 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePre-training LLM without Learning Rate Decay Enhances Supervised Fine-Tuning
Mar 17, 2026We investigate the role of learning rate scheduling in the large-scale pre-training of large language models, focusing on its influence on downstream performance after supervised fine-tuning (SFT). Decay-based learning rate schedulers are widely used to minimize pre-training loss. However, despite their widespread use, how these schedulers affect performance after SFT remains underexplored. In this paper, we examine Warmup-Stable-Only (WSO), which maintains a constant learning rate after warmup without any decay. Through experiments with 1B and 8B parameter models, we show that WSO consistently outperforms decay-based schedulers in terms of performance after SFT, even though decay-based schedulers may exhibit better performance after pre-training. The result also holds across different regimes with mid-training and over-training. Loss landscape analysis further reveals that decay-based schedulers lead models into sharper minima, whereas WSO preserves flatter minima that support adaptability. These findings indicate that applying LR decay to improve pre-training metrics may compromise downstream adaptability. Our work also provides practical guidance for training and model release strategies, highlighting that pre-training models with WSO enhances their adaptability for downstream tasks.
Efficient Construction of Model Family through Progressive Training Using Model Expansion
Apr 01, 2025As Large Language Models (LLMs) gain widespread practical application, providing the model family of different parameter sizes has become standard practice to address diverse computational requirements. Conventionally, each model in a family is trained independently, resulting in computational costs that scale additively with the number of models. We propose an efficient method for constructing the model family through progressive training, where smaller models are incrementally expanded to larger sizes to create a complete model family. Through extensive experiments with a model family ranging from 1B to 8B parameters, we demonstrate that our method reduces computational costs by approximately 25% while maintaining comparable performance to independently trained models. Furthermore, by strategically adjusting maximum learning rates based on model size, our method outperforms the independent training across various metrics. Beyond performance gains, our approach offers an additional advantage: models in our family tend to yield more consistent behavior across different model sizes.
Self-Translate-Train: A Simple but Strong Baseline for Cross-lingual Transfer of Large Language Models
Jun 29, 2024Cross-lingual transfer is a promising technique for utilizing data in a source language to improve performance in a target language. However, current techniques often require an external translation system or suffer from suboptimal performance due to over-reliance on cross-lingual generalization of multi-lingual pretrained language models. In this study, we propose a simple yet effective method called Self-Translate-Train. It leverages the translation capability of a large language model to generate synthetic training data in the target language and fine-tunes the model with its own generated data. We evaluate the proposed method on a wide range of tasks and show substantial performance gains across several non-English languages.
Large Vocabulary Size Improves Large Language Models
Jun 24, 2024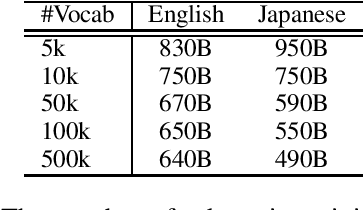
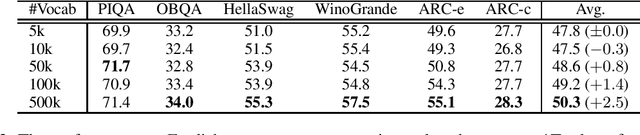
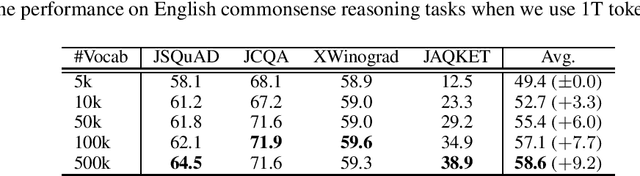

This paper empirically investigates the relationship between subword vocabulary size and the performance of large language models (LLMs) to provide insights on how to define the vocabulary size. Experimental results show that larger vocabulary sizes lead to better performance in LLMs. Moreover, we consider a continual training scenario where a pre-trained language model is trained on a different target language. We introduce a simple method to use a new vocabulary instead of the pre-defined one. We show that using the new vocabulary outperforms the model with the vocabulary used in pre-training.
Spike No More: Stabilizing the Pre-training of Large Language Models
Dec 28, 2023



The loss spike often occurs during pre-training of a large language model. The spikes degrade the performance of a large language model, and sometimes ruin the pre-training. Since the pre-training needs a vast computational budget, we should avoid such spikes. To investigate a cause of loss spikes, we focus on gradients of internal layers in this study. Through theoretical analyses, we introduce two causes of the exploding gradients, and provide requirements to prevent the explosion. In addition, we introduce the combination of the initialization method and a simple modification to embeddings as a method to satisfy the requirements. We conduct various experiments to verify our theoretical analyses empirically. Experimental results indicate that the combination is effective in preventing spikes during pre-training.
