 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAC/DC: LLM-based Audio Comprehension via Dialogue Continuation
Jun 12, 2025We propose an instruction-following audio comprehension model that leverages the dialogue continuation ability of large language models (LLMs). Instead of directly generating target captions in training data, the proposed method trains a model to produce responses as if the input caption triggered a dialogue. This dialogue continuation training mitigates the caption variation problem. Learning to continue a dialogue effectively captures the caption's meaning beyond its surface-level words. As a result, our model enables zero-shot instruction-following capability without multitask instruction tuning, even trained solely on audio captioning datasets. Experiments on AudioCaps, WavCaps, and Clotho datasets with AudioBench audio-scene question-answering tests demonstrate our model's ability to follow various unseen instructions.
OWSM-Biasing: Contextualizing Open Whisper-Style Speech Models for Automatic Speech Recognition with Dynamic Vocabulary
Jun 11, 2025



Speech foundation models (SFMs), such as Open Whisper-Style Speech Models (OWSM), are trained on massive datasets to achieve accurate automatic speech recognition. However, even SFMs struggle to accurately recognize rare and unseen words. While contextual biasing (CB) is a promising approach to improve recognition of such words, most CB methods are trained from scratch, resulting in lower performance than SFMs due to the lack of pre-trained knowledge. This paper integrates an existing CB method with OWSM v3.1 while freezing its pre-trained parameters. By leveraging the knowledge embedded in SFMs, the proposed method enables effective CB while preserving the advantages of SFMs, even with a small dataset. Experimental results show that the proposed method improves the biasing word error rate (B-WER) by 11.6 points, resulting in a 0.9 point improvement in the overall WER while reducing the real-time factor by 7.5% compared to the non-biasing baseline on the LibriSpeech 100 test-clean set.
Reducing the Cost: Cross-Prompt Pre-Finetuning for Short Answer Scoring
Aug 26, 2024Automated Short Answer Scoring (SAS) is the task of automatically scoring a given input to a prompt based on rubrics and reference answers. Although SAS is useful in real-world applications, both rubrics and reference answers differ between prompts, thus requiring a need to acquire new data and train a model for each new prompt. Such requirements are costly, especially for schools and online courses where resources are limited and only a few prompts are used. In this work, we attempt to reduce this cost through a two-phase approach: train a model on existing rubrics and answers with gold score signals and finetune it on a new prompt. Specifically, given that scoring rubrics and reference answers differ for each prompt, we utilize key phrases, or representative expressions that the answer should contain to increase scores, and train a SAS model to learn the relationship between key phrases and answers using already annotated prompts (i.e., cross-prompts). Our experimental results show that finetuning on existing cross-prompt data with key phrases significantly improves scoring accuracy, especially when the training data is limited. Finally, our extensive analysis shows that it is crucial to design the model so that it can learn the task's general property.
* This is the draft submitted to AIED 2023. For the latest version, please visit: https://link.springer.com/chapter/10.1007/978-3-031-36272-9_7
Developing Interactive Tourism Planning: A Dialogue Robot System Powered by a Large Language Model
Dec 22, 2023In recent years, large language models (LLMs) have rapidly proliferated and have been utilized in various tasks, including research in dialogue systems. We aimed to construct a system that not only leverages the flexible conversational abilities of LLMs but also their advanced planning capabilities to reduce the speaking load on human interlocutors and efficiently plan trips. Furthermore, we propose a method that divides the complex task of a travel agency into multiple subtasks, managing each as a separate phase to effectively accomplish the task. Our proposed system confirmed a certain level of success by achieving fourth place in the Dialogue Robot Competition 2023 preliminaries rounds. We report on the challenges identified through the competition.
Dialogue Systems Can Generate Appropriate Responses without the Use of Question Marks? -- Investigation of the Effects of Question Marks on Dialogue Systems
Aug 07, 2023



