 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCost-Minimized Label-Flipping Poisoning Attack to LLM Alignment
Nov 12, 2025Large language models (LLMs) are increasingly deployed in real-world systems, making it critical to understand their vulnerabilities. While data poisoning attacks during RLHF/DPO alignment have been studied empirically, their theoretical foundations remain unclear. We investigate the minimum-cost poisoning attack required to steer an LLM's policy toward an attacker's target by flipping preference labels during RLHF/DPO, without altering the compared outputs. We formulate this as a convex optimization problem with linear constraints, deriving lower and upper bounds on the minimum attack cost. As a byproduct of this theoretical analysis, we show that any existing label-flipping attack can be post-processed via our proposed method to reduce the number of label flips required while preserving the intended poisoning effect. Empirical results demonstrate that this cost-minimization post-processing can significantly reduce poisoning costs over baselines, particularly when the reward model's feature dimension is small relative to the dataset size. These findings highlight fundamental vulnerabilities in RLHF/DPO pipelines and provide tools to evaluate their robustness against low-cost poisoning attacks.
Verbosity Bias in Preference Labeling by Large Language Models
Oct 16, 2023
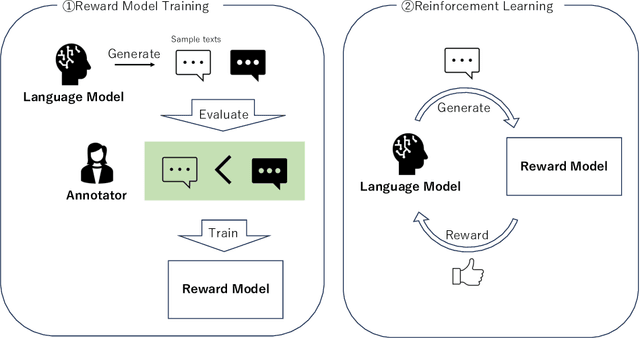
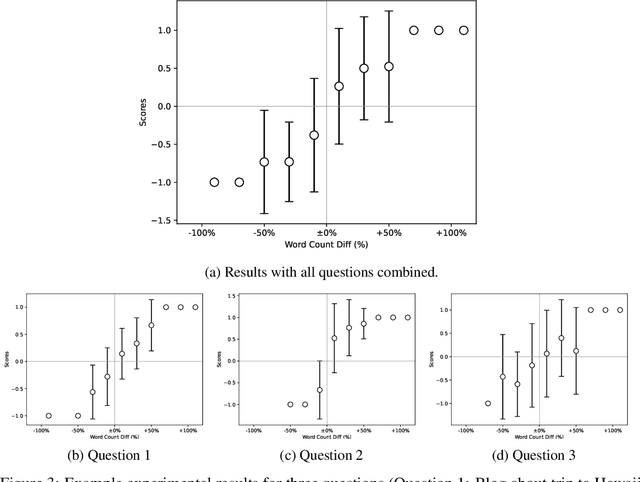
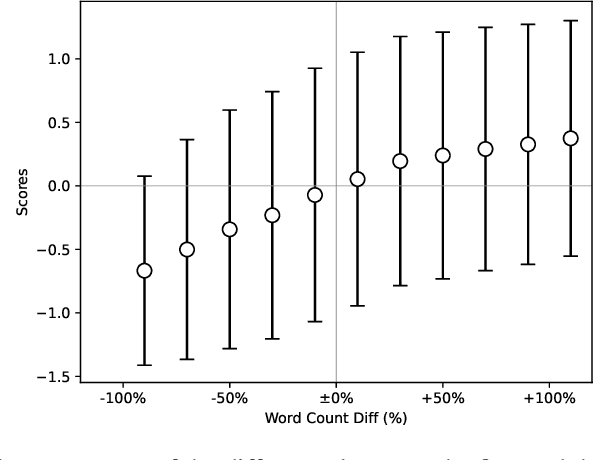
In recent years, Large Language Models (LLMs) have witnessed a remarkable surge in prevalence, altering the landscape of natural language processing and machine learning. One key factor in improving the performance of LLMs is alignment with humans achieved with Reinforcement Learning from Human Feedback (RLHF), as for many LLMs such as GPT-4, Bard, etc. In addition, recent studies are investigating the replacement of human feedback with feedback from other LLMs named Reinforcement Learning from AI Feedback (RLAIF). We examine the biases that come along with evaluating LLMs with other LLMs and take a closer look into verbosity bias -- a bias where LLMs sometimes prefer more verbose answers even if they have similar qualities. We see that in our problem setting, GPT-4 prefers longer answers more than humans. We also propose a metric to measure this bias.