On Layer Normalizations and Residual Connections in Transformers
Jun 01, 2022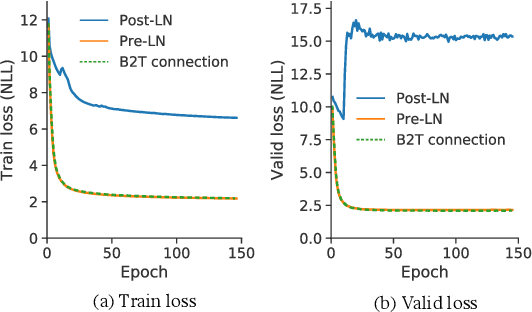
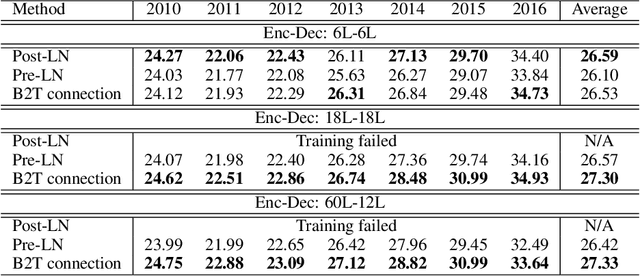
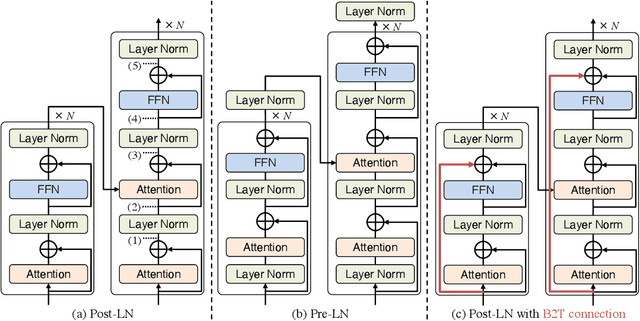
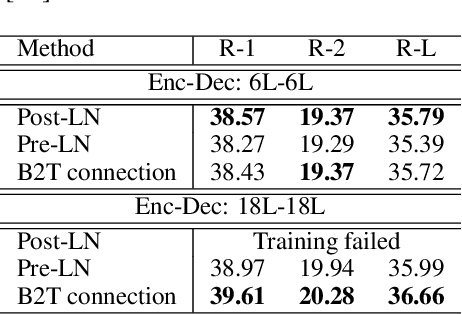
In the perspective of a layer normalization (LN) position, the architecture of Transformers can be categorized into two types: Post-LN and Pre-LN. Recent Transformers prefer to select Pre-LN because the training in Post-LN with deep Transformers, e.g., ten or more layers, often becomes unstable, resulting in useless models. However, in contrast, Post-LN has also consistently achieved better performance than Pre-LN in relatively shallow Transformers, e.g., six or fewer layers. This study first investigates the reason for these discrepant observations empirically and theoretically and discovers 1, the LN in Post-LN is the source of the vanishing gradient problem that mainly leads the unstable training whereas Pre-LN prevents it, and 2, Post-LN tends to preserve larger gradient norms in higher layers during the back-propagation that may lead an effective training. Exploiting the new findings, we propose a method that can equip both higher stability and effective training by a simple modification from Post-LN. We conduct experiments on a wide range of text generation tasks and demonstrate that our method outperforms Pre-LN, and stable training regardless of the shallow or deep layer settings.
