 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRouting by Analogy: kNN-Augmented Expert Assignment for Mixture-of-Experts
Jan 05, 2026Mixture-of-Experts (MoE) architectures scale large language models efficiently by employing a parametric "router" to dispatch tokens to a sparse subset of experts. Typically, this router is trained once and then frozen, rendering routing decisions brittle under distribution shifts. We address this limitation by introducing kNN-MoE, a retrieval-augmented routing framework that reuses optimal expert assignments from a memory of similar past cases. This memory is constructed offline by directly optimizing token-wise routing logits to maximize the likelihood on a reference set. Crucially, we use the aggregate similarity of retrieved neighbors as a confidence-driven mixing coefficient, thus allowing the method to fall back to the frozen router when no relevant cases are found. Experiments show kNN-MoE outperforms zero-shot baselines and rivals computationally expensive supervised fine-tuning.
Minimum Bayes Risk Decoding for Error Span Detection in Reference-Free Automatic Machine Translation Evaluation
Dec 19, 2025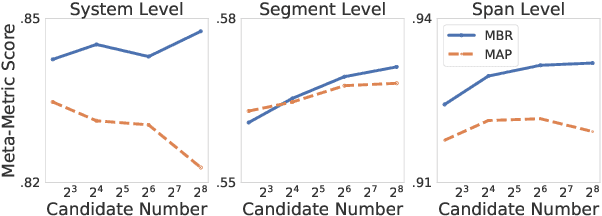

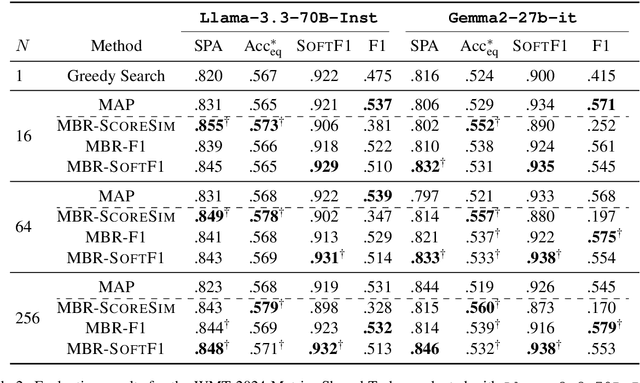
Error Span Detection (ESD) extends automatic machine translation (MT) evaluation by localizing translation errors and labeling their severity. Current generative ESD methods typically use Maximum a Posteriori (MAP) decoding, assuming that the model-estimated probabilities are perfectly correlated with similarity to the human annotation, but we often observe higher likelihood assigned to an incorrect annotation than to the human one. We instead apply Minimum Bayes Risk (MBR) decoding to generative ESD. We use a sentence- or span-level similarity function for MBR decoding, which selects candidate hypotheses based on their approximate similarity to the human annotation. Experimental results on the WMT24 Metrics Shared Task show that MBR decoding significantly improves span-level performance and generally matches or outperforms MAP at the system and sentence levels. To reduce the computational cost of MBR decoding, we further distill its decisions into a model decoded via greedy search, removing the inference-time latency bottleneck.
Unveiling the Power of Source: Source-based Minimum Bayes Risk Decoding for Neural Machine Translation
Jun 17, 2024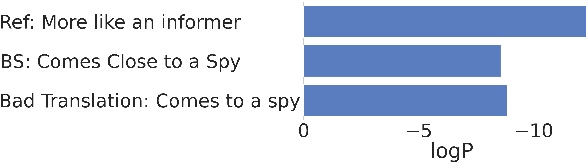
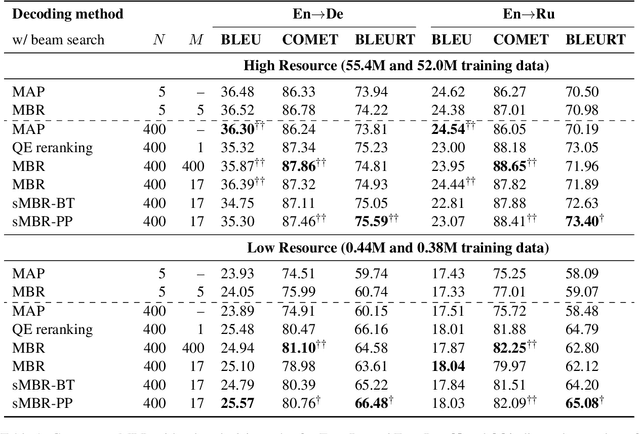
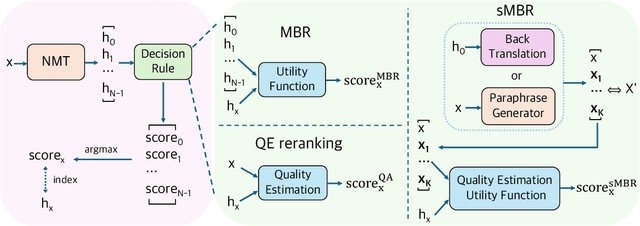
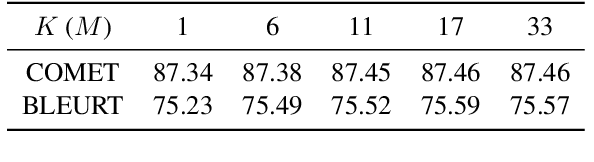
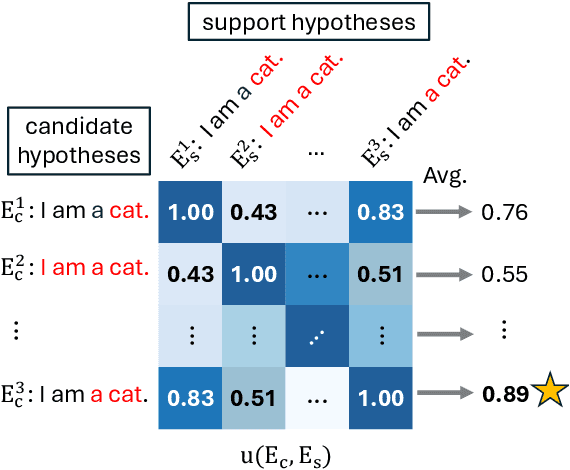
Maximum a posteriori decoding, a commonly used method for neural machine translation (NMT), aims to maximize the estimated posterior probability. However, high estimated probability does not always lead to high translation quality. Minimum Bayes Risk (MBR) decoding offers an alternative by seeking hypotheses with the highest expected utility. In this work, we show that Quality Estimation (QE) reranking, which uses a QE model as a reranker, can be viewed as a variant of MBR. Inspired by this, we propose source-based MBR (sMBR) decoding, a novel approach that utilizes synthetic sources generated by backward translation as ``support hypotheses'' and a reference-free quality estimation metric as the utility function, marking the first work to solely use sources in MBR decoding. Experiments show that sMBR significantly outperforms QE reranking and is competitive with standard MBR decoding. Furthermore, sMBR calls the utility function fewer times compared to MBR. Our findings suggest that sMBR is a promising approach for high-quality NMT decoding.