 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel Evolution Under Zeroth-Order Optimization: A Neural Tangent Kernel Perspective
Mar 22, 2026Zeroth-order (ZO) optimization enables memory-efficient training of neural networks by estimating gradients via forward passes only, eliminating the need for backpropagation. However, the stochastic nature of gradient estimation significantly obscures the training dynamics, in contrast to the well-characterized behavior of first-order methods under Neural Tangent Kernel (NTK) theory. To address this, we introduce the Neural Zeroth-order Kernel (NZK) to describe model evolution in function space under ZO updates. For linear models, we prove that the expected NZK remains constant throughout training and depends explicitly on the first and second moments of the random perturbation directions. This invariance yields a closed-form expression for model evolution under squared loss. We further extend the analysis to linearized neural networks. Interpreting ZO updates as kernel gradient descent via NZK provides a novel perspective for potentially accelerating convergence. Extensive experiments across synthetic and real-world datasets (including MNIST, CIFAR-10, and Tiny ImageNet) validate our theoretical results and demonstrate acceleration when using a single shared random vector.
Can We Trust LLMs on Memristors? Diving into Reasoning Ability under Non-Ideality
Mar 14, 2026Memristor-based analog compute-in-memory (CIM) architectures provide a promising substrate for the efficient deployment of Large Language Models (LLMs), owing to superior energy efficiency and computational density. However, these architectures suffer from precision issues caused by intrinsic non-idealities of memristors. In this paper, we first conduct a comprehensive investigation into the impact of such typical non-idealities on LLM reasoning. Empirical results indicate that reasoning capability decreases significantly but varies for distinct benchmarks. Subsequently, we systematically appraise three training-free strategies, including thinking mode, in-context learning, and module redundancy. We thus summarize valuable guidelines, i.e., shallow layer redundancy is particularly effective for improving robustness, thinking mode performs better under low noise levels but degrades at higher noise, and in-context learning reduces output length with a slight performance trade-off. Our findings offer new insights into LLM reasoning under non-ideality and practical strategies to improve robustness.
Minimum Bayes Risk Decoding for Error Span Detection in Reference-Free Automatic Machine Translation Evaluation
Dec 19, 2025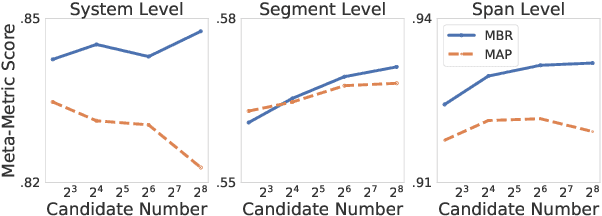

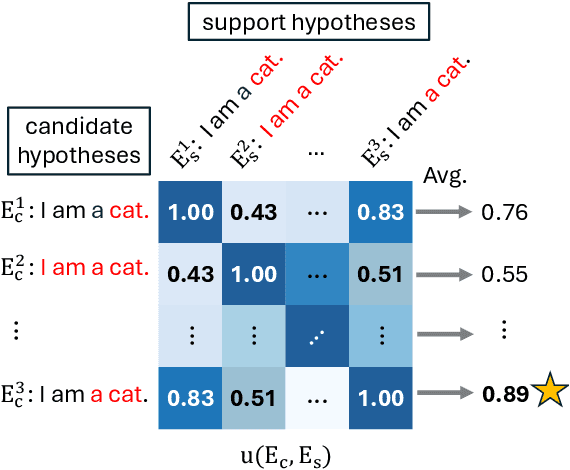
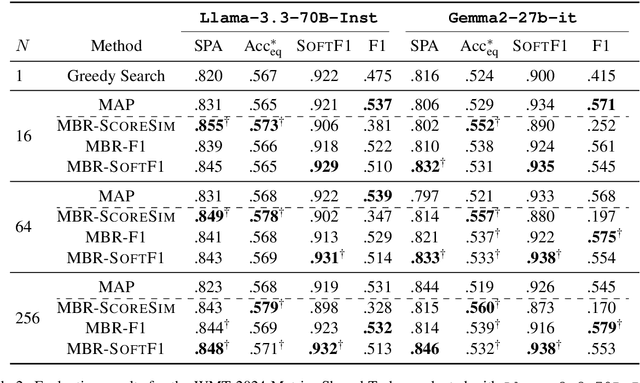
Error Span Detection (ESD) extends automatic machine translation (MT) evaluation by localizing translation errors and labeling their severity. Current generative ESD methods typically use Maximum a Posteriori (MAP) decoding, assuming that the model-estimated probabilities are perfectly correlated with similarity to the human annotation, but we often observe higher likelihood assigned to an incorrect annotation than to the human one. We instead apply Minimum Bayes Risk (MBR) decoding to generative ESD. We use a sentence- or span-level similarity function for MBR decoding, which selects candidate hypotheses based on their approximate similarity to the human annotation. Experimental results on the WMT24 Metrics Shared Task show that MBR decoding significantly improves span-level performance and generally matches or outperforms MAP at the system and sentence levels. To reduce the computational cost of MBR decoding, we further distill its decisions into a model decoded via greedy search, removing the inference-time latency bottleneck.