Diverse Lottery Tickets Boost Ensemble from a Single Pretrained Model
May 24, 2022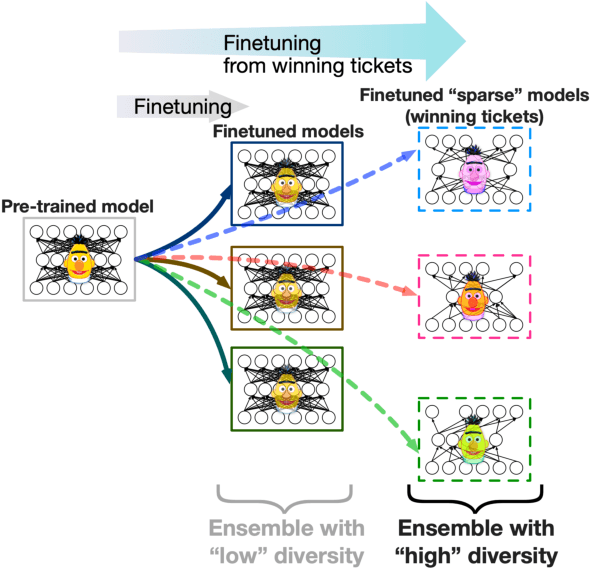
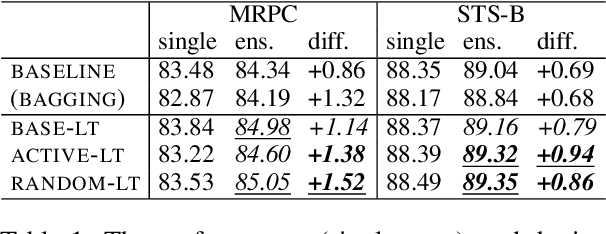
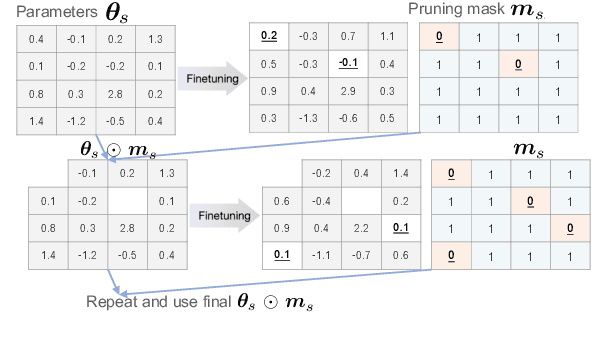
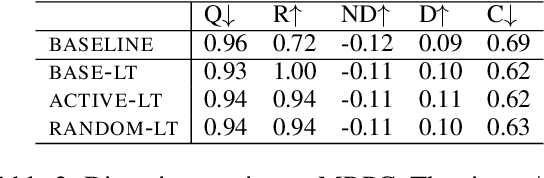
Ensembling is a popular method used to improve performance as a last resort. However, ensembling multiple models finetuned from a single pretrained model has been not very effective; this could be due to the lack of diversity among ensemble members. This paper proposes Multi-Ticket Ensemble, which finetunes different subnetworks of a single pretrained model and ensembles them. We empirically demonstrated that winning-ticket subnetworks produced more diverse predictions than dense networks, and their ensemble outperformed the standard ensemble on some tasks.
SHAPE: Shifted Absolute Position Embedding for Transformers
Sep 13, 2021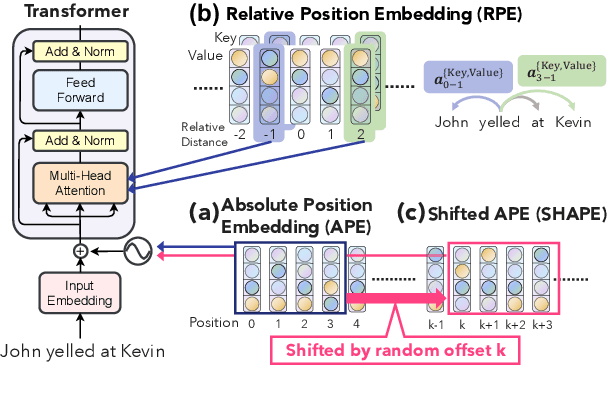
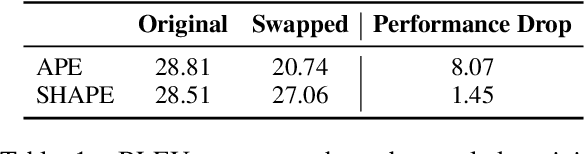
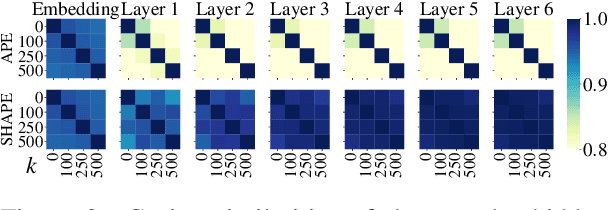
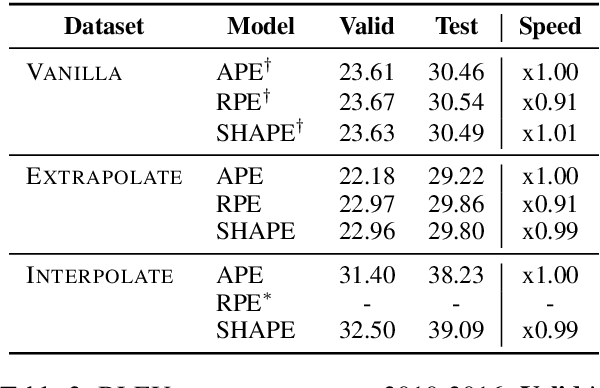
Position representation is crucial for building position-aware representations in Transformers. Existing position representations suffer from a lack of generalization to test data with unseen lengths or high computational cost. We investigate shifted absolute position embedding (SHAPE) to address both issues. The basic idea of SHAPE is to achieve shift invariance, which is a key property of recent successful position representations, by randomly shifting absolute positions during training. We demonstrate that SHAPE is empirically comparable to its counterpart while being simpler and faster.
