 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegistering Source Tokens to Target Language Spaces in Multilingual Neural Machine Translation
Jan 06, 2025



The multilingual neural machine translation (MNMT) enables arbitrary translations across multiple languages by training a model with limited parameters using parallel data only. However, the performance of such MNMT models still lags behind that of large language models (LLMs), limiting their practicality. In this work, we address this limitation by introducing registering to achieve the new state-of-the-art of decoder-only MNMT models. Specifically, we insert a set of artificial tokens specifying the target language, called registers, into the input sequence between the source and target tokens. By modifying the attention mask, the target token generation only pays attention to the activation of registers, representing the source tokens in the target language space. Experiments on EC-40, a large-scale benchmark, show that our method outperforms related methods driven by optimizing multilingual representations. We further scale up and collect 9.3 billion sentence pairs across 24 languages from public datasets to pre-train two models, namely MITRE (multilingual translation with registers). One of them, MITRE-913M, outperforms NLLB-3.3B, achieves comparable performance with commercial LLMs, and shows strong adaptability in fine-tuning. Finally, we open-source our models to facilitate further research and development in MNMT: https://github.com/zhiqu22/mitre.
Improving Language Transfer Capability of Decoder-only Architecture in Multilingual Neural Machine Translation
Dec 03, 2024



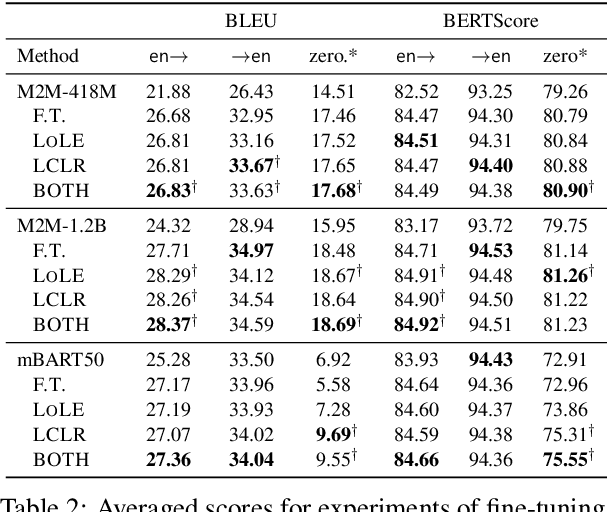
Existing multilingual neural machine translation (MNMT) approaches mainly focus on improving models with the encoder-decoder architecture to translate multiple languages. However, decoder-only architecture has been explored less in MNMT due to its underperformance when trained on parallel data solely. In this work, we attribute the issue of the decoder-only architecture to its lack of language transfer capability. Specifically, the decoder-only architecture is insufficient in encoding source tokens with the target language features. We propose dividing the decoding process into two stages so that target tokens are explicitly excluded in the first stage to implicitly boost the transfer capability across languages. Additionally, we impose contrastive learning on translation instructions, resulting in improved performance in zero-shot translation. We conduct experiments on TED-19 and OPUS-100 datasets, considering both training from scratch and fine-tuning scenarios. Experimental results show that, compared to the encoder-decoder architecture, our methods not only perform competitively in supervised translations but also achieve improvements of up to 3.39 BLEU, 6.99 chrF++, 3.22 BERTScore, and 4.81 COMET in zero-shot translations.
