 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Feedback Generation for Short Answer Questions using Answer Diagnostic Graphs
Jan 27, 2025
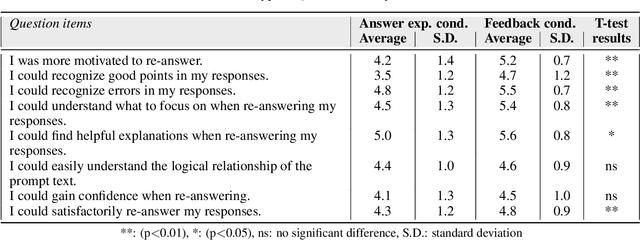
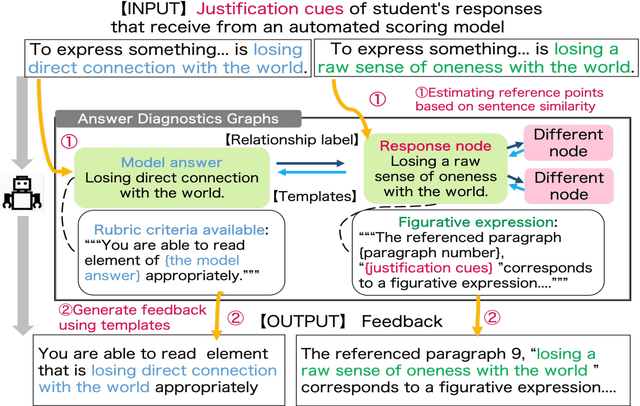
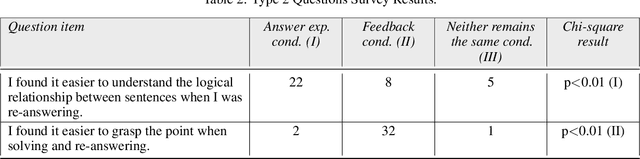
Short-reading comprehension questions help students understand text structure but lack effective feedback. Students struggle to identify and correct errors, while manual feedback creation is labor-intensive. This highlights the need for automated feedback linking responses to a scoring rubric for deeper comprehension. Despite advances in Natural Language Processing (NLP), research has focused on automatic grading, with limited work on feedback generation. To address this, we propose a system that generates feedback for student responses. Our contributions are twofold. First, we introduce the first system for feedback on short-answer reading comprehension. These answers are derived from the text, requiring structural understanding. We propose an "answer diagnosis graph," integrating the text's logical structure with feedback templates. Using this graph and NLP techniques, we estimate students' comprehension and generate targeted feedback. Second, we evaluate our feedback through an experiment with Japanese high school students (n=39). They answered two 70-80 word questions and were divided into two groups with minimal academic differences. One received a model answer, the other system-generated feedback. Both re-answered the questions, and we compared score changes. A questionnaire assessed perceptions and motivation. Results showed no significant score improvement between groups, but system-generated feedback helped students identify errors and key points in the text. It also significantly increased motivation. However, further refinement is needed to enhance text structure understanding.
Japanese-English Sentence Translation Exercises Dataset for Automatic Grading
Mar 06, 2024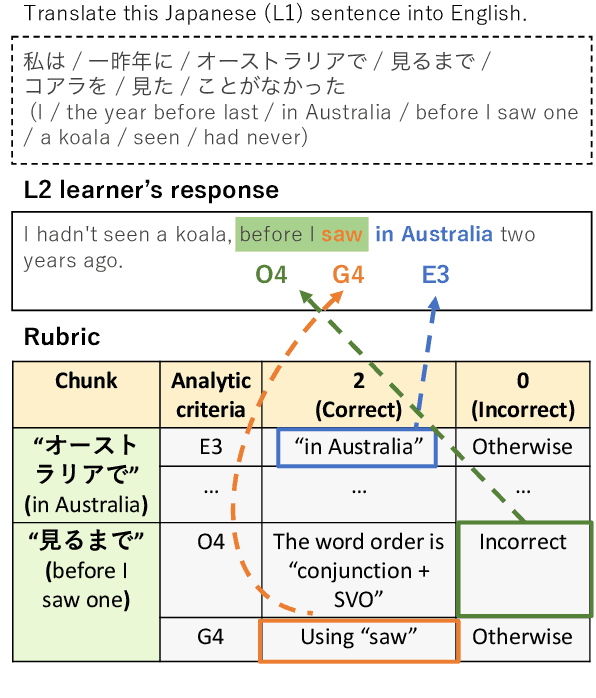
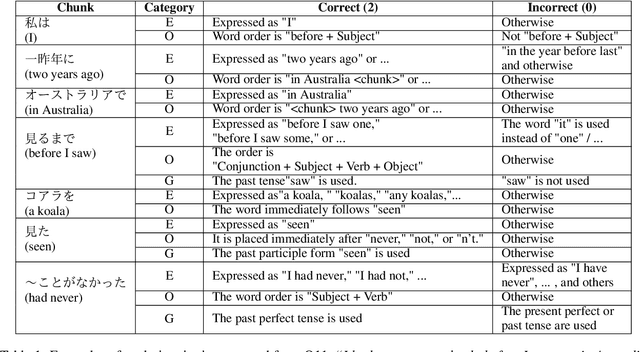
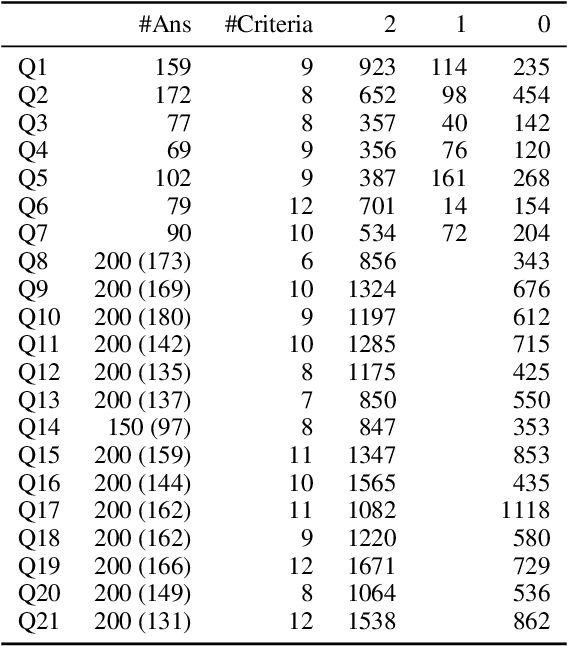

This paper proposes the task of automatic assessment of Sentence Translation Exercises (STEs), that have been used in the early stage of L2 language learning. We formalize the task as grading student responses for each rubric criterion pre-specified by the educators. We then create a dataset for STE between Japanese and English including 21 questions, along with a total of 3, 498 student responses (167 on average). The answer responses were collected from students and crowd workers. Using this dataset, we demonstrate the performance of baselines including finetuned BERT and GPT models with few-shot in-context learning. Experimental results show that the baseline model with finetuned BERT was able to classify correct responses with approximately 90% in F1, but only less than 80% for incorrect responses. Furthermore, the GPT models with few-shot learning show poorer results than finetuned BERT, indicating that our newly proposed task presents a challenging issue, even for the stateof-the-art large language models.