HaLoRA: Hardware-aware Low-Rank Adaptation for Large Language Models Based on Hybrid Compute-in-Memory Architecture
Feb 27, 2025
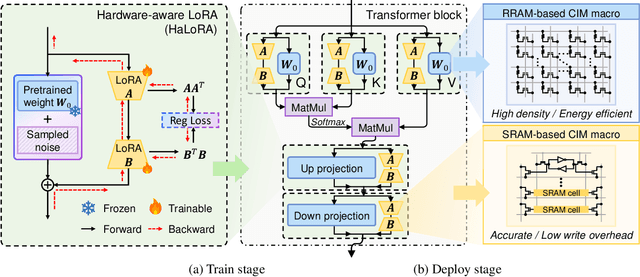
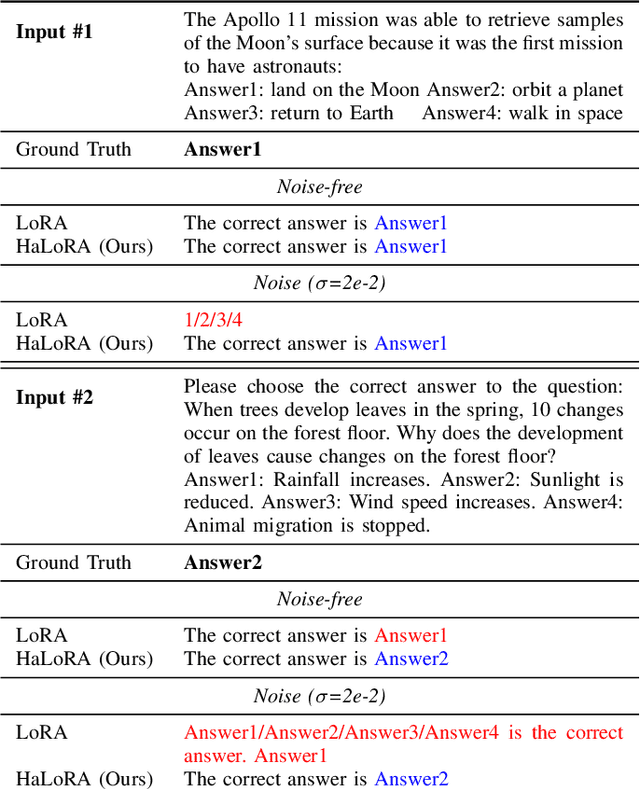
Low-rank adaptation (LoRA) is a predominant parameter-efficient finetuning method to adapt large language models (LLMs) for downstream tasks. In this paper, we first propose to deploy the LoRA-finetuned LLMs on the hybrid compute-in-memory (CIM) architecture (i.e., pretrained weights onto RRAM and LoRA onto SRAM). To address performance degradation from RRAM's inherent noise, we design a novel Hardware-aware Low-rank Adaption (HaLoRA) method, aiming to train a LoRA branch that is both robust and accurate by aligning the training objectives under both ideal and noisy conditions. Experiments finetuning LLaMA 3.2 1B and 3B demonstrate HaLoRA's effectiveness across multiple reasoning tasks, achieving up to 22.7 improvement in average score while maintaining robustness at various noise levels.
