 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinimum Bayes Risk Decoding for Error Span Detection in Reference-Free Automatic Machine Translation Evaluation
Dec 19, 2025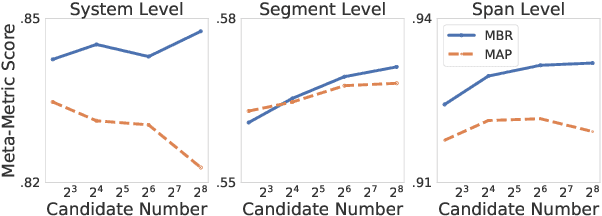

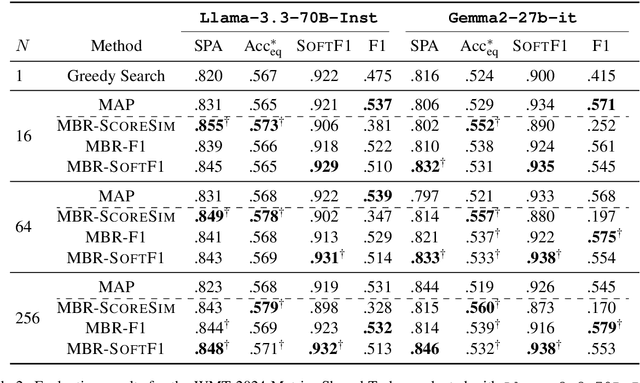
Error Span Detection (ESD) extends automatic machine translation (MT) evaluation by localizing translation errors and labeling their severity. Current generative ESD methods typically use Maximum a Posteriori (MAP) decoding, assuming that the model-estimated probabilities are perfectly correlated with similarity to the human annotation, but we often observe higher likelihood assigned to an incorrect annotation than to the human one. We instead apply Minimum Bayes Risk (MBR) decoding to generative ESD. We use a sentence- or span-level similarity function for MBR decoding, which selects candidate hypotheses based on their approximate similarity to the human annotation. Experimental results on the WMT24 Metrics Shared Task show that MBR decoding significantly improves span-level performance and generally matches or outperforms MAP at the system and sentence levels. To reduce the computational cost of MBR decoding, we further distill its decisions into a model decoded via greedy search, removing the inference-time latency bottleneck.
Emotion Recognition in Signers
Dec 17, 2025Recognition of signers' emotions suffers from one theoretical challenge and one practical challenge, namely, the overlap between grammatical and affective facial expressions and the scarcity of data for model training. This paper addresses these two challenges in a cross-lingual setting using our eJSL dataset, a new benchmark dataset for emotion recognition in Japanese Sign Language signers, and BOBSL, a large British Sign Language dataset with subtitles. In eJSL, two signers expressed 78 distinct utterances with each of seven different emotional states, resulting in 1,092 video clips. We empirically demonstrate that 1) textual emotion recognition in spoken language mitigates data scarcity in sign language, 2) temporal segment selection has a significant impact, and 3) incorporating hand motion enhances emotion recognition in signers. Finally we establish a stronger baseline than spoken language LLMs.
