 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVC-Bench: Pioneering the Video Connecting Benchmark with a Dataset and Evaluation Metrics
Jan 27, 2026While current video generation focuses on text or image conditions, practical applications like video editing and vlogging often need to seamlessly connect separate clips. In our work, we introduce Video Connecting, an innovative task that aims to generate smooth intermediate video content between given start and end clips. However, the absence of standardized evaluation benchmarks has hindered the development of this task. To bridge this gap, we proposed VC-Bench, a novel benchmark specifically designed for video connecting. It includes 1,579 high-quality videos collected from public platforms, covering 15 main categories and 72 subcategories to ensure diversity and structure. VC-Bench focuses on three core aspects: Video Quality Score VQS, Start-End Consistency Score SECS, and Transition Smoothness Score TSS. Together, they form a comprehensive framework that moves beyond conventional quality-only metrics. We evaluated multiple state-of-the-art video generation models on VC-Bench. Experimental results reveal significant limitations in maintaining start-end consistency and transition smoothness, leading to lower overall coherence and fluidity. We expect that VC-Bench will serve as a pioneering benchmark to inspire and guide future research in video connecting. The evaluation metrics and dataset are publicly available at: https://anonymous.4open.science/r/VC-Bench-1B67/.
DivLogicEval: A Framework for Benchmarking Logical Reasoning Evaluation in Large Language Models
Sep 19, 2025Logic reasoning in natural language has been recognized as an important measure of human intelligence for Large Language Models (LLMs). Popular benchmarks may entangle multiple reasoning skills and thus provide unfaithful evaluations on the logic reasoning skill. Meanwhile, existing logic reasoning benchmarks are limited in language diversity and their distributions are deviated from the distribution of an ideal logic reasoning benchmark, which may lead to biased evaluation results. This paper thereby proposes a new classical logic benchmark DivLogicEval, consisting of natural sentences composed of diverse statements in a counterintuitive way. To ensure a more reliable evaluation, we also introduce a new evaluation metric that mitigates the influence of bias and randomness inherent in LLMs. Through experiments, we demonstrate the extent to which logical reasoning is required to answer the questions in DivLogicEval and compare the performance of different popular LLMs in conducting logical reasoning.
DBudgetKV: Dynamic Budget in KV Cache Compression for Ensuring Optimal Performance
Feb 24, 2025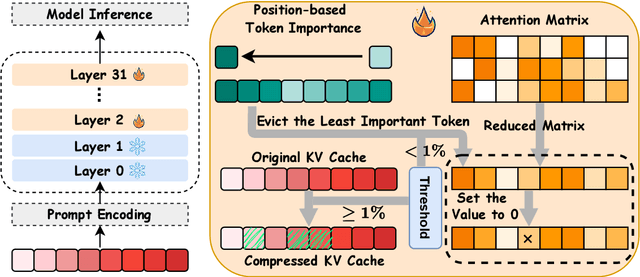
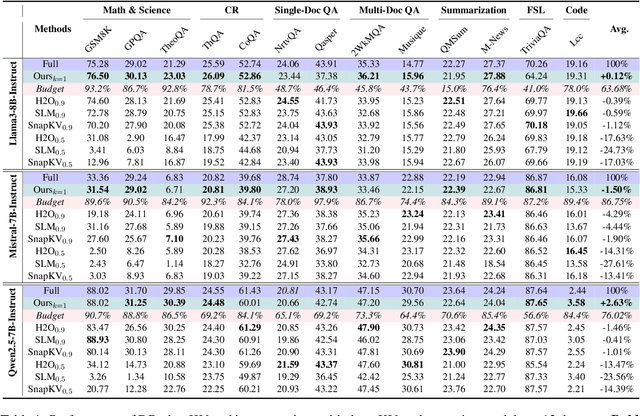
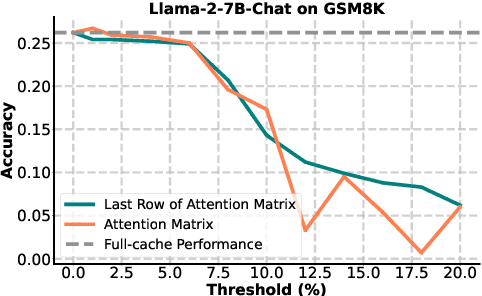
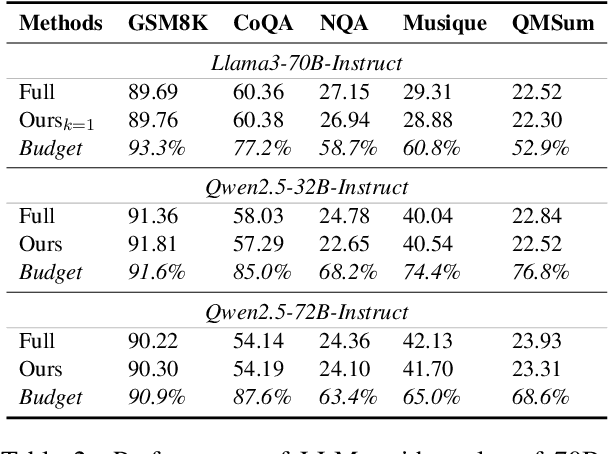
