for asserting ownership in cases of misappropriation through model merging.
Verbosity Bias in Preference Labeling by Large Language Models
Oct 16, 2023
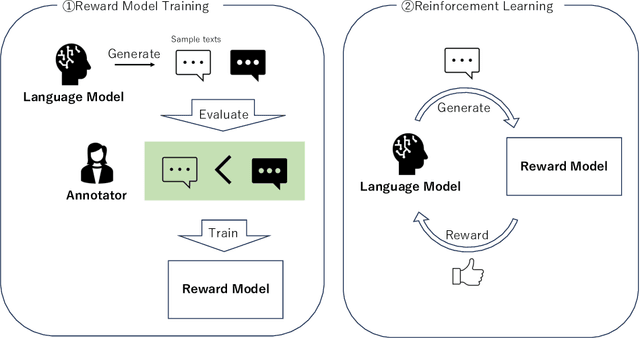
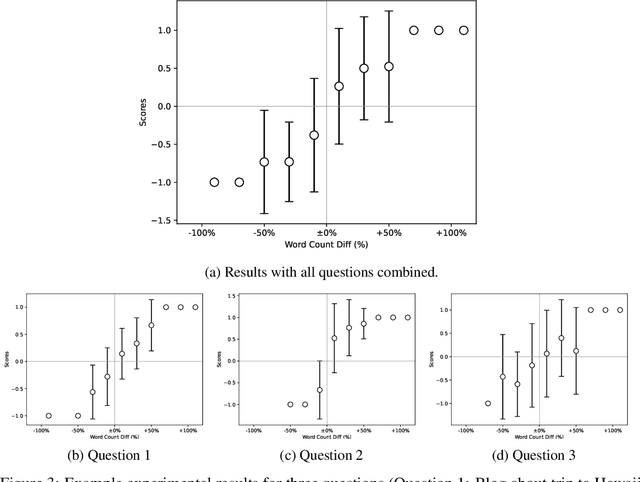
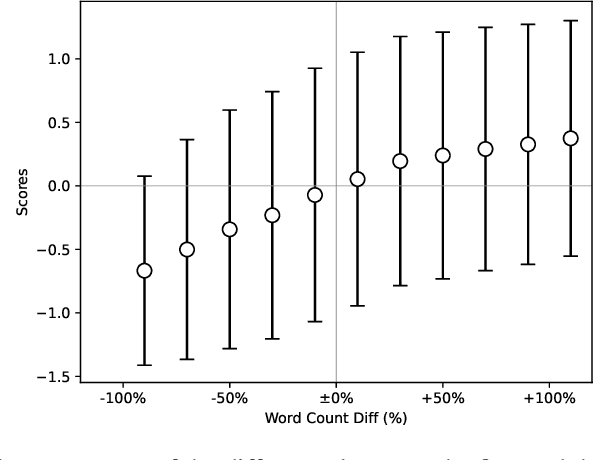
In recent years, Large Language Models (LLMs) have witnessed a remarkable surge in prevalence, altering the landscape of natural language processing and machine learning. One key factor in improving the performance of LLMs is alignment with humans achieved with Reinforcement Learning from Human Feedback (RLHF), as for many LLMs such as GPT-4, Bard, etc. In addition, recent studies are investigating the replacement of human feedback with feedback from other LLMs named Reinforcement Learning from AI Feedback (RLAIF). We examine the biases that come along with evaluating LLMs with other LLMs and take a closer look into verbosity bias -- a bias where LLMs sometimes prefer more verbose answers even if they have similar qualities. We see that in our problem setting, GPT-4 prefers longer answers more than humans. We also propose a metric to measure this bias.