Unveiling the Power of Source: Source-based Minimum Bayes Risk Decoding for Neural Machine Translation
Jun 17, 2024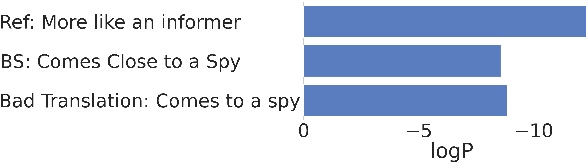
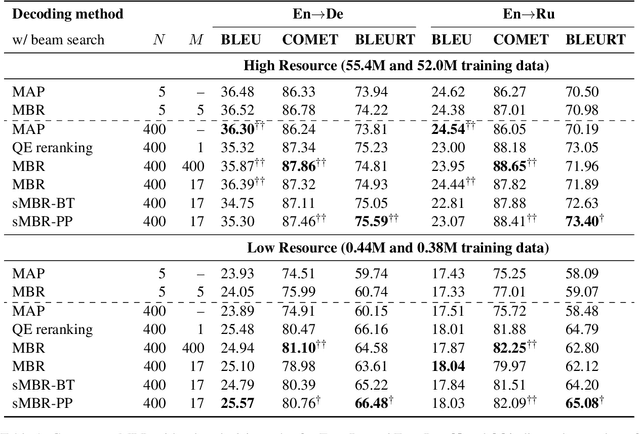
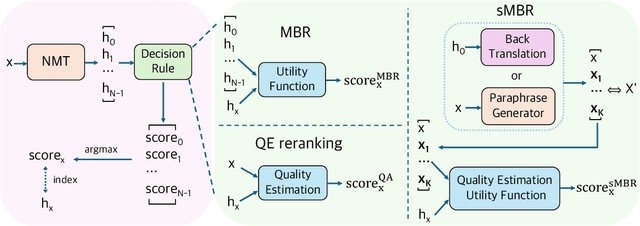
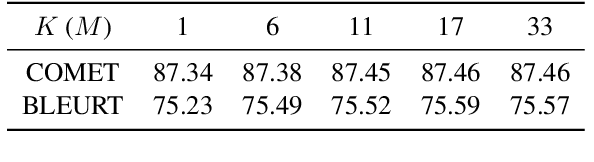
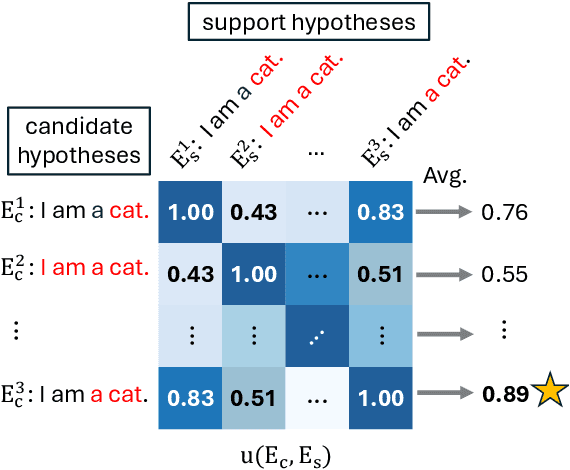
Maximum a posteriori decoding, a commonly used method for neural machine translation (NMT), aims to maximize the estimated posterior probability. However, high estimated probability does not always lead to high translation quality. Minimum Bayes Risk (MBR) decoding offers an alternative by seeking hypotheses with the highest expected utility. In this work, we show that Quality Estimation (QE) reranking, which uses a QE model as a reranker, can be viewed as a variant of MBR. Inspired by this, we propose source-based MBR (sMBR) decoding, a novel approach that utilizes synthetic sources generated by backward translation as ``support hypotheses'' and a reference-free quality estimation metric as the utility function, marking the first work to solely use sources in MBR decoding. Experiments show that sMBR significantly outperforms QE reranking and is competitive with standard MBR decoding. Furthermore, sMBR calls the utility function fewer times compared to MBR. Our findings suggest that sMBR is a promising approach for high-quality NMT decoding.
DiLM: Distilling Dataset into Language Model for Text-level Dataset Distillation
Mar 30, 2024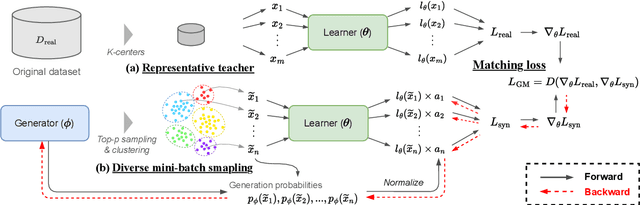
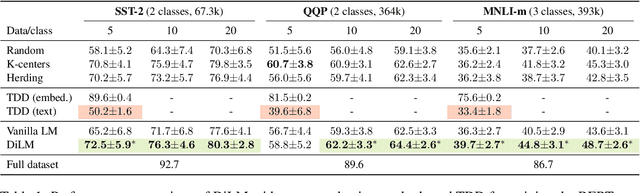
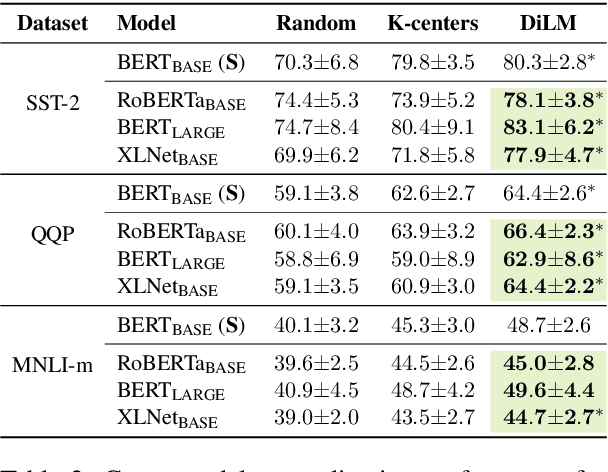
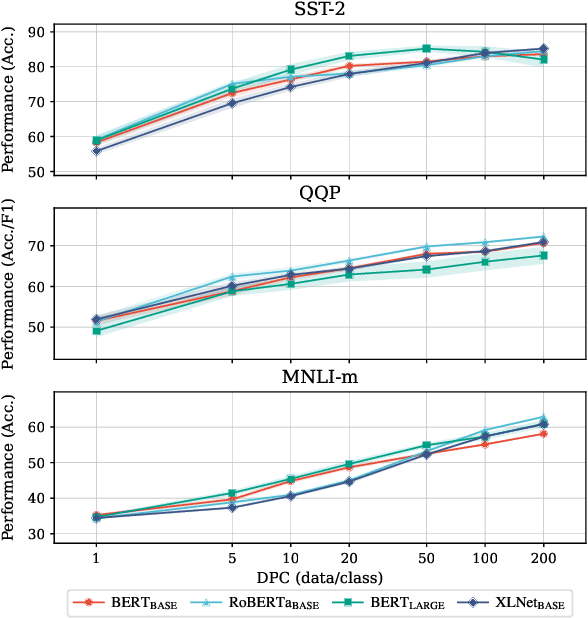
Dataset distillation aims to compress a training dataset by creating a small number of informative synthetic samples such that neural networks trained on them perform as well as those trained on the original training dataset. Current text dataset distillation methods create each synthetic sample as a sequence of word embeddings instead of a text to apply gradient-based optimization; however, such embedding-level distilled datasets cannot be used for training