 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging the Powerful Attention of a Pre-trained Diffusion Model for Exemplar-based Image Colorization
May 21, 2025Exemplar-based image colorization aims to colorize a grayscale image using a reference color image, ensuring that reference colors are applied to corresponding input regions based on their semantic similarity. To achieve accurate semantic matching between regions, we leverage the self-attention module of a pre-trained diffusion model, which is trained on a large dataset and exhibits powerful attention capabilities. To harness this power, we propose a novel, fine-tuning-free approach based on a pre-trained diffusion model, making two key contributions. First, we introduce dual attention-guided color transfer. We utilize the self-attention module to compute an attention map between the input and reference images, effectively capturing semantic correspondences. The color features from the reference image is then transferred to the semantically matching regions of the input image, guided by this attention map, and finally, the grayscale features are replaced with the corresponding color features. Notably, we utilize dual attention to calculate attention maps separately for the grayscale and color images, achieving more precise semantic alignment. Second, we propose classifier-free colorization guidance, which enhances the transferred colors by combining color-transferred and non-color-transferred outputs. This process improves the quality of colorization. Our experimental results demonstrate that our method outperforms existing techniques in terms of image quality and fidelity to the reference. Specifically, we use 335 input-reference pairs from previous research, achieving an FID of 95.27 (image quality) and an SI-FID of 5.51 (fidelity to the reference). Our source code is available at https://github.com/satoshi-kosugi/powerful-attention.
Revisiting Dynamic Graph Clustering via Matrix Factorization
Feb 10, 2025



Dynamic graph clustering aims to detect and track time-varying clusters in dynamic graphs, revealing the evolutionary mechanisms of complex real-world dynamic systems. Matrix factorization-based methods are promising approaches for this task; however, these methods often struggle with scalability and can be time-consuming when applied to large-scale dynamic graphs. Moreover, they tend to lack robustness and are vulnerable to real-world noisy data. To address these issues, we make three key contributions. First, to improve scalability, we propose temporal separated matrix factorization, where a single matrix is divided into multiple smaller matrices for independent factorization, resulting in faster computation. Second, to improve robustness, we introduce bi-clustering regularization, which jointly optimizes graph embedding and clustering, thereby filtering out noisy features from the graph embeddings. Third, to further enhance effectiveness and efficiency, we propose selective embedding updating, where we update only the embeddings of dynamic nodes while the embeddings of static nodes are fixed among different timestamps. Experimental results on six synthetic and five real-world benchmarks demonstrate the scalability, robustness and effectiveness of our proposed method. Source code is available at https://github.com/Clearloveyuan/DyG-MF.
Prompt-Guided Image-Adaptive Neural Implicit Lookup Tables for Interpretable Image Enhancement
Aug 20, 2024In this paper, we delve into the concept of interpretable image enhancement, a technique that enhances image quality by adjusting filter parameters with easily understandable names such as "Exposure" and "Contrast". Unlike using predefined image editing filters, our framework utilizes learnable filters that acquire interpretable names through training. Our contribution is two-fold. Firstly, we introduce a novel filter architecture called an image-adaptive neural implicit lookup table, which uses a multilayer perceptron to implicitly define the transformation from input feature space to output color space. By incorporating image-adaptive parameters directly into the input features, we achieve highly expressive filters. Secondly, we introduce a prompt guidance loss to assign interpretable names to each filter. We evaluate visual impressions of enhancement results, such as exposure and contrast, using a vision and language model along with guiding prompts. We define a constraint to ensure that each filter affects only the targeted visual impression without influencing other attributes, which allows us to obtain the desired filter effects. Experimental results show that our method outperforms existing predefined filter-based methods, thanks to the filters optimized to predict target results. Our source code is available at https://github.com/satoshi-kosugi/PG-IA-NILUT.