When individuals engage in spoken discourse, various phenomena can be observed that differ from those that are apparent in text-based conversation. While written communication commonly uses a question mark to denote a query, in spoken discourse, queries are frequently indicated by a rising intonation at the end of a sentence. However, numerous speech recognition engines do not append a question mark to recognized queries, presenting a challenge when creating a spoken dialogue system. Specifically, the absence of a question mark at the end of a sentence can impede the generation of appropriate responses to queries in spoken dialogue systems. Hence, we investigate the impact of question marks on dialogue systems, with the results showing that they have a significant impact. Moreover, we analyze specific examples in an effort to determine which types of utterances have the impact on dialogue systems.
Tourist Guidance Robot Based on HyperCLOVA
Oct 19, 2022



This paper describes our system submitted to Dialogue Robot Competition 2022. Our proposed system is a combined model of rule-based and generation-based dialog systems. The system utilizes HyperCLOVA, a Japanese foundation model, not only to generate responses but also summarization, search information, etc. We also used our original speech recognition system, which was fine-tuned for this dialog task. As a result, our system ranked second in the preliminary round and moved on to the finals.
Balancing Cost and Quality: An Exploration of Human-in-the-loop Frameworks for Automated Short Answer Scoring
Jun 16, 2022

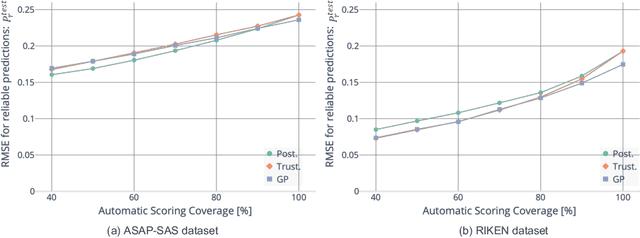
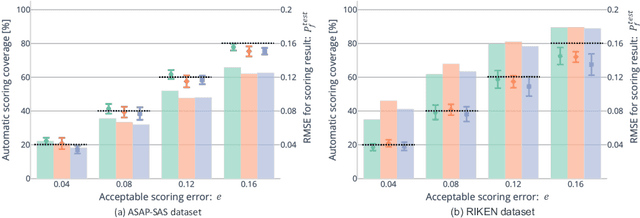
Short answer scoring (SAS) is the task of grading short text written by a learner. In recent years, deep-learning-based approaches have substantially improved the performance of SAS models, but how to guarantee high-quality predictions still remains a critical issue when applying such models to the education field. Towards guaranteeing high-quality predictions, we present the first study of exploring the use of human-in-the-loop framework for minimizing the grading cost while guaranteeing the grading quality by allowing a SAS model to share the grading task with a human grader. Specifically, by introducing a confidence estimation method for indicating the reliability of the model predictions, one can guarantee the scoring quality by utilizing only predictions with high reliability for the scoring results and casting predictions with low reliability to human graders. In our experiments, we investigate the feasibility of the proposed framework using multiple confidence estimation methods and multiple SAS datasets. We find that our human-in-the-loop framework allows automatic scoring models and human graders to achieve the target scoring quality.
Towards Automated Document Revision: Grammatical Error Correction, Fluency Edits, and Beyond
May 23, 2022


