 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePseudo Zero Pronoun Resolution Improves Zero Anaphora Resolution
Apr 15, 2021
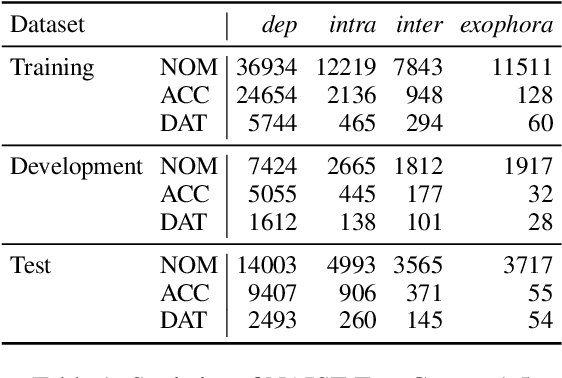

The use of pretrained masked language models (MLMs) has drastically improved the performance of zero anaphora resolution (ZAR). We further expand this approach with a novel pretraining task and finetuning method for Japanese ZAR. Our pretraining task aims to acquire anaphoric relational knowledge necessary for ZAR from a large-scale raw corpus. The ZAR model is finetuned in the same manner as pretraining. Our experiments show that combining the proposed methods surpasses previous state-of-the-art performance with large margins, providing insight on the remaining challenges.
An Empirical Study of Contextual Data Augmentation for Japanese Zero Anaphora Resolution
Nov 04, 2020
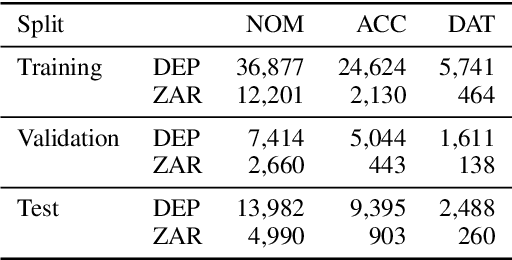
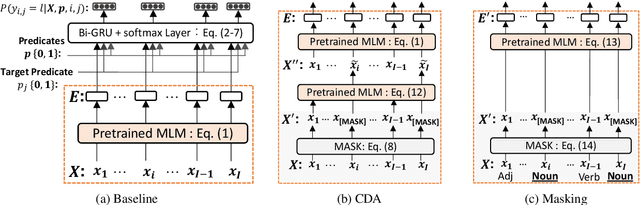
One critical issue of zero anaphora resolution (ZAR) is the scarcity of labeled data. This study explores how effectively this problem can be alleviated by data augmentation. We adopt a state-of-the-art data augmentation method, called the contextual data augmentation (CDA), that generates labeled training instances using a pretrained language model. The CDA has been reported to work well for several other natural language processing tasks, including text classification and machine translation. This study addresses two underexplored issues on CDA, that is, how to reduce the computational cost of data augmentation and how to ensure the quality of the generated data. We also propose two methods to adapt CDA to ZAR: [MASK]-based augmentation and linguistically-controlled masking. Consequently, the experimental results on Japanese ZAR show that our methods contribute to both the accuracy gain and the computation cost reduction. Our closer analysis reveals that the proposed method can improve the quality of the augmented training data when compared to the conventional CDA.
Instance-Based Learning of Span Representations: A Case Study through Named Entity Recognition
Apr 29, 2020


Interpretable rationales for model predictions play a critical role in practical applications. In this study, we develop models possessing interpretable inference process for structured prediction. Specifically, we present a method of instance-based learning that learns similarities between spans. At inference time, each span is assigned a class label based on its similar spans in the training set, where it is easy to understand how much each training instance contributes to the predictions. Through empirical analysis on named entity recognition, we demonstrate that our method enables to build models that have high interpretability without sacrificing performance.