 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDialogue Systems Can Generate Appropriate Responses without the Use of Question Marks? -- Investigation of the Effects of Question Marks on Dialogue Systems
Aug 07, 2023



When individuals engage in spoken discourse, various phenomena can be observed that differ from those that are apparent in text-based conversation. While written communication commonly uses a question mark to denote a query, in spoken discourse, queries are frequently indicated by a rising intonation at the end of a sentence. However, numerous speech recognition engines do not append a question mark to recognized queries, presenting a challenge when creating a spoken dialogue system. Specifically, the absence of a question mark at the end of a sentence can impede the generation of appropriate responses to queries in spoken dialogue systems. Hence, we investigate the impact of question marks on dialogue systems, with the results showing that they have a significant impact. Moreover, we analyze specific examples in an effort to determine which types of utterances have the impact on dialogue systems.
Tourist Guidance Robot Based on HyperCLOVA
Oct 19, 2022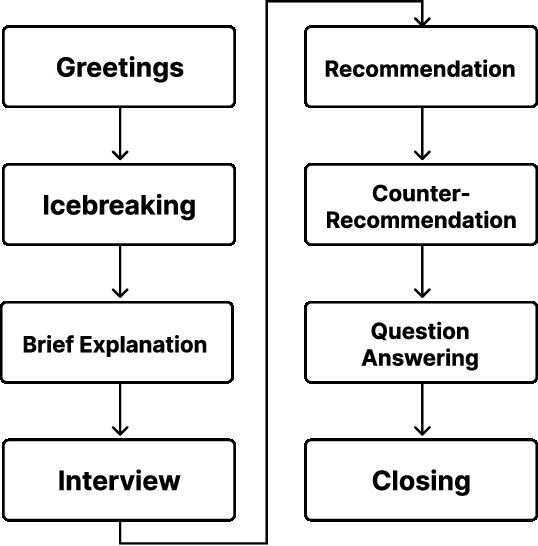



This paper describes our system submitted to Dialogue Robot Competition 2022. Our proposed system is a combined model of rule-based and generation-based dialog systems. The system utilizes HyperCLOVA, a Japanese foundation model, not only to generate responses but also summarization, search information, etc. We also used our original speech recognition system, which was fine-tuned for this dialog task. As a result, our system ranked second in the preliminary round and moved on to the finals.
Generating Repetitions with Appropriate Repeated Words
Jul 03, 2022



A repetition is a response that repeats words in the previous speaker's utterance in a dialogue. Repetitions are essential in communication to build trust with others, as investigated in linguistic studies. In this work, we focus on repetition generation. To the best of our knowledge, this is the first neural approach to address repetition generation. We propose Weighted Label Smoothing, a smoothing method for explicitly learning which words to repeat during fine-tuning, and a repetition scoring method that can output more appropriate repetitions during decoding. We conducted automatic and human evaluations involving applying these methods to the pre-trained language model T5 for generating repetitions. The experimental results indicate that our methods outperformed baselines in both evaluations.