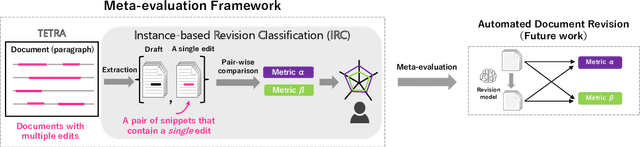
Natural language processing technology has rapidly improved automated grammatical error correction tasks, and the community begins to explore document-level revision as one of the next challenges. To go beyond sentence-level automated grammatical error correction to NLP-based document-level revision assistant, there are two major obstacles: (1) there are few public corpora with document-level revisions being annotated by professional editors, and (2) it is not feasible to elicit all possible references and evaluate the quality of revision with such references because there are infinite possibilities of revision. This paper tackles these challenges. First, we introduce a new document-revision corpus, TETRA, where professional editors revised academic papers sampled from the ACL anthology which contain few trivial grammatical errors that enable us to focus more on document- and paragraph-level edits such as coherence and consistency. Second, we explore reference-less and interpretable methods for meta-evaluation that can detect quality improvements by document revision. We show the uniqueness of TETRA compared with existing document revision corpora and demonstrate that a fine-tuned pre-trained language model can discriminate the quality of documents after revision even when the difference is subtle. This promising result will encourage the community to further explore automated document revision models and metrics in future.
An Empirical Study of Incorporating Pseudo Data into Grammatical Error Correction
Sep 02, 2019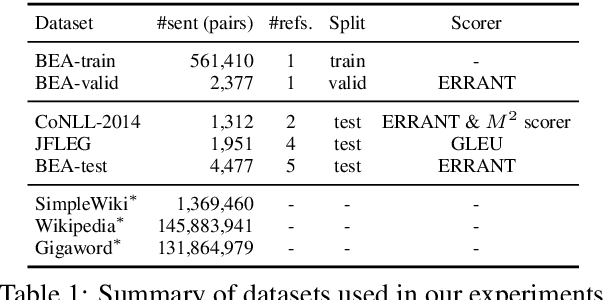
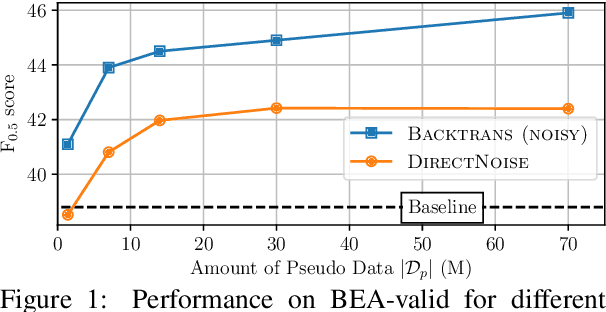
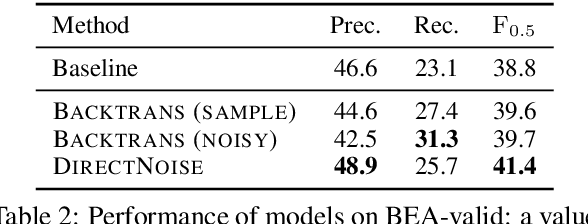
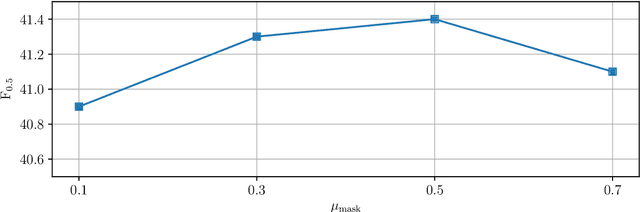
The incorporation of pseudo data in the training of grammatical error correction models has been one of the main factors in improving the performance of such models. However, consensus is lacking on experimental configurations, namely, choosing how the pseudo data should be generated or used. In this study, these choices are investigated through extensive experiments, and state-of-the-art performance is achieved on the CoNLL-2014 test set ($F_{0.5}=65.0$) and the official test set of the BEA-2019 shared task ($F_{0.5}=70.2$) without making any modifications to the model architecture.
Cross-Corpora Evaluation and Analysis of Grammatical Error Correction Models --- Is Single-Corpus Evaluation Enough?
Apr 05, 2019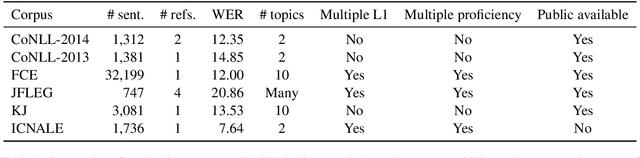



This study explores the necessity of performing cross-corpora evaluation for grammatical error correction (GEC) models. GEC models have been previously evaluated based on a single commonly applied corpus: the CoNLL-2014 benchmark. However, the evaluation remains incomplete because the task difficulty varies depending on the test corpus and conditions such as the proficiency levels of the writers and essay topics. To overcome this limitation, we evaluate the performance of several GEC models, including NMT-based (LSTM, CNN, and transformer) and an SMT-based model, against various learner corpora (CoNLL-2013, CoNLL-2014, FCE, JFLEG, ICNALE, and KJ). Evaluation results reveal that the models' rankings considerably vary depending on the corpus, indicating that single-corpus evaluation is insufficient for GEC models.