 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolarization of Autonomous Generative AI Agents Under Echo Chambers
Feb 19, 2024Online social networks often create echo chambers where people only hear opinions reinforcing their beliefs. An echo chamber often generates polarization, leading to conflicts caused by people with radical opinions, such as the January 6, 2021, attack on the US Capitol. The echo chamber has been viewed as a human-specific problem, but this implicit assumption is becoming less reasonable as large language models, such as ChatGPT, acquire social abilities. In response to this situation, we investigated the potential for polarization to occur among a group of autonomous AI agents based on generative language models in an echo chamber environment. We had AI agents discuss specific topics and analyzed how the group's opinions changed as the discussion progressed. As a result, we found that the group of agents based on ChatGPT tended to become polarized in echo chamber environments. The analysis of opinion transitions shows that this result is caused by ChatGPT's high prompt understanding ability to update its opinion by considering its own and surrounding agents' opinions. We conducted additional experiments to investigate under what specific conditions AI agents tended to polarize. As a result, we identified factors that strongly influence polarization, such as the agent's persona. These factors should be monitored to prevent the polarization of AI agents.
Developing Interactive Tourism Planning: A Dialogue Robot System Powered by a Large Language Model
Dec 22, 2023In recent years, large language models (LLMs) have rapidly proliferated and have been utilized in various tasks, including research in dialogue systems. We aimed to construct a system that not only leverages the flexible conversational abilities of LLMs but also their advanced planning capabilities to reduce the speaking load on human interlocutors and efficiently plan trips. Furthermore, we propose a method that divides the complex task of a travel agency into multiple subtasks, managing each as a separate phase to effectively accomplish the task. Our proposed system confirmed a certain level of success by achieving fourth place in the Dialogue Robot Competition 2023 preliminaries rounds. We report on the challenges identified through the competition.
Dialogue Systems Can Generate Appropriate Responses without the Use of Question Marks? -- Investigation of the Effects of Question Marks on Dialogue Systems
Aug 07, 2023



When individuals engage in spoken discourse, various phenomena can be observed that differ from those that are apparent in text-based conversation. While written communication commonly uses a question mark to denote a query, in spoken discourse, queries are frequently indicated by a rising intonation at the end of a sentence. However, numerous speech recognition engines do not append a question mark to recognized queries, presenting a challenge when creating a spoken dialogue system. Specifically, the absence of a question mark at the end of a sentence can impede the generation of appropriate responses to queries in spoken dialogue systems. Hence, we investigate the impact of question marks on dialogue systems, with the results showing that they have a significant impact. Moreover, we analyze specific examples in an effort to determine which types of utterances have the impact on dialogue systems.
Tourist Guidance Robot Based on HyperCLOVA
Oct 19, 2022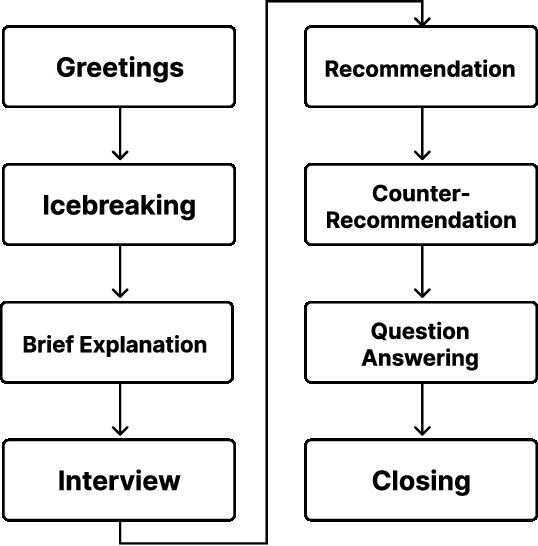



This paper describes our system submitted to Dialogue Robot Competition 2022. Our proposed system is a combined model of rule-based and generation-based dialog systems. The system utilizes HyperCLOVA, a Japanese foundation model, not only to generate responses but also summarization, search information, etc. We also used our original speech recognition system, which was fine-tuned for this dialog task. As a result, our system ranked second in the preliminary round and moved on to the finals.