To alleviate memory burden during inference of large language models (LLMs), numerous studies have focused on compressing the KV cache by exploring aspects such as attention sparsity. However, these techniques often require a pre-defined cache budget; as the optimal budget varies with different input lengths and task types, it limits their practical deployment accepting open-domain instructions. To address this limitation, we propose a new KV cache compression objective: to always ensure the full-cache performance regardless of specific inputs, while maximizing KV cache pruning as much as possible. To achieve this goal, we introduce a novel KV cache compression method dubbed DBudgetKV, which features an attention-based metric to signal when the remaining KV cache is unlikely to match the full-cache performance, then halting the pruning process. Empirical evaluation spanning diverse context lengths, task types, and model sizes suggests that our method achieves lossless KV pruning effectively and robustly, exceeding 25% compression ratio on average. Furthermore, our method is easy to integrate within LLM inference, not only optimizing memory space, but also showing reduced inference time compared to existing methods.
The Stochastic Parrot on LLM's Shoulder: A Summative Assessment of Physical Concept Understanding
Feb 13, 2025



In a systematic way, we investigate a widely asked question: Do LLMs really understand what they say?, which relates to the more familiar term Stochastic Parrot. To this end, we propose a summative assessment over a carefully designed physical concept understanding task, PhysiCo. Our task alleviates the memorization issue via the usage of grid-format inputs that abstractly describe physical phenomena. The grids represents varying levels of understanding, from the core phenomenon, application examples to analogies to other abstract patterns in the grid world. A comprehensive study on our task demonstrates: (1) state-of-the-art LLMs, including GPT-4o, o1 and Gemini 2.0 flash thinking, lag behind humans by ~40%; (2) the stochastic parrot phenomenon is present in LLMs, as they fail on our grid task but can describe and recognize the same concepts well in natural language; (3) our task challenges the LLMs due to intrinsic difficulties rather than the unfamiliar grid format, as in-context learning and fine-tuning on same formatted data added little to their performance.
Understanding LLMs' Fluid Intelligence Deficiency: An Analysis of the ARC Task
Feb 11, 2025



While LLMs have exhibited strong performance on various NLP tasks, it is noteworthy that most of these tasks rely on utilizing the vast amount of knowledge encoded in LLMs' parameters, rather than solving new problems without prior knowledge. In cognitive research, the latter ability is referred to as fluid intelligence, which is considered to be critical for assessing human intelligence. Recent research on fluid intelligence assessments has highlighted significant deficiencies in LLMs' abilities. In this paper, we analyze the challenges LLMs face in demonstrating fluid intelligence through controlled experiments, using the most representative ARC task as an example. Our study revealed three major limitations in existing LLMs: limited ability for skill composition, unfamiliarity with abstract input formats, and the intrinsic deficiency of left-to-right decoding. Our data and code can be found in https://wujunjie1998.github.io/araoc-benchmark.github.io/.