Exploring Intrinsic Language-specific Subspaces in Fine-tuning Multilingual Neural Machine Translation
Sep 08, 2024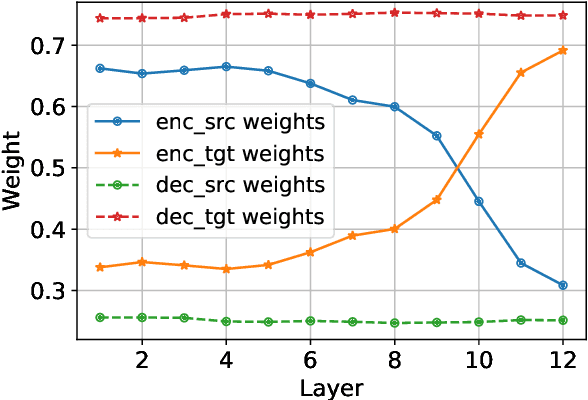
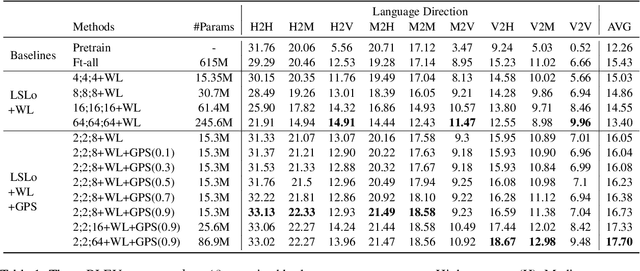

Multilingual neural machine translation models support fine-tuning hundreds of languages simultaneously. However, fine-tuning on full parameters solely is inefficient potentially leading to negative interactions among languages. In this work, we demonstrate that the fine-tuning for a language occurs in its intrinsic language-specific subspace with a tiny fraction of entire parameters. Thus, we propose language-specific LoRA to isolate intrinsic language-specific subspaces. Furthermore, we propose architecture learning techniques and introduce a gradual pruning schedule during fine-tuning to exhaustively explore the optimal setting and the minimal intrinsic subspaces for each language, resulting in a lightweight yet effective fine-tuning procedure. The experimental results on a 12-language subset and a 30-language subset of FLORES-101 show that our methods not only outperform full-parameter fine-tuning up to 2.25 spBLEU scores but also reduce trainable parameters to $0.4\%$ for high and medium-resource languages and $1.6\%$ for low-resource ones.
SynopGround: A Large-Scale Dataset for Multi-Paragraph Video Grounding from TV Dramas and Synopses
Aug 07, 2024
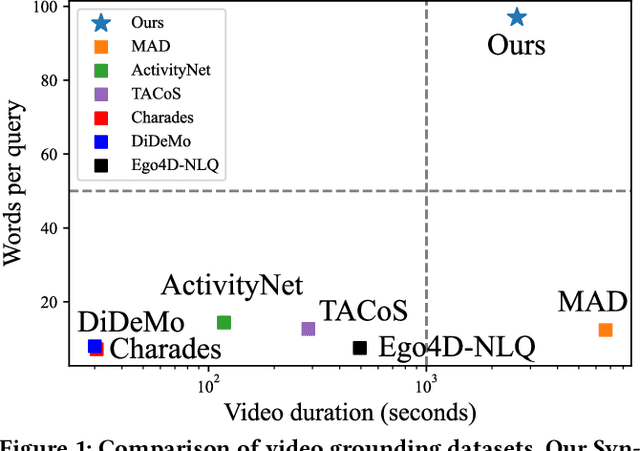
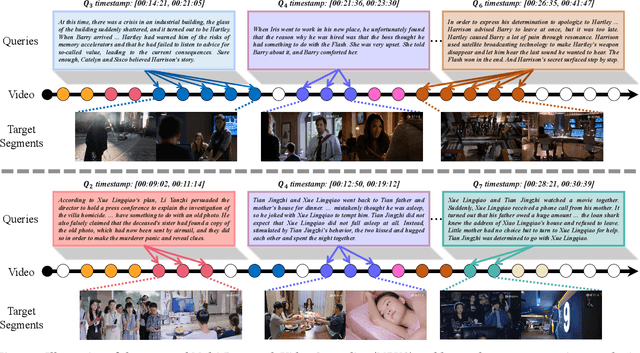
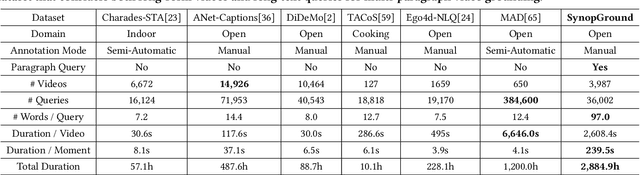
Video grounding is a fundamental problem in multimodal content understanding, aiming to localize specific natural language queries in an untrimmed video. However, current video grounding datasets merely focus on simple events and are either limited to shorter videos or brief sentences, which hinders the model from evolving toward stronger multimodal understanding capabilities. To address these limitations, we present a large-scale video grounding dataset named SynopGround, in which more than 2800 hours of videos are sourced from popular TV dramas and are paired with accurately localized human-written synopses. Each paragraph in the synopsis serves as a language query and is manually annotated with precise temporal boundaries in the long video. These paragraph queries are tightly correlated to each other and contain a wealth of abstract expressions summarizing video storylines and specific descriptions portraying event details, which enables the model to learn multimodal perception on more intricate concepts over longer context dependencies. Based on the dataset, we further introduce a more complex setting of video grounding dubbed Multi-Paragraph Video Grounding (MPVG), which takes as input multiple paragraphs and a long video for grounding each paragraph query to its temporal interval. In addition, we propose a novel Local-Global Multimodal Reasoner (LGMR) to explicitly model the local-global structures of long-term multimodal inputs for MPVG. Our method provides an effective baseline solution to the multi-paragraph video grounding problem. Extensive experiments verify the proposed model's effectiveness as well as its superiority in long-term multi-paragraph video grounding over prior state-of-the-arts. Dataset and code are publicly available. Project page: https://synopground.github.io/.
