 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTourist Guidance Robot Based on HyperCLOVA
Oct 19, 2022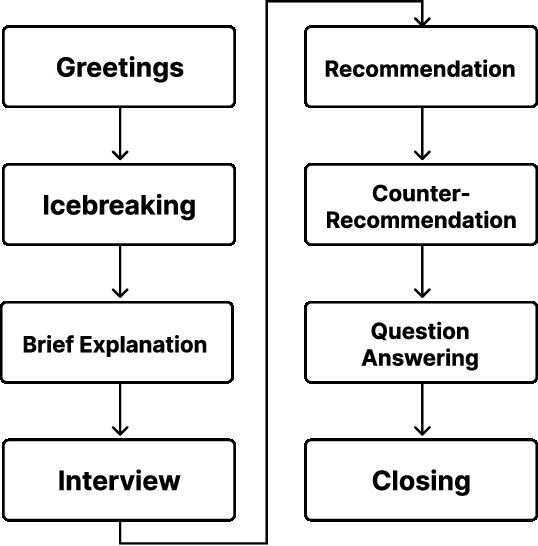



This paper describes our system submitted to Dialogue Robot Competition 2022. Our proposed system is a combined model of rule-based and generation-based dialog systems. The system utilizes HyperCLOVA, a Japanese foundation model, not only to generate responses but also summarization, search information, etc. We also used our original speech recognition system, which was fine-tuned for this dialog task. As a result, our system ranked second in the preliminary round and moved on to the finals.
InterAug: Augmenting Noisy Intermediate Predictions for CTC-based ASR
Apr 01, 2022
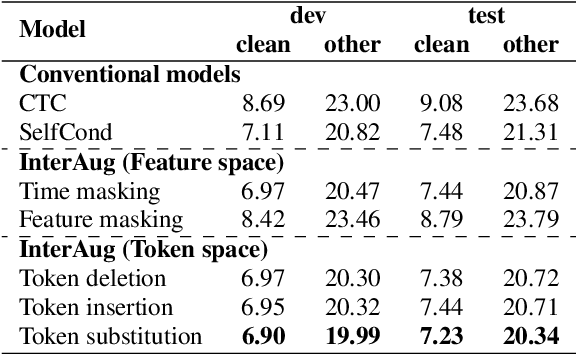
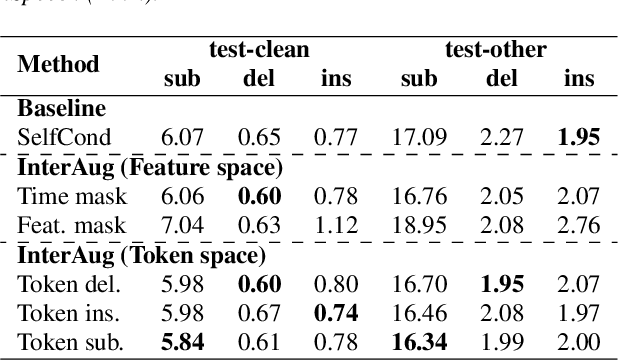
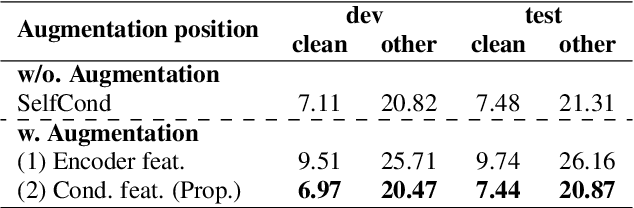
This paper proposes InterAug: a novel training method for CTC-based ASR using augmented intermediate representations for conditioning. The proposed method exploits the conditioning framework of self-conditioned CTC to train robust models by conditioning with "noisy" intermediate predictions. During the training, intermediate predictions are changed to incorrect intermediate predictions, and fed into the next layer for conditioning. The subsequent layers are trained to correct the incorrect intermediate predictions with the intermediate losses. By repeating the augmentation and the correction, iterative refinements, which generally require a special decoder, can be realized only with the audio encoder. To produce noisy intermediate predictions, we also introduce new augmentation: intermediate feature space augmentation and intermediate token space augmentation that are designed to simulate typical errors. The combination of the proposed InterAug framework with new augmentation allows explicit training of the robust audio encoders. In experiments using augmentations simulating deletion, insertion, and substitution error, we confirmed that the trained model acquires robustness to each error, boosting the speech recognition performance of the strong self-conditioned CTC baseline.