DiLM: Distilling Dataset into Language Model for Text-level Dataset Distillation
Mar 30, 2024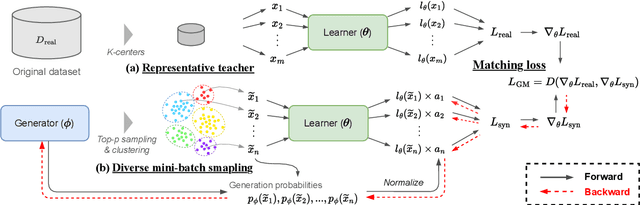
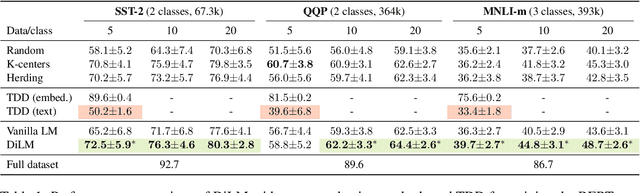
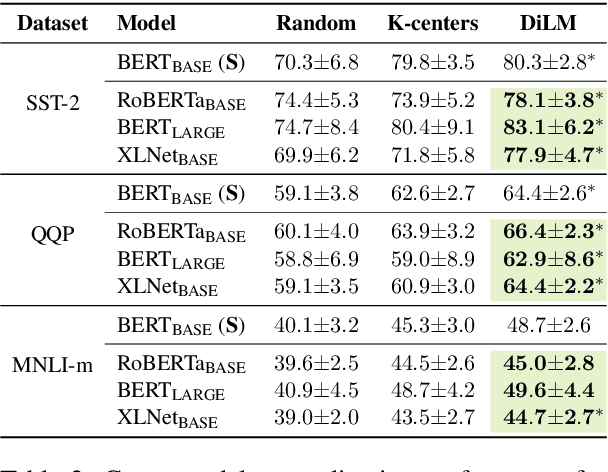
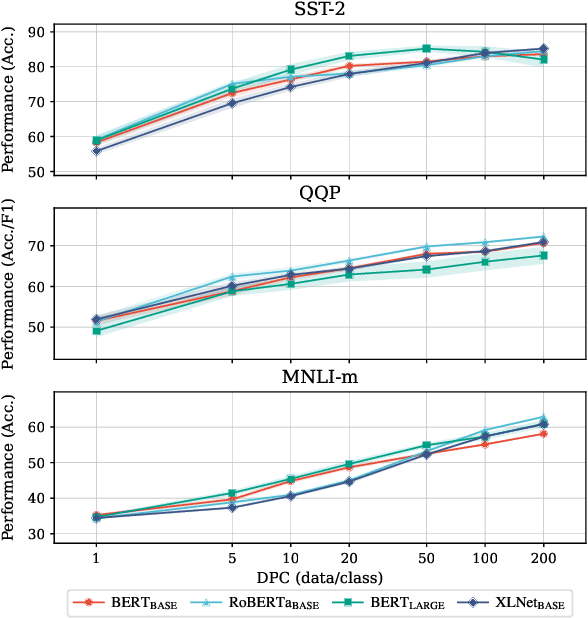
Dataset distillation aims to compress a training dataset by creating a small number of informative synthetic samples such that neural networks trained on them perform as well as those trained on the original training dataset. Current text dataset distillation methods create each synthetic sample as a sequence of word embeddings instead of a text to apply gradient-based optimization; however, such embedding-level distilled datasets cannot be used for training other models whose word embedding weights are different from the model used for distillation. To address this issue, we propose a novel text dataset distillation approach, called Distilling dataset into Language Model (DiLM), which trains a language model to generate informative synthetic training samples as text data, instead of directly optimizing synthetic samples. We evaluated DiLM on various text classification datasets and showed that distilled synthetic datasets from DiLM outperform those from current coreset selection methods. DiLM achieved remarkable generalization performance in training different types of models and in-context learning of large language models. Our code will be available at https://github.com/arumaekawa/DiLM.