Languages Transferred Within the Encoder: On Representation Transfer in Zero-Shot Multilingual Translation
Jun 12, 2024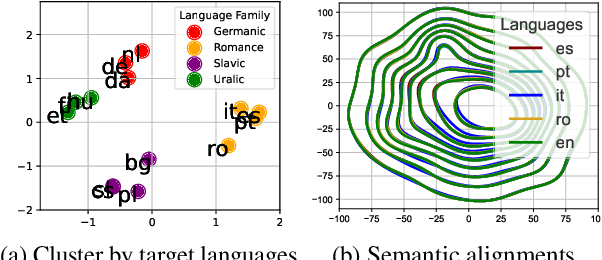
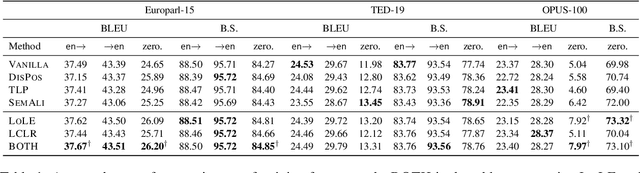
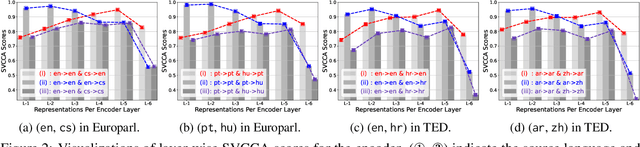
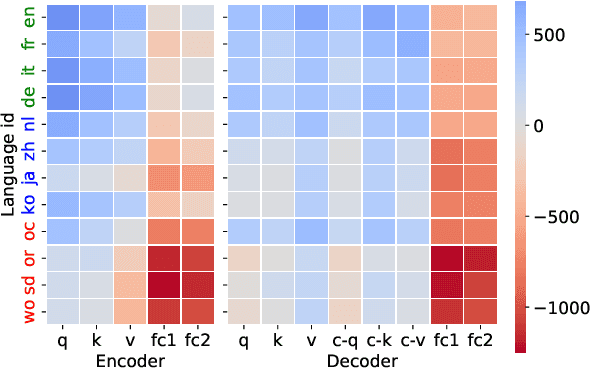
Understanding representation transfer in multilingual neural machine translation can reveal the representational issue causing the zero-shot translation deficiency. In this work, we introduce the identity pair, a sentence translated into itself, to address the lack of the base measure in multilingual investigations, as the identity pair represents the optimal state of representation among any language transfers. In our analysis, we demonstrate that the encoder transfers the source language to the representational subspace of the target language instead of the language-agnostic state. Thus, the zero-shot translation deficiency arises because representations are entangled with other languages and are not transferred effectively to the target language. Based on our findings, we propose two methods: 1) low-rank language-specific embedding at the encoder, and 2) language-specific contrastive learning of the representation at the decoder. The experimental results on Europarl-15, TED-19, and OPUS-100 datasets show that our methods substantially enhance the performance of zero-shot translations by improving language transfer capacity, thereby providing practical evidence to support our conclusions.
