 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTell Me Who Your Students Are: GPT Can Generate Valid Multiple-Choice Questions When Students' (Mis)Understanding Is Hinted
May 09, 2025The primary goal of this study is to develop and evaluate an innovative prompting technique, AnaQuest, for generating multiple-choice questions (MCQs) using a pre-trained large language model. In AnaQuest, the choice items are sentence-level assertions about complex concepts. The technique integrates formative and summative assessments. In the formative phase, students answer open-ended questions for target concepts in free text. For summative assessment, AnaQuest analyzes these responses to generate both correct and incorrect assertions. To evaluate the validity of the generated MCQs, Item Response Theory (IRT) was applied to compare item characteristics between MCQs generated by AnaQuest, a baseline ChatGPT prompt, and human-crafted items. An empirical study found that expert instructors rated MCQs generated by both AI models to be as valid as those created by human instructors. However, IRT-based analysis revealed that AnaQuest-generated questions - particularly those with incorrect assertions (foils) - more closely resembled human-crafted items in terms of difficulty and discrimination than those produced by ChatGPT.
Automatic Feedback Generation for Short Answer Questions using Answer Diagnostic Graphs
Jan 27, 2025
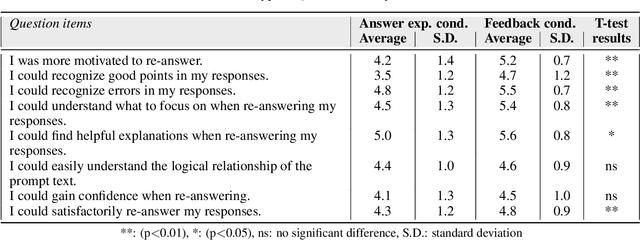
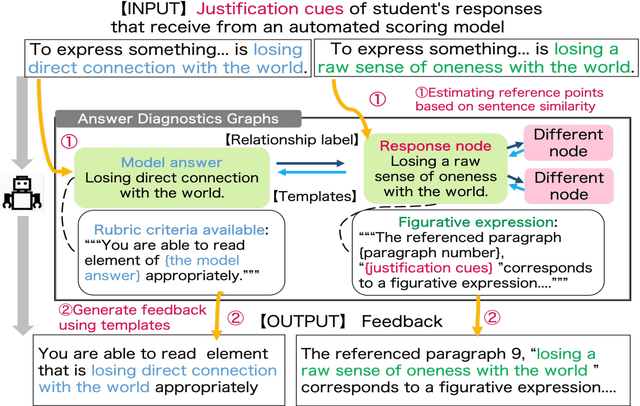
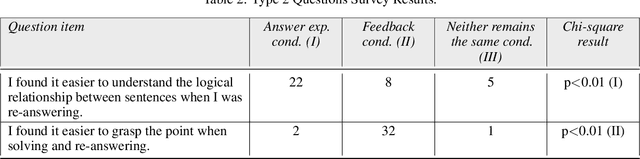
Short-reading comprehension questions help students understand text structure but lack effective feedback. Students struggle to identify and correct errors, while manual feedback creation is labor-intensive. This highlights the need for automated feedback linking responses to a scoring rubric for deeper comprehension. Despite advances in Natural Language Processing (NLP), research has focused on automatic grading, with limited work on feedback generation. To address this, we propose a system that generates feedback for student responses. Our contributions are twofold. First, we introduce the first system for feedback on short-answer reading comprehension. These answers are derived from the text, requiring structural understanding. We propose an "answer diagnosis graph," integrating the text's logical structure with feedback templates. Using this graph and NLP techniques, we estimate students' comprehension and generate targeted feedback. Second, we evaluate our feedback through an experiment with Japanese high school students (n=39). They answered two 70-80 word questions and were divided into two groups with minimal academic differences. One received a model answer, the other system-generated feedback. Both re-answered the questions, and we compared score changes. A questionnaire assessed perceptions and motivation. Results showed no significant score improvement between groups, but system-generated feedback helped students identify errors and key points in the text. It also significantly increased motivation. However, further refinement is needed to enhance text structure understanding.
