 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterBiasing: Boost Unseen Word Recognition through Biasing Intermediate Predictions
Jun 21, 2024Despite recent advances in end-to-end speech recognition methods, their output is biased to the training data's vocabulary, resulting in inaccurate recognition of unknown terms or proper nouns. To improve the recognition accuracy for a given set of such terms, we propose an adaptation parameter-free approach based on Self-conditioned CTC. Our method improves the recognition accuracy of misrecognized target keywords by substituting their intermediate CTC predictions with corrected labels, which are then passed on to the subsequent layers. First, we create pairs of correct labels and recognition error instances for a keyword list using Text-to-Speech and a recognition model. We use these pairs to replace intermediate prediction errors by the labels. Conditioning the subsequent layers of the encoder on the labels, it is possible to acoustically evaluate the target keywords. Experiments conducted in Japanese demonstrated that our method successfully improved the F1 score for unknown words.
InterAug: Augmenting Noisy Intermediate Predictions for CTC-based ASR
Apr 01, 2022
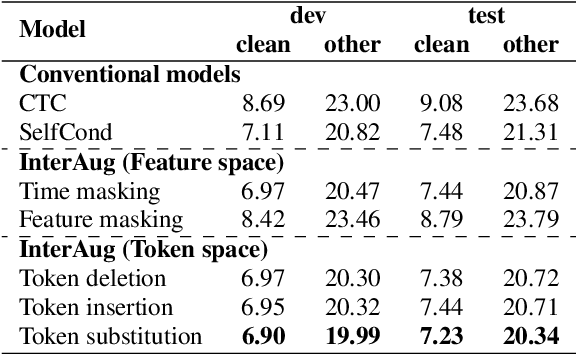
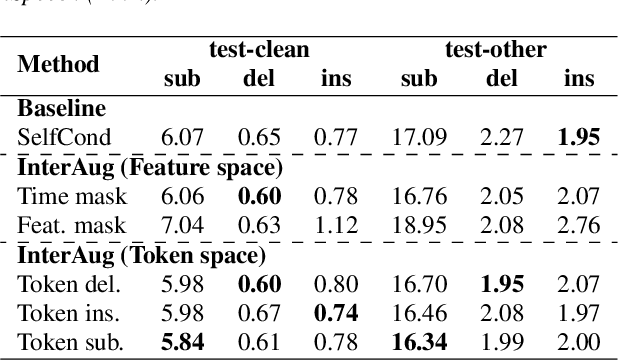
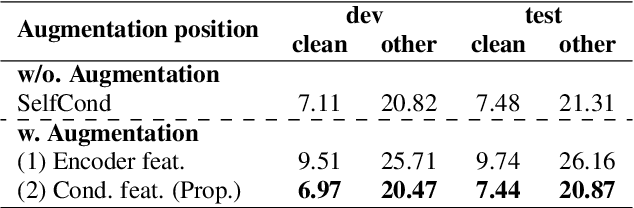
This paper proposes InterAug: a novel training method for CTC-based ASR using augmented intermediate representations for conditioning. The proposed method exploits the conditioning framework of self-conditioned CTC to train robust models by conditioning with "noisy" intermediate predictions. During the training, intermediate predictions are changed to incorrect intermediate predictions, and fed into the next layer for conditioning. The subsequent layers are trained to correct the incorrect intermediate predictions with the intermediate losses. By repeating the augmentation and the correction, iterative refinements, which generally require a special decoder, can be realized only with the audio encoder. To produce noisy intermediate predictions, we also introduce new augmentation: intermediate feature space augmentation and intermediate token space augmentation that are designed to simulate typical errors. The combination of the proposed InterAug framework with new augmentation allows explicit training of the robust audio encoders. In experiments using augmentations simulating deletion, insertion, and substitution error, we confirmed that the trained model acquires robustness to each error, boosting the speech recognition performance of the strong self-conditioned CTC baseline.