 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNatural Fingerprints of Large Language Models
Paper and Code
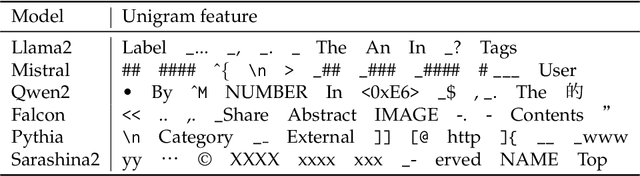
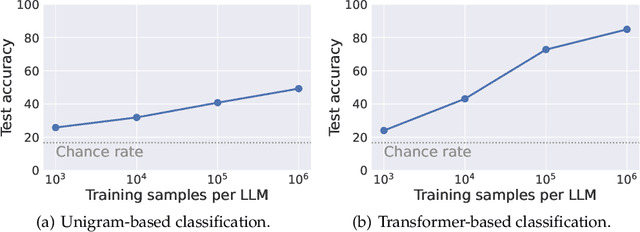

Large language models (LLMs) often exhibit biases -- systematic deviations from expected norms -- in their outputs. These range from overt issues, such as unfair responses, to subtler patterns that can reveal which model produced them. We investigate the factors that give rise to identifiable characteristics in LLMs. Since LLMs model training data distribution, it is reasonable that differences in training data naturally lead to the characteristics. However, our findings reveal that even when LLMs are trained on the exact same data, it is still possible to distinguish the source model based on its generated text. We refer to these unintended, distinctive characteristics as natural fingerprints. By systematically controlling training conditions, we show that the natural fingerprints can emerge from subtle differences in the training process, such as parameter sizes, optimization settings, and even random seeds. We believe that understanding natural fingerprints offers new insights into the origins of unintended bias and ways for improving control over LLM behavior.