Reducing the Cost: Cross-Prompt Pre-Finetuning for Short Answer Scoring
Aug 26, 2024Automated Short Answer Scoring (SAS) is the task of automatically scoring a given input to a prompt based on rubrics and reference answers. Although SAS is useful in real-world applications, both rubrics and reference answers differ between prompts, thus requiring a need to acquire new data and train a model for each new prompt. Such requirements are costly, especially for schools and online courses where resources are limited and only a few prompts are used. In this work, we attempt to reduce this cost through a two-phase approach: train a model on existing rubrics and answers with gold score signals and finetune it on a new prompt. Specifically, given that scoring rubrics and reference answers differ for each prompt, we utilize key phrases, or representative expressions that the answer should contain to increase scores, and train a SAS model to learn the relationship between key phrases and answers using already annotated prompts (i.e., cross-prompts). Our experimental results show that finetuning on existing cross-prompt data with key phrases significantly improves scoring accuracy, especially when the training data is limited. Finally, our extensive analysis shows that it is crucial to design the model so that it can learn the task's general property.
* This is the draft submitted to AIED 2023. For the latest version, please visit: https://link.springer.com/chapter/10.1007/978-3-031-36272-9_7
Japanese-English Sentence Translation Exercises Dataset for Automatic Grading
Mar 06, 2024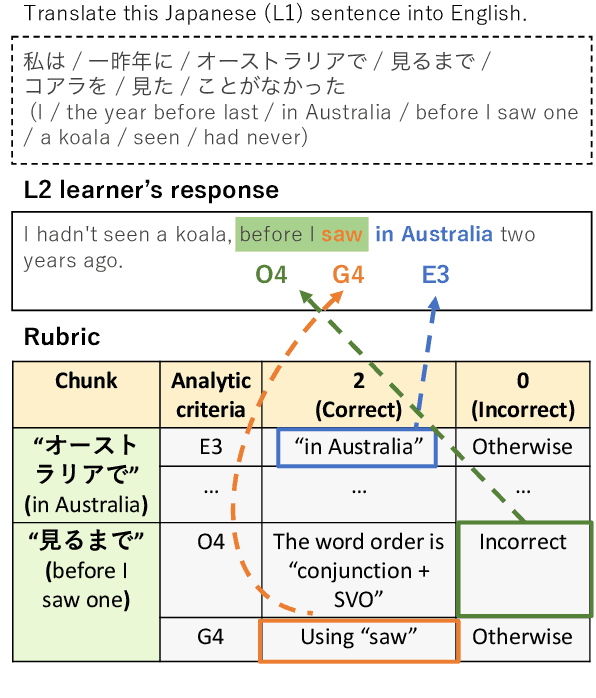
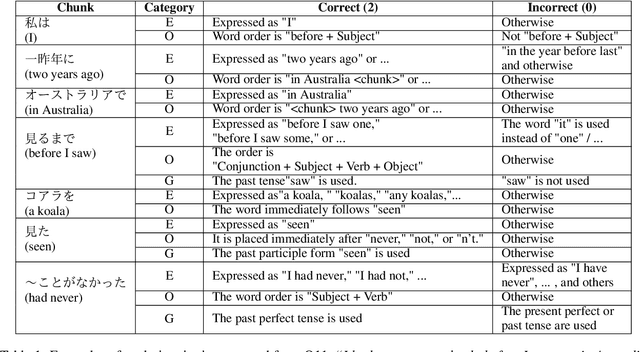
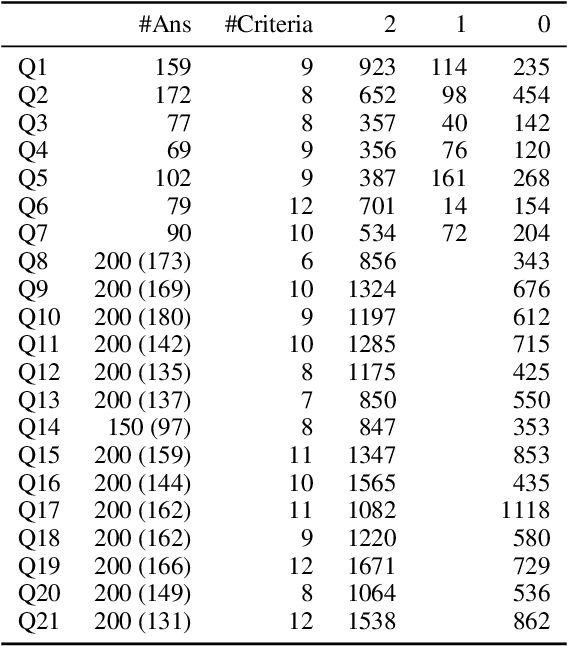

This paper proposes the task of automatic assessment of Sentence Translation Exercises (STEs), that have been used in the early stage of L2 language learning. We formalize the task as grading student responses for each rubric criterion pre-specified by the educators. We then create a dataset for STE between Japanese and English including 21 questions, along with a total of 3, 498 student responses (167 on average). The answer responses were collected from students and crowd workers. Using this dataset, we demonstrate the performance of baselines including finetuned BERT and GPT models with few-shot in-context learning. Experimental results show that the baseline model with finetuned BERT was able to classify correct responses with approximately 90% in F1, but only less than 80% for incorrect responses. Furthermore, the GPT models with few-shot learning show poorer results than finetuned BERT, indicating that our newly proposed task presents a challenging issue, even for the stateof-the-art large language models.