Registering Source Tokens to Target Language Spaces in Multilingual Neural Machine Translation
Jan 06, 2025



The multilingual neural machine translation (MNMT) enables arbitrary translations across multiple languages by training a model with limited parameters using parallel data only. However, the performance of such MNMT models still lags behind that of large language models (LLMs), limiting their practicality. In this work, we address this limitation by introducing registering to achieve the new state-of-the-art of decoder-only MNMT models. Specifically, we insert a set of artificial tokens specifying the target language, called registers, into the input sequence between the source and target tokens. By modifying the attention mask, the target token generation only pays attention to the activation of registers, representing the source tokens in the target language space. Experiments on EC-40, a large-scale benchmark, show that our method outperforms related methods driven by optimizing multilingual representations. We further scale up and collect 9.3 billion sentence pairs across 24 languages from public datasets to pre-train two models, namely MITRE (multilingual translation with registers). One of them, MITRE-913M, outperforms NLLB-3.3B, achieves comparable performance with commercial LLMs, and shows strong adaptability in fine-tuning. Finally, we open-source our models to facilitate further research and development in MNMT: https://github.com/zhiqu22/mitre.
Improving Language Transfer Capability of Decoder-only Architecture in Multilingual Neural Machine Translation
Dec 03, 2024



Existing multilingual neural machine translation (MNMT) approaches mainly focus on improving models with the encoder-decoder architecture to translate multiple languages. However, decoder-only architecture has been explored less in MNMT due to its underperformance when trained on parallel data solely. In this work, we attribute the issue of the decoder-only architecture to its lack of language transfer capability. Specifically, the decoder-only architecture is insufficient in encoding source tokens with the target language features. We propose dividing the decoding process into two stages so that target tokens are explicitly excluded in the first stage to implicitly boost the transfer capability across languages. Additionally, we impose contrastive learning on translation instructions, resulting in improved performance in zero-shot translation. We conduct experiments on TED-19 and OPUS-100 datasets, considering both training from scratch and fine-tuning scenarios. Experimental results show that, compared to the encoder-decoder architecture, our methods not only perform competitively in supervised translations but also achieve improvements of up to 3.39 BLEU, 6.99 chrF++, 3.22 BERTScore, and 4.81 COMET in zero-shot translations.
Languages Transferred Within the Encoder: On Representation Transfer in Zero-Shot Multilingual Translation
Jun 12, 2024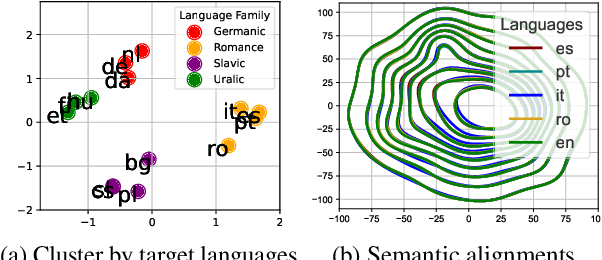
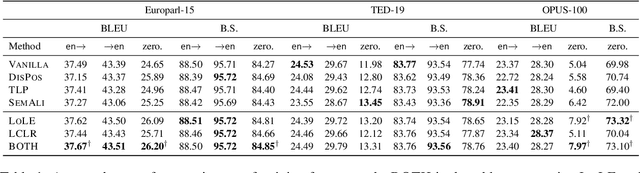
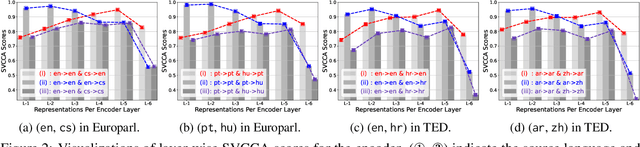
Understanding representation transfer in multilingual neural machine translation can reveal the representational issue causing the zero-shot translation deficiency. In this work, we introduce the identity pair, a sentence translated into itself, to address the lack of the base measure in multilingual investigations, as the identity pair represents the optimal state of representation among any language transfers. In our analysis, we demonstrate that the encoder transfers the source language to the representational subspace of the target language instead of the language-agnostic state. Thus, the zero-shot translation deficiency arises because representations are entangled with other languages and are not transferred effectively to the target language. Based on our findings, we propose two methods: 1) low-rank language-specific embedding at the encoder, and 2) language-specific contrastive learning of the representation at the decoder. The experimental results on Europarl-15, TED-19, and OPUS-100 datasets show that our methods substantially enhance the performance of zero-shot translations by improving language transfer capacity, thereby providing practical evidence to support our conclusions.