Pseudo Zero Pronoun Resolution Improves Zero Anaphora Resolution
Apr 15, 2021

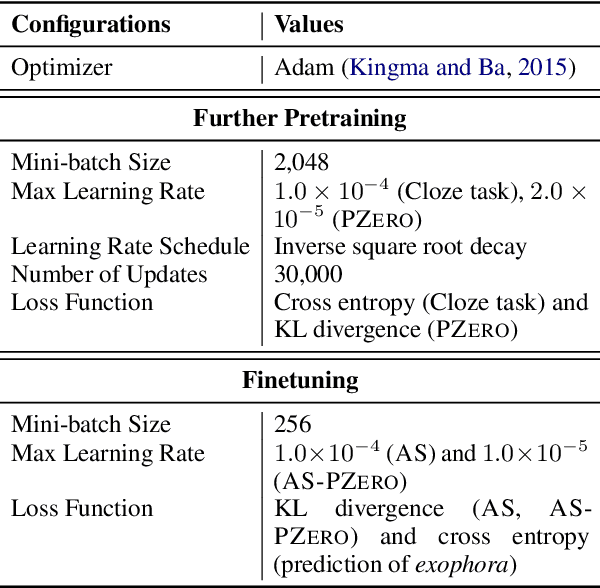
The use of pretrained masked language models (MLMs) has drastically improved the performance of zero anaphora resolution (ZAR). We further expand this approach with a novel pretraining task and finetuning method for Japanese ZAR. Our pretraining task aims to acquire anaphoric relational knowledge necessary for ZAR from a large-scale raw corpus. The ZAR model is finetuned in the same manner as pretraining. Our experiments show that combining the proposed methods surpasses previous state-of-the-art performance with large margins, providing insight on the remaining challenges.
Lessons on Parameter Sharing across Layers in Transformers
Apr 13, 2021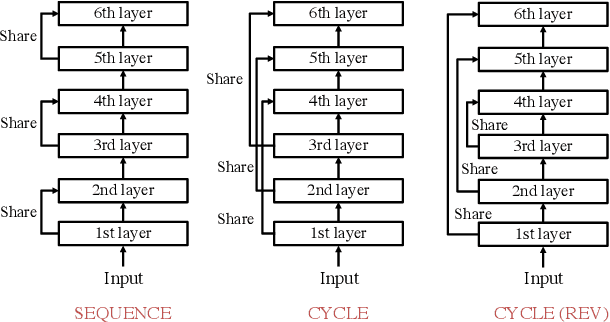
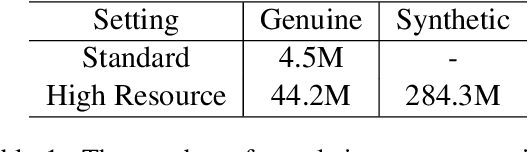

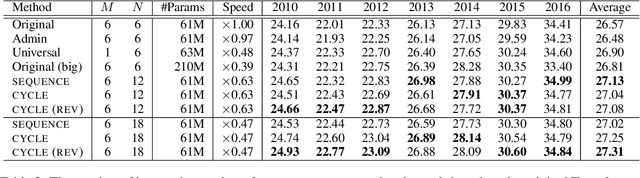
We propose a parameter sharing method for Transformers (Vaswani et al., 2017). The proposed approach relaxes a widely used technique, which shares parameters for one layer with all layers such as Universal Transformers (Dehghani et al., 2019), to increase the efficiency in the computational time. We propose three strategies: Sequence, Cycle, and Cycle (rev) to assign parameters to each layer. Experimental results show that the proposed strategies are efficient in the parameter size and computational time. Moreover, we indicate that the proposed strategies are also effective in the configuration where we use many training data such as the recent WMT competition.