Balancing Cost and Quality: An Exploration of Human-in-the-loop Frameworks for Automated Short Answer Scoring
Jun 16, 2022

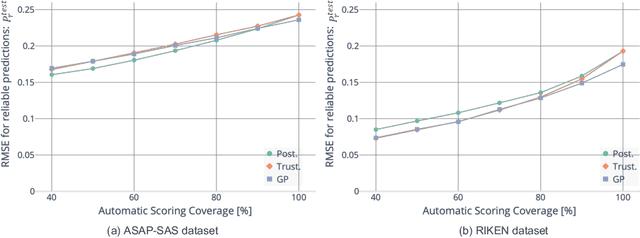
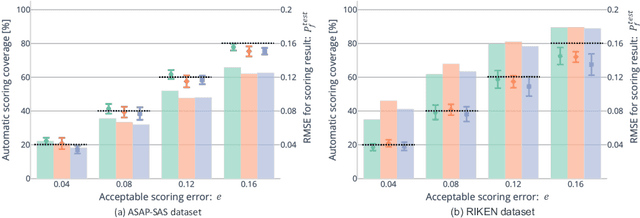
Short answer scoring (SAS) is the task of grading short text written by a learner. In recent years, deep-learning-based approaches have substantially improved the performance of SAS models, but how to guarantee high-quality predictions still remains a critical issue when applying such models to the education field. Towards guaranteeing high-quality predictions, we present the first study of exploring the use of human-in-the-loop framework for minimizing the grading cost while guaranteeing the grading quality by allowing a SAS model to share the grading task with a human grader. Specifically, by introducing a confidence estimation method for indicating the reliability of the model predictions, one can guarantee the scoring quality by utilizing only predictions with high reliability for the scoring results and casting predictions with low reliability to human graders. In our experiments, we investigate the feasibility of the proposed framework using multiple confidence estimation methods and multiple SAS datasets. We find that our human-in-the-loop framework allows automatic scoring models and human graders to achieve the target scoring quality.
Pseudo Zero Pronoun Resolution Improves Zero Anaphora Resolution
Apr 15, 2021
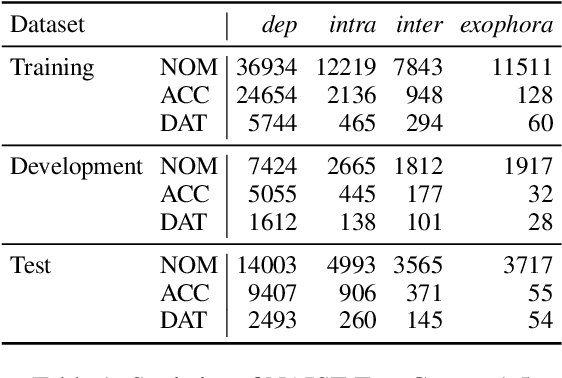

The use of pretrained masked language models (MLMs) has drastically improved the performance of zero anaphora resolution (ZAR). We further expand this approach with a novel pretraining task and finetuning method for Japanese ZAR. Our pretraining task aims to acquire anaphoric relational knowledge necessary for ZAR from a large-scale raw corpus. The ZAR model is finetuned in the same manner as pretraining. Our experiments show that combining the proposed methods surpasses previous state-of-the-art performance with large margins, providing insight on the remaining challenges.