other models whose word embedding weights are different from the model used for distillation. To address this issue, we propose a novel text dataset distillation approach, called Distilling dataset into Language Model (DiLM), which trains a language model to generate informative synthetic training samples as text data, instead of directly optimizing synthetic samples. We evaluated DiLM on various text classification datasets and showed that distilled synthetic datasets from DiLM outperform those from current coreset selection methods. DiLM achieved remarkable generalization performance in training different types of models and in-context learning of large language models. Our code will be available at https://github.com/arumaekawa/DiLM.
Joyful: Joint Modality Fusion and Graph Contrastive Learning for Multimodal Emotion Recognition
Nov 18, 2023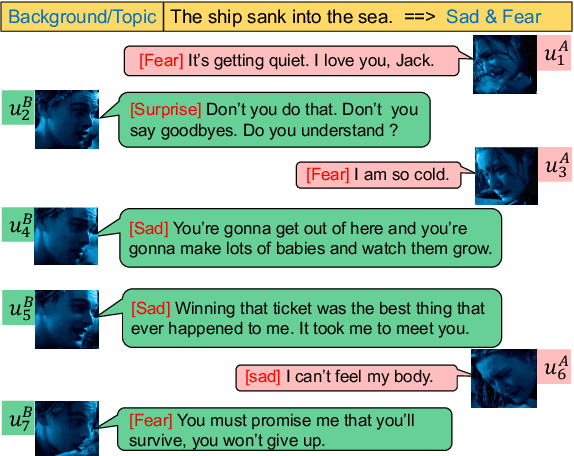
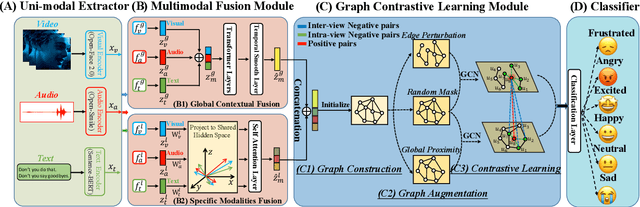

Multimodal emotion recognition aims to recognize emotions for each utterance of multiple modalities, which has received increasing attention for its application in human-machine interaction. Current graph-based methods fail to simultaneously depict global contextual features and local diverse uni-modal features in a dialogue. Furthermore, with the number of graph layers increasing, they easily fall into over-smoothing. In this paper, we propose a method for joint modality fusion and graph contrastive learning for multimodal emotion recognition (Joyful), where multimodality fusion, contrastive learning, and emotion recognition are jointly optimized. Specifically, we first design a new multimodal fusion mechanism that can provide deep interaction and fusion between the global contextual and uni-modal specific features. Then, we introduce a graph contrastive learning framework with inter-view and intra-view contrastive losses to learn more distinguishable representations for samples with different sentiments. Extensive experiments on three benchmark datasets indicate that Joyful achieved state-of-the-art (SOTA) performance compared to all baselines.