Personalized Image Enhancement Featuring Masked Style Modeling
Jun 15, 2023We address personalized image enhancement in this study, where we enhance input images for each user based on the user's preferred images. Previous methods apply the same preferred style to all input images (i.e., only one style for each user); in contrast to these methods, we aim to achieve content-aware personalization by applying different styles to each image considering the contents. For content-aware personalization, we make two contributions. First, we propose a method named masked style modeling, which can predict a style for an input image considering the contents by using the framework of masked language modeling. Second, to allow this model to consider the contents of images, we propose a novel training scheme where we download images from Flickr and create pseudo input and retouched image pairs using a degrading model. We conduct quantitative evaluations and a user study, and our method trained using our training scheme successfully achieves content-aware personalization; moreover, our method outperforms other previous methods in this field. Our source code is available at https://github.com/satoshi-kosugi/masked-style-modeling.
Crowd-Powered Photo Enhancement Featuring an Active Learning Based Local Filter
Jun 15, 2023In this study, we address local photo enhancement to improve the aesthetic quality of an input image by applying different effects to different regions. Existing photo enhancement methods are either not content-aware or not local; therefore, we propose a crowd-powered local enhancement method for content-aware local enhancement, which is achieved by asking crowd workers to locally optimize parameters for image editing functions. To make it easier to locally optimize the parameters, we propose an active learning based local filter. The parameters need to be determined at only a few key pixels selected by an active learning method, and the parameters at the other pixels are automatically predicted using a regression model. The parameters at the selected key pixels are independently optimized, breaking down the optimization problem into a sequence of single-slider adjustments. Our experiments show that the proposed filter outperforms existing filters, and our enhanced results are more visually pleasing than the results by the existing enhancement methods. Our source code and results are available at https://github.com/satoshi-kosugi/crowd-powered.
Self-Play Reinforcement Learning for Fast Image Retargeting
Oct 02, 2020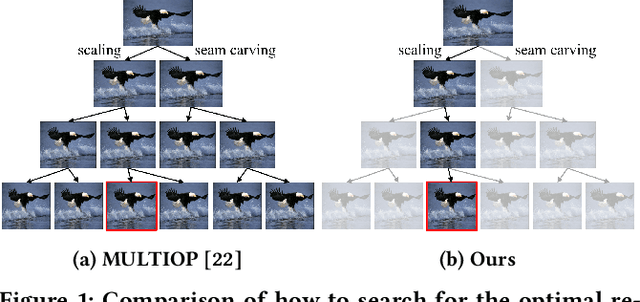
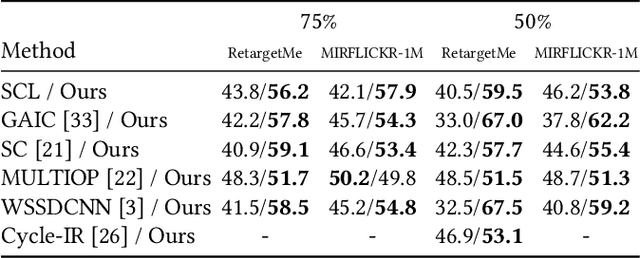
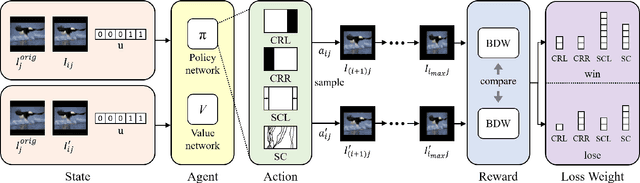
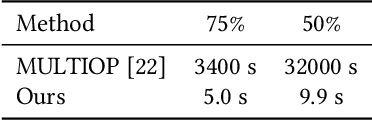
In this study, we address image retargeting, which is a task that adjusts input images to arbitrary sizes. In one of the best-performing methods called MULTIOP, multiple retargeting operators were combined and retargeted images at each stage were generated to find the optimal sequence of operators that minimized the distance between original and retargeted images. The limitation of this method is in its tremendous processing time, which severely prohibits its practical use. Therefore, the purpose of this study is to find the optimal combination of operators within a reasonable processing time; we propose a method of predicting the optimal operator for each step using a reinforcement learning agent. The technical contributions of this study are as follows. Firstly, we propose a reward based on self-play, which will be insensitive to the large variance in the content-dependent distance measured in MULTIOP. Secondly, we propose to dynamically change the loss weight for each action to prevent the algorithm from falling into a local optimum and from choosing only the most frequently used operator in its training. Our experiments showed that we achieved multi-operator image retargeting with less processing time by three orders of magnitude and the same quality as the original multi-operator-based method, which was the best-performing algorithm in retargeting tasks.