An Empirical Study of Contextual Data Augmentation for Japanese Zero Anaphora Resolution
Nov 04, 2020
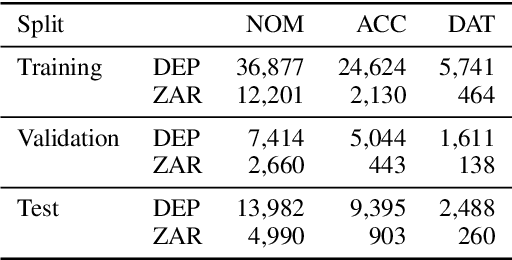
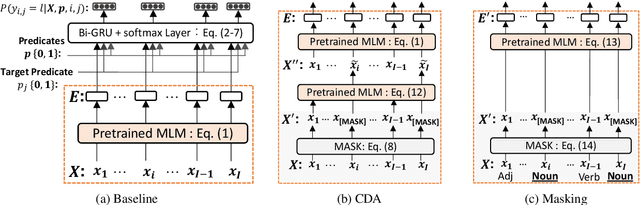
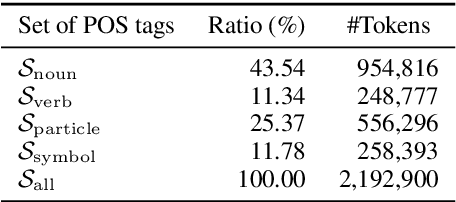
One critical issue of zero anaphora resolution (ZAR) is the scarcity of labeled data. This study explores how effectively this problem can be alleviated by data augmentation. We adopt a state-of-the-art data augmentation method, called the contextual data augmentation (CDA), that generates labeled training instances using a pretrained language model. The CDA has been reported to work well for several other natural language processing tasks, including text classification and machine translation. This study addresses two underexplored issues on CDA, that is, how to reduce the computational cost of data augmentation and how to ensure the quality of the generated data. We also propose two methods to adapt CDA to ZAR: [MASK]-based augmentation and linguistically-controlled masking. Consequently, the experimental results on Japanese ZAR show that our methods contribute to both the accuracy gain and the computation cost reduction. Our closer analysis reveals that the proposed method can improve the quality of the augmented training data when compared to the conventional CDA.
Distance-Free Modeling of Multi-Predicate Interactions in End-to-End Japanese Predicate-Argument Structure Analysis
Jun 12, 2018
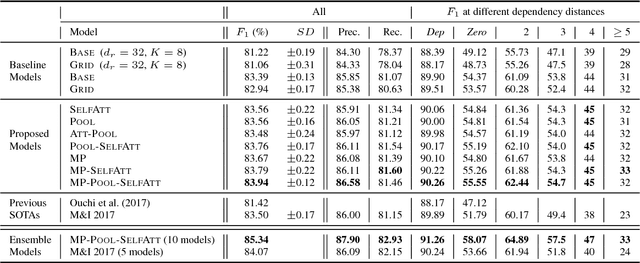

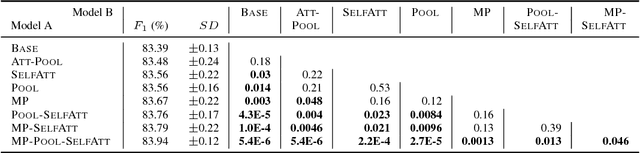
Capturing interactions among multiple predicate-argument structures (PASs) is a crucial issue in the task of analyzing PAS in Japanese. In this paper, we propose new Japanese PAS analysis models that integrate the label prediction information of arguments in multiple PASs by extending the input and last layers of a standard deep bidirectional recurrent neural network (bi-RNN) model. In these models, using the mechanisms of pooling and attention, we aim to directly capture the potential interactions among multiple PASs, without being disturbed by the word order and distance. Our experiments show that the proposed models improve the prediction accuracy specifically for cases where the predicate and argument are in an indirect dependency relation and achieve a new state of the art in the overall $F_1$ on a standard benchmark corpus.
Revisiting the Design Issues of Local Models for Japanese Predicate-Argument Structure Analysis
Oct 12, 2017



The research trend in Japanese predicate-argument structure (PAS) analysis is shifting from pointwise prediction models with local features to global models designed to search for globally optimal solutions. However, the existing global models tend to employ only relatively simple local features; therefore, the overall performance gains are rather limited. The importance of designing a local model is demonstrated in this study by showing that the performance of a sophisticated local model can be considerably improved with recent feature embedding methods and a feature combination learning based on a neural network, outperforming the state-of-the-art global models in $F_1$ on a common benchmark dataset.