Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePseudo Zero Pronoun Resolution Improves Zero Anaphora Resolution
Paper and Code

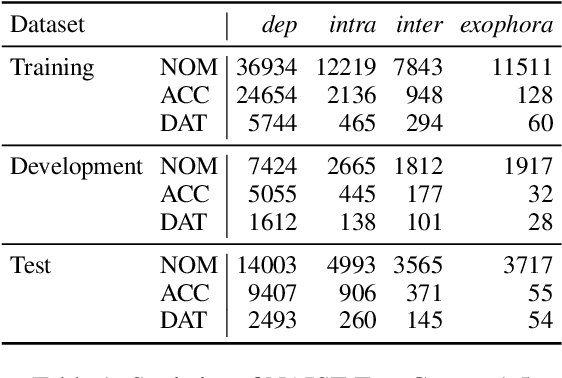

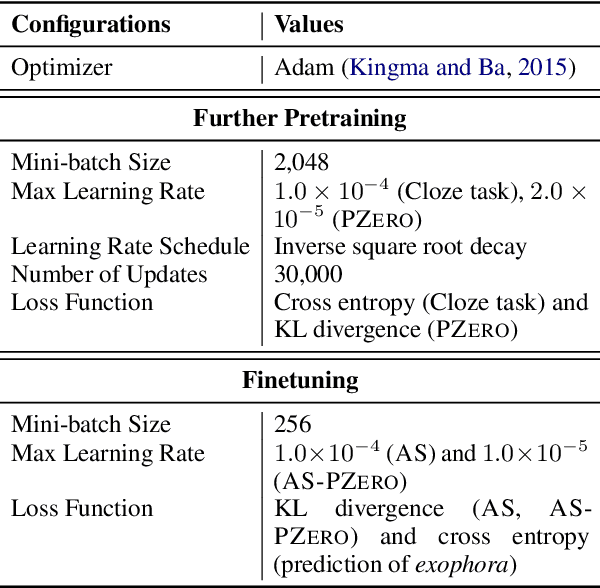
The use of pretrained masked language models (MLMs) has drastically improved the performance of zero anaphora resolution (ZAR). We further expand this approach with a novel pretraining task and finetuning method for Japanese ZAR. Our pretraining task aims to acquire anaphoric relational knowledge necessary for ZAR from a large-scale raw corpus. The ZAR model is finetuned in the same manner as pretraining. Our experiments show that combining the proposed methods surpasses previous state-of-the-art performance with large margins, providing insight on the remaining challenges.
* 14 pages
View paper on