Outlier-Aware Training for Low-Bit Quantization of Structural Re-Parameterized Networks
Feb 11, 2024



Lightweight design of Convolutional Neural Networks (CNNs) requires co-design efforts in the model architectures and compression techniques. As a novel design paradigm that separates training and inference, a structural re-parameterized (SR) network such as the representative RepVGG revitalizes the simple VGG-like network with a high accuracy comparable to advanced and often more complicated networks. However, the merging process in SR networks introduces outliers into weights, making their distribution distinct from conventional networks and thus heightening difficulties in quantization. To address this, we propose an operator-level improvement for training called Outlier Aware Batch Normalization (OABN). Additionally, to meet the demands of limited bitwidths while upkeeping the inference accuracy, we develop a clustering-based non-uniform quantization framework for Quantization-Aware Training (QAT) named ClusterQAT. Integrating OABN with ClusterQAT, the quantized performance of RepVGG is largely enhanced, particularly when the bitwidth falls below 8.
A Crucial Parameter for Rank-Frequency Relation in Natural Languages
Feb 01, 2024$f \propto r^{-\alpha} \cdot (r+\gamma)^{-\beta}$ has been empirically shown more precise than a na\"ive power law $f\propto r^{-\alpha}$ to model the rank-frequency ($r$-$f$) relation of words in natural languages. This work shows that the only crucial parameter in the formulation is $\gamma$, which depicts the resistance to vocabulary growth on a corpus. A method of parameter estimation by searching an optimal $\gamma$ is proposed, where a ``zeroth word'' is introduced technically for the calculation. The formulation and parameters are further discussed with several case studies.
A Two Parameters Equation for Word Rank-Frequency Relation
May 02, 2022
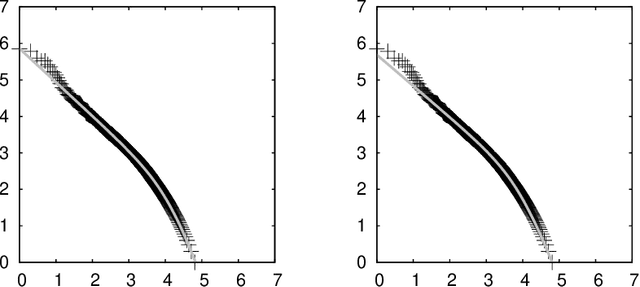
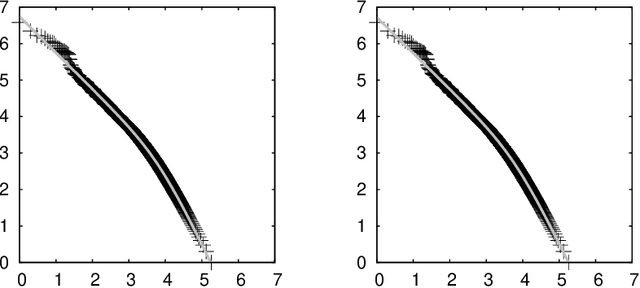
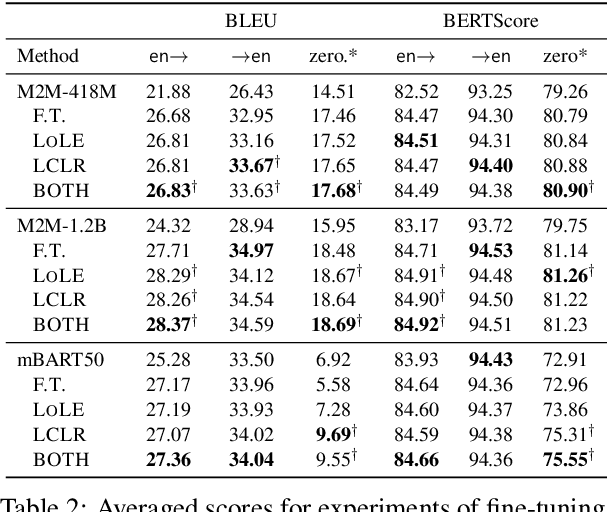
Let $f (\cdot)$ be the absolute frequency of words and $r$ be the rank of words in decreasing order of frequency, then the following function can fit the rank-frequency relation \[ f (r;s,t) = \left(\frac{r_{\tt max}}{r}\right)^{1-s} \left(\frac{r_{\tt max}+t \cdot r_{\tt exp}}{r+t \cdot r_{\tt exp}}\right)^{1+(1+t)s} \] where $r_{\tt max}$ and $r_{\tt exp}$ are the maximum and the expectation of the rank, respectively; $s>0$ and $t>0$ are parameters estimated from data. On well-behaved data, there should be $s<1$ and $s \cdot t < 1$.