Unpaired Image Enhancement Featuring Reinforcement-Learning-Controlled Image Editing Software
Dec 17, 2019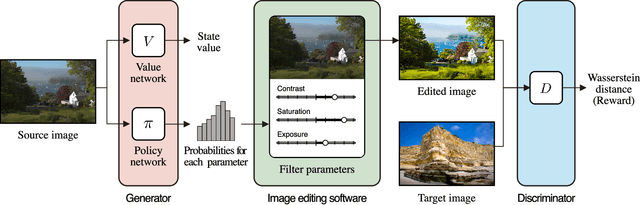
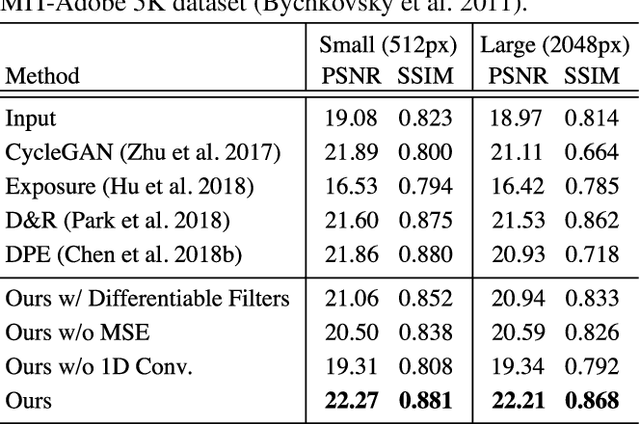
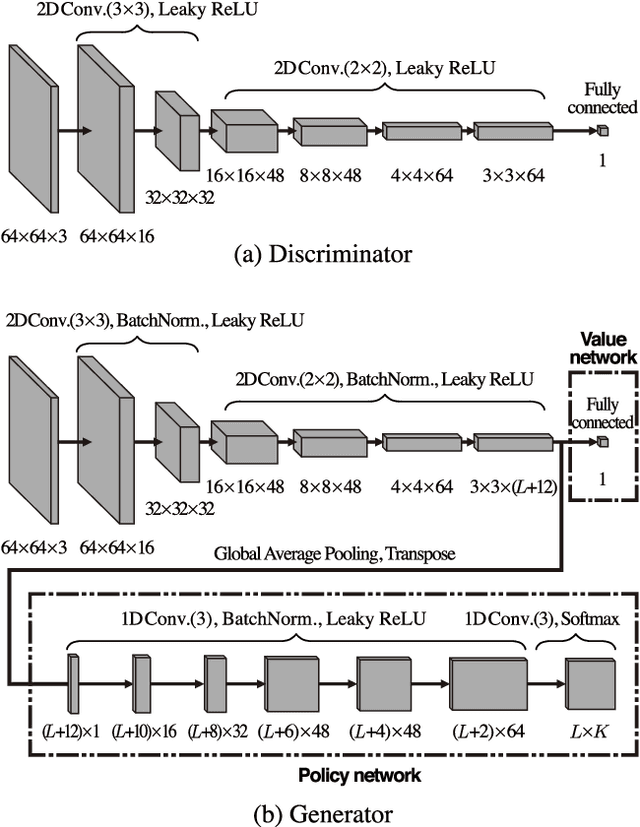
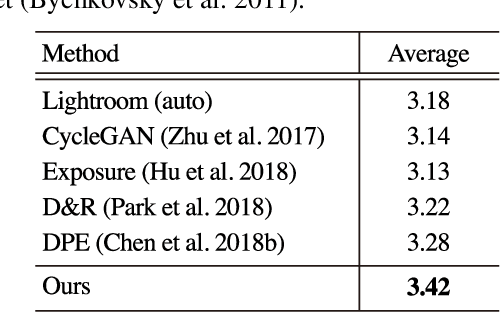
This paper tackles unpaired image enhancement, a task of learning a mapping function which transforms input images into enhanced images in the absence of input-output image pairs. Our method is based on generative adversarial networks (GANs), but instead of simply generating images with a neural network, we enhance images utilizing image editing software such as Adobe Photoshop for the following three benefits: enhanced images have no artifacts, the same enhancement can be applied to larger images, and the enhancement is interpretable. To incorporate image editing software into a GAN, we propose a reinforcement learning framework where the generator works as the agent that selects the software's parameters and is rewarded when it fools the discriminator. Our framework can use high-quality non-differentiable filters present in image editing software, which enables image enhancement with high performance. We apply the proposed method to two unpaired image enhancement tasks: photo enhancement and face beautification. Our experimental results demonstrate that the proposed method achieves better performance, compared to the performances of the state-of-the-art methods based on unpaired learning.