Sharing Parameter by Conjugation for Knowledge Graph Embeddings in Complex Space
Apr 18, 2024A Knowledge Graph (KG) is the directed graphical representation of entities and relations in the real world. KG can be applied in diverse Natural Language Processing (NLP) tasks where knowledge is required. The need to scale up and complete KG automatically yields Knowledge Graph Embedding (KGE), a shallow machine learning model that is suffering from memory and training time consumption issues. To mitigate the computational load, we propose a parameter-sharing method, i.e., using conjugate parameters for complex numbers employed in KGE models. Our method improves memory efficiency by 2x in relation embedding while achieving comparable performance to the state-of-the-art non-conjugate models, with faster, or at least comparable, training time. We demonstrated the generalizability of our method on two best-performing KGE models $5^{\bigstar}\mathrm{E}$ and $\mathrm{ComplEx}$ on five benchmark datasets.
Cross-lingual Contextualized Phrase Retrieval
Mar 25, 2024Phrase-level dense retrieval has shown many appealing characteristics in downstream NLP tasks by leveraging the fine-grained information that phrases offer. In our work, we propose a new task formulation of dense retrieval, cross-lingual contextualized phrase retrieval, which aims to augment cross-lingual applications by addressing polysemy using context information. However, the lack of specific training data and models are the primary challenges to achieve our goal. As a result, we extract pairs of cross-lingual phrases using word alignment information automatically induced from parallel sentences. Subsequently, we train our Cross-lingual Contextualized Phrase Retriever (CCPR) using contrastive learning, which encourages the hidden representations of phrases with similar contexts and semantics to align closely. Comprehensive experiments on both the cross-lingual phrase retrieval task and a downstream task, i.e, machine translation, demonstrate the effectiveness of CCPR. On the phrase retrieval task, CCPR surpasses baselines by a significant margin, achieving a top-1 accuracy that is at least 13 points higher. When utilizing CCPR to augment the large-language-model-based translator, it achieves average gains of 0.7 and 1.5 in BERTScore for translations from X=>En and vice versa, respectively, on WMT16 dataset. Our code and data are available at \url{https://github.com/ghrua/ccpr_release}.
Adapting to Non-Centered Languages for Zero-shot Multilingual Translation
Sep 09, 2022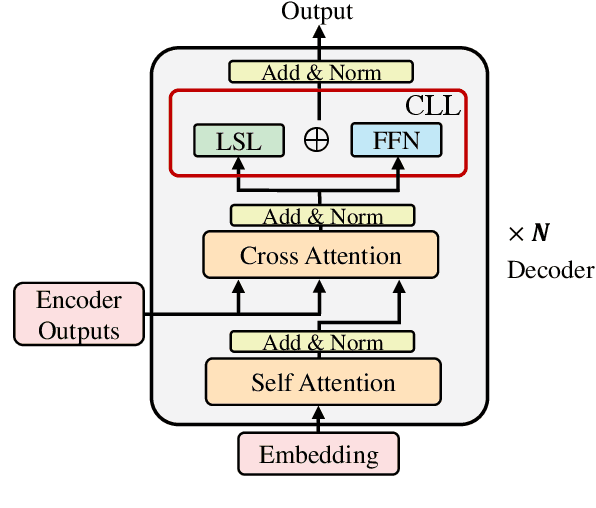
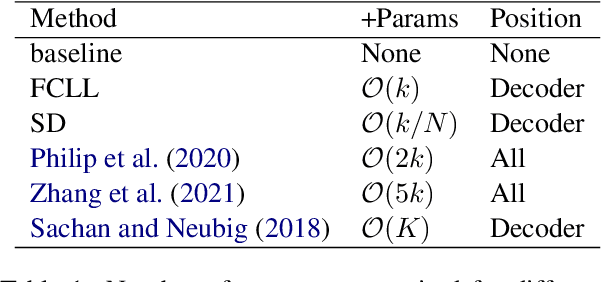


Multilingual neural machine translation can translate unseen language pairs during training, i.e. zero-shot translation. However, the zero-shot translation is always unstable. Although prior works attributed the instability to the domination of central language, e.g. English, we supplement this viewpoint with the strict dependence of non-centered languages. In this work, we propose a simple, lightweight yet effective language-specific modeling method by adapting to non-centered languages and combining the shared information and the language-specific information to counteract the instability of zero-shot translation. Experiments with Transformer on IWSLT17, Europarl, TED talks, and OPUS-100 datasets show that our method not only performs better than strong baselines in centered data conditions but also can easily fit non-centered data conditions. By further investigating the layer attribution, we show that our proposed method can disentangle the coupled representation in the correct direction.