 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeveloping Interactive Tourism Planning: A Dialogue Robot System Powered by a Large Language Model
Dec 22, 2023In recent years, large language models (LLMs) have rapidly proliferated and have been utilized in various tasks, including research in dialogue systems. We aimed to construct a system that not only leverages the flexible conversational abilities of LLMs but also their advanced planning capabilities to reduce the speaking load on human interlocutors and efficiently plan trips. Furthermore, we propose a method that divides the complex task of a travel agency into multiple subtasks, managing each as a separate phase to effectively accomplish the task. Our proposed system confirmed a certain level of success by achieving fourth place in the Dialogue Robot Competition 2023 preliminaries rounds. We report on the challenges identified through the competition.
PHALM: Building a Knowledge Graph from Scratch by Prompting Humans and a Language Model
Oct 11, 2023



Despite the remarkable progress in natural language understanding with pretrained Transformers, neural language models often do not handle commonsense knowledge well. Toward commonsense-aware models, there have been attempts to obtain knowledge, ranging from automatic acquisition to crowdsourcing. However, it is difficult to obtain a high-quality knowledge base at a low cost, especially from scratch. In this paper, we propose PHALM, a method of building a knowledge graph from scratch, by prompting both crowdworkers and a large language model (LLM). We used this method to build a Japanese event knowledge graph and trained Japanese commonsense generation models. Experimental results revealed the acceptability of the built graph and inferences generated by the trained models. We also report the difference in prompting humans and an LLM. Our code, data, and models are available at github.com/nlp-waseda/comet-atomic-ja.
Dialogue Systems Can Generate Appropriate Responses without the Use of Question Marks? -- Investigation of the Effects of Question Marks on Dialogue Systems
Aug 07, 2023



When individuals engage in spoken discourse, various phenomena can be observed that differ from those that are apparent in text-based conversation. While written communication commonly uses a question mark to denote a query, in spoken discourse, queries are frequently indicated by a rising intonation at the end of a sentence. However, numerous speech recognition engines do not append a question mark to recognized queries, presenting a challenge when creating a spoken dialogue system. Specifically, the absence of a question mark at the end of a sentence can impede the generation of appropriate responses to queries in spoken dialogue systems. Hence, we investigate the impact of question marks on dialogue systems, with the results showing that they have a significant impact. Moreover, we analyze specific examples in an effort to determine which types of utterances have the impact on dialogue systems.
Tourist Guidance Robot Based on HyperCLOVA
Oct 19, 2022



This paper describes our system submitted to Dialogue Robot Competition 2022. Our proposed system is a combined model of rule-based and generation-based dialog systems. The system utilizes HyperCLOVA, a Japanese foundation model, not only to generate responses but also summarization, search information, etc. We also used our original speech recognition system, which was fine-tuned for this dialog task. As a result, our system ranked second in the preliminary round and moved on to the finals.
A Linguistic Analysis of Visually Grounded Dialogues Based on Spatial Expressions
Oct 07, 2020
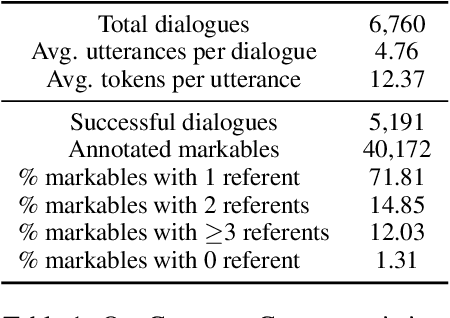
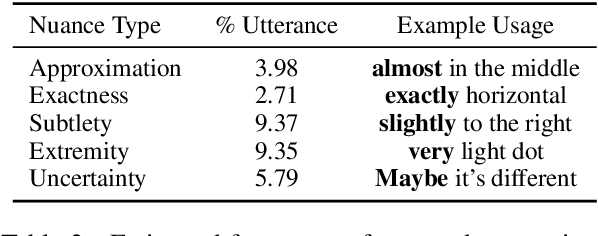
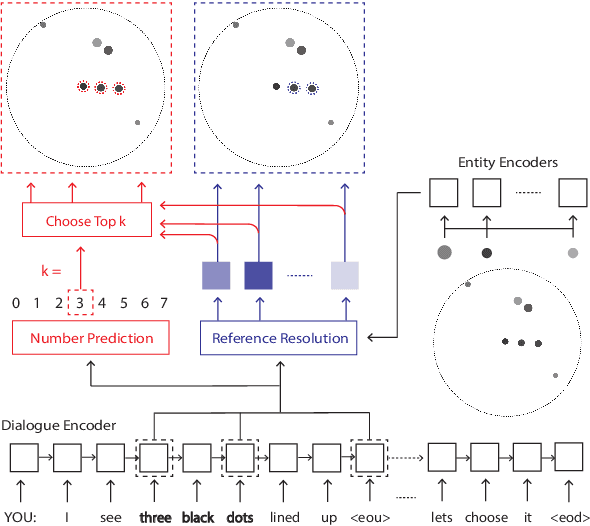
Recent models achieve promising results in visually grounded dialogues. However, existing datasets often contain undesirable biases and lack sophisticated linguistic analyses, which make it difficult to understand how well current models recognize their precise linguistic structures. To address this problem, we make two design choices: first, we focus on OneCommon Corpus \citep{udagawa2019natural,udagawa2020annotated}, a simple yet challenging common grounding dataset which contains minimal bias by design. Second, we analyze their linguistic structures based on \textit{spatial expressions} and provide comprehensive and reliable annotation for 600 dialogues. We show that our annotation captures important linguistic structures including predicate-argument structure, modification and ellipsis. In our experiments, we assess the model's understanding of these structures through reference resolution. We demonstrate that our annotation can reveal both the strengths and weaknesses of baseline models in essential levels of detail. Overall, we propose a novel framework and resource for investigating fine-grained language understanding in visually grounded dialogues.