Active Learning Based Fine-Tuning Framework for Speech Emotion Recognition
Sep 30, 2023



Speech emotion recognition (SER) has drawn increasing attention for its applications in human-machine interaction. However, existing SER methods ignore the information gap between the pre-training speech recognition task and the downstream SER task, leading to sub-optimal performance. Moreover, they require much time to fine-tune on each specific speech dataset, restricting their effectiveness in real-world scenes with large-scale noisy data. To address these issues, we propose an active learning (AL) based Fine-Tuning framework for SER that leverages task adaptation pre-training (TAPT) and AL methods to enhance performance and efficiency. Specifically, we first use TAPT to minimize the information gap between the pre-training and the downstream task. Then, AL methods are used to iteratively select a subset of the most informative and diverse samples for fine-tuning, reducing time consumption. Experiments demonstrate that using only 20\%pt. samples improves 8.45\%pt. accuracy and reduces 79\%pt. time consumption.
Automatic Answerability Evaluation for Question Generation
Sep 22, 2023



Conventional automatic evaluation metrics, such as BLEU and ROUGE, developed for natural language generation (NLG) tasks, are based on measuring the n-gram overlap between the generated and reference text. These simple metrics may be insufficient for more complex tasks, such as question generation (QG), which requires generating questions that are answerable by the reference answers. Developing a more sophisticated automatic evaluation metric, thus, remains as an urgent problem in QG research. This work proposes a Prompting-based Metric on ANswerability (PMAN), a novel automatic evaluation metric to assess whether the generated questions are answerable by the reference answers for the QG tasks. Extensive experiments demonstrate that its evaluation results are reliable and align with human evaluations. We further apply our metric to evaluate the performance of QG models, which shows our metric complements conventional metrics. Our implementation of a ChatGPT-based QG model achieves state-of-the-art (SOTA) performance in generating answerable questions.
Non-Axiomatic Term Logic: A Computational Theory of Cognitive Symbolic Reasoning
Oct 12, 2022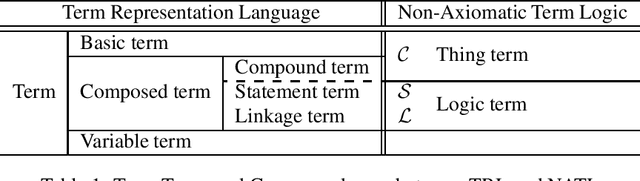
This paper presents Non-Axiomatic Term Logic (NATL) as a theoretical computational framework of humanlike symbolic reasoning in artificial intelligence. NATL unites a discrete syntactic system inspired from Aristotle's term logic and a continuous semantic system based on the modern idea of distributed representations, or embeddings. This paper positions the proposed approach in the phylogeny and the literature of logic, and explains the framework. As it is yet no more than a theory and it requires much further elaboration to implement it, no quantitative evaluation is presented. Instead, qualitative analyses of arguments using NATL, some applications to possible cognitive science/robotics-related research, and remaining issues towards a machinery implementation are discussed.
Generating Repetitions with Appropriate Repeated Words
Jul 03, 2022



A repetition is a response that repeats words in the previous speaker's utterance in a dialogue. Repetitions are essential in communication to build trust with others, as investigated in linguistic studies. In this work, we focus on repetition generation. To the best of our knowledge, this is the first neural approach to address repetition generation. We propose Weighted Label Smoothing, a smoothing method for explicitly learning which words to repeat during fine-tuning, and a repetition scoring method that can output more appropriate repetitions during decoding. We conducted automatic and human evaluations involving applying these methods to the pre-trained language model T5 for generating repetitions. The experimental results indicate that our methods outperformed baselines in both evaluations.