 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLEIA: Facilitating Cross-Lingual Knowledge Transfer in Language Models with Entity-based Data Augmentation
Paper and Code

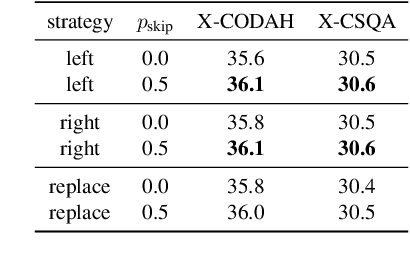

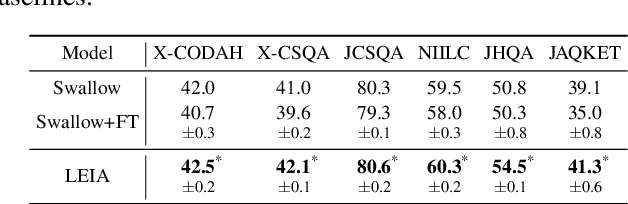
Adapting English-based large language models (LLMs) to other languages has become increasingly popular due to the efficiency and potential of cross-lingual transfer. However, existing language adaptation methods often overlook the benefits of cross-lingual supervision. In this study, we introduce LEIA, a language adaptation tuning method that utilizes Wikipedia entity names aligned across languages. This method involves augmenting the target language corpus with English entity names and training the model using left-to-right language modeling. We assess LEIA on diverse question answering datasets using 7B-parameter LLMs, demonstrating significant performance gains across various non-English languages. The source code is available at https://github.com/studio-ousia/leia.