 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Camouflaged Object Detection with the Uncertainty of Pseudo-edge Labels
Oct 29, 2021
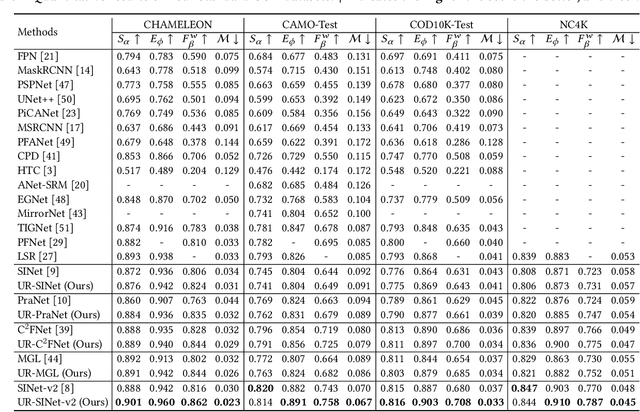
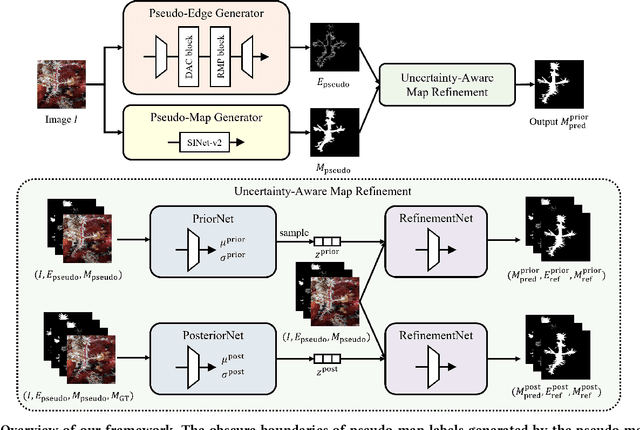

This paper focuses on camouflaged object detection (COD), which is a task to detect objects hidden in the background. Most of the current COD models aim to highlight the target object directly while outputting ambiguous camouflaged boundaries. On the other hand, the performance of the models considering edge information is not yet satisfactory. To this end, we propose a new framework that makes full use of multiple visual cues, i.e., saliency as well as edges, to refine the predicted camouflaged map. This framework consists of three key components, i.e., a pseudo-edge generator, a pseudo-map generator, and an uncertainty-aware refinement module. In particular, the pseudo-edge generator estimates the boundary that outputs the pseudo-edge label, and the conventional COD method serves as the pseudo-map generator that outputs the pseudo-map label. Then, we propose an uncertainty-based module to reduce the uncertainty and noise of such two pseudo labels, which takes both pseudo labels as input and outputs an edge-accurate camouflaged map. Experiments on various COD datasets demonstrate the effectiveness of our method with superior performance to the existing state-of-the-art methods.
Self-Play Reinforcement Learning for Fast Image Retargeting
Oct 02, 2020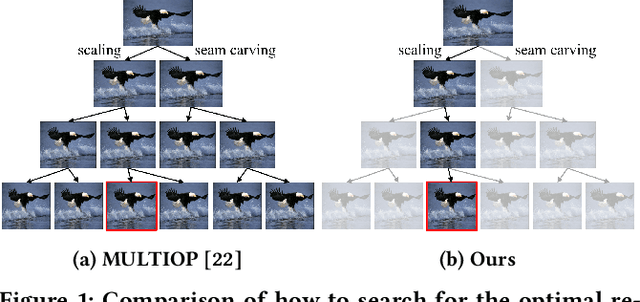
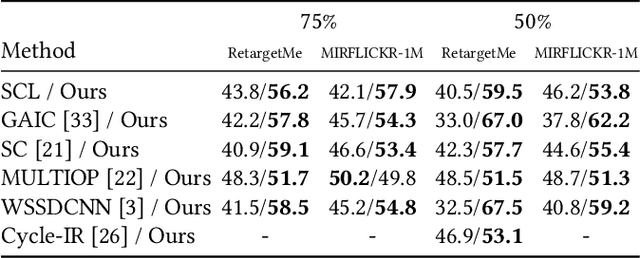
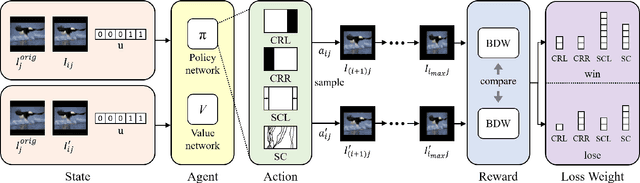
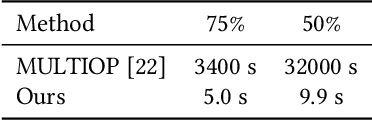
In this study, we address image retargeting, which is a task that adjusts input images to arbitrary sizes. In one of the best-performing methods called MULTIOP, multiple retargeting operators were combined and retargeted images at each stage were generated to find the optimal sequence of operators that minimized the distance between original and retargeted images. The limitation of this method is in its tremendous processing time, which severely prohibits its practical use. Therefore, the purpose of this study is to find the optimal combination of operators within a reasonable processing time; we propose a method of predicting the optimal operator for each step using a reinforcement learning agent. The technical contributions of this study are as follows. Firstly, we propose a reward based on self-play, which will be insensitive to the large variance in the content-dependent distance measured in MULTIOP. Secondly, we propose to dynamically change the loss weight for each action to prevent the algorithm from falling into a local optimum and from choosing only the most frequently used operator in its training. Our experiments showed that we achieved multi-operator image retargeting with less processing time by three orders of magnitude and the same quality as the original multi-operator-based method, which was the best-performing algorithm in retargeting tasks.