Object-Aware Instance Labeling for Weakly Supervised Object Detection
Aug 10, 2019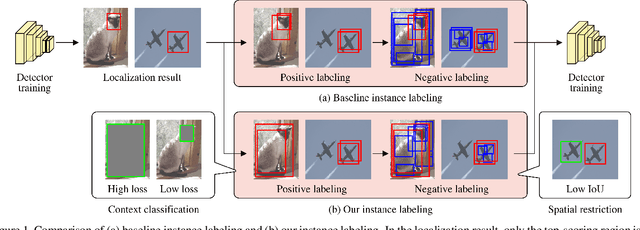
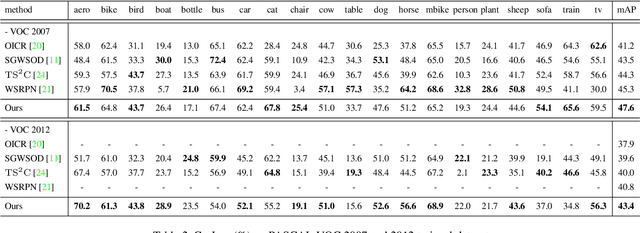
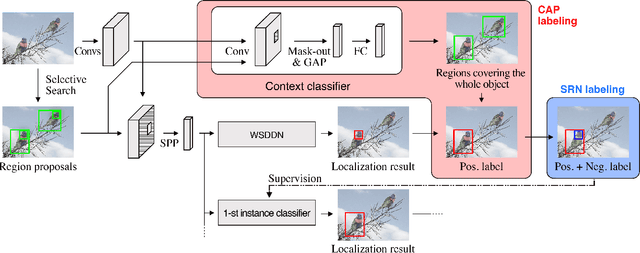
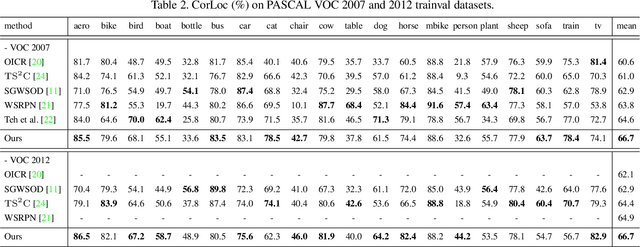
Weakly supervised object detection (WSOD), where a detector is trained with only image-level annotations, is attracting more and more attention. As a method to obtain a well-performing detector, the detector and the instance labels are updated iteratively. In this study, for more efficient iterative updating, we focus on the instance labeling problem, a problem of which label should be annotated to each region based on the last localization result. Instead of simply labeling the top-scoring region and its highly overlapping regions as positive and others as negative, we propose more effective instance labeling methods as follows. First, to solve the problem that regions covering only some parts of the object tend to be labeled as positive, we find regions covering the whole object focusing on the context classification loss. Second, considering the situation where the other objects contained in the image can be labeled as negative, we impose a spatial restriction on regions labeled as negative. Using these instance labeling methods, we train the detector on the PASCAL VOC 2007 and 2012 and obtain significantly improved results compared with other state-of-the-art approaches.