Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Softmax for End-to-End Low-resource Multilingual Speech Recognition
Paper and Code

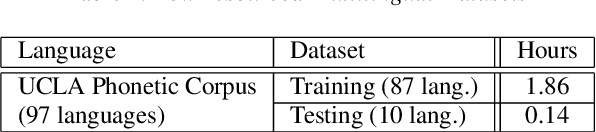
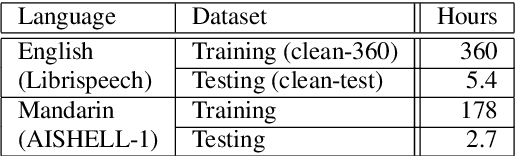
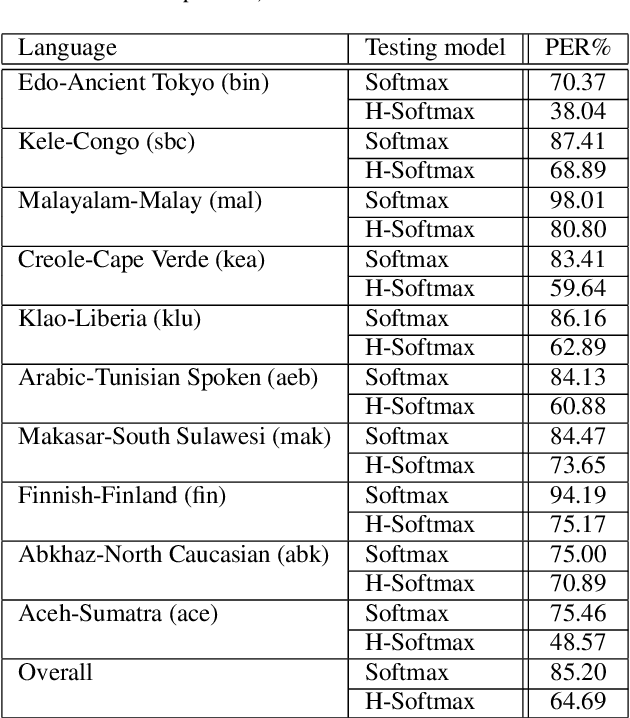
Low resource speech recognition has been long-suffering from insufficient training data. While neighbour languages are often used as assistant training data, it would be difficult for the model to induct similar units (character, subword, etc.) across the languages. In this paper, we assume similar units in neighbour language share similar term frequency and form a Huffman tree to perform multi-lingual hierarchical Softmax decoding. During decoding, the hierarchical structure can benefit the training of low-resource languages. Experimental results show the effectiveness of our method.
* 5 pages, Interspeech submission
View paper on