Large Language Models Can Self-Improve in Long-context Reasoning
Nov 12, 2024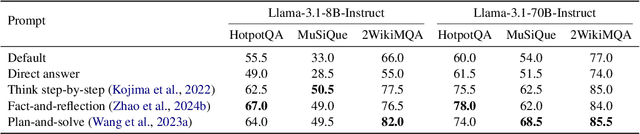
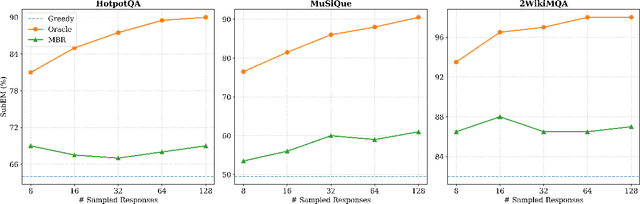
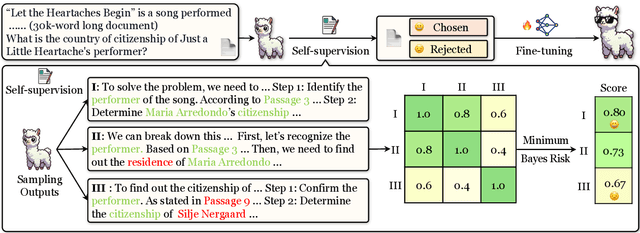
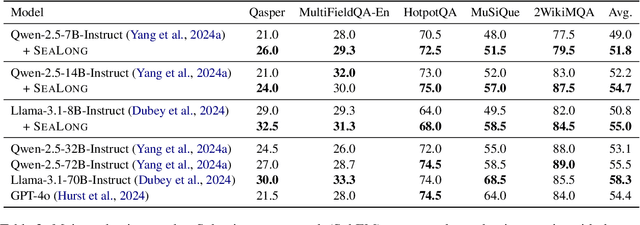
Large language models (LLMs) have achieved substantial progress in processing long contexts but still struggle with long-context reasoning. Existing approaches typically involve fine-tuning LLMs with synthetic data, which depends on annotations from human experts or advanced models like GPT-4, thus restricting further advancements. To address this issue, we investigate the potential for LLMs to self-improve in long-context reasoning and propose \ours, an approach specifically designed for this purpose. This approach is straightforward: we sample multiple outputs for each question, score them with Minimum Bayes Risk, and then apply supervised fine-tuning or preference optimization based on these outputs. Extensive experiments on several leading LLMs demonstrate the effectiveness of \ours, with an absolute improvement of $4.2$ points for Llama-3.1-8B-Instruct. Furthermore, \ours achieves superior performance compared to prior approaches that depend on data produced by human experts or advanced models. We anticipate that this work will open new avenues for self-improvement techniques in long-context scenarios, which are essential for the continual advancement of LLMs.
Selection-p: Self-Supervised Task-Agnostic Prompt Compression for Faithfulness and Transferability
Oct 15, 2024
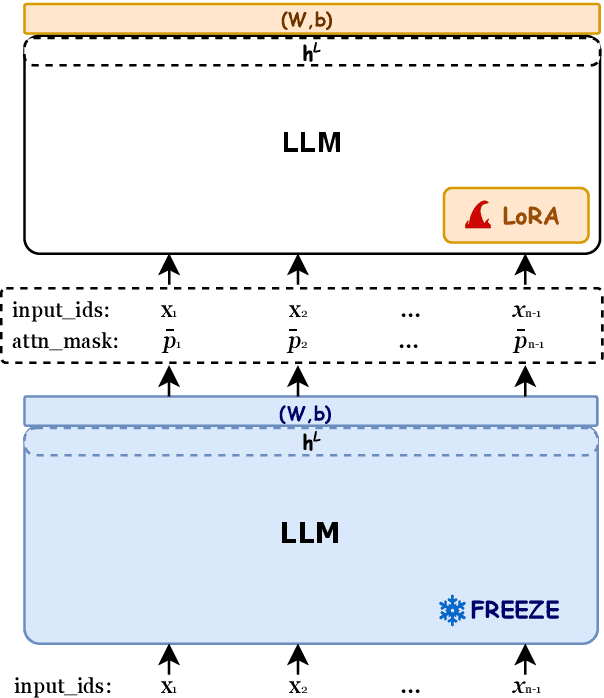


Large Language Models (LLMs) have demonstrated impressive capabilities in a wide range of natural language processing tasks when leveraging in-context learning. To mitigate the additional computational and financial costs associated with in-context learning, several prompt compression methods have been proposed to compress the in-context learning prompts. Despite their success, these methods face challenges with transferability due to model-specific compression, or rely on external training data, such as GPT-4. In this paper, we investigate the ability of LLMs to develop a unified compression method that discretizes uninformative tokens, utilizing a self-supervised pre-training technique. By introducing a small number of parameters during the continual pre-training, the proposed Selection-p produces a probability for each input token, indicating whether to preserve or discard it. Experiments show Selection-p achieves state-of-the-art performance across numerous classification tasks, achieving compression rates of up to 10 times while experiencing only a marginal 0.8% decrease in performance. Moreover, it exhibits superior transferability to different models compared to prior work. Additionally, we further analyze how Selection-p helps maintain performance on in-context learning with long contexts.
A Survey on the Honesty of Large Language Models
Sep 27, 2024



Honesty is a fundamental principle for aligning large language models (LLMs) with human values, requiring these models to recognize what they know and don't know and be able to faithfully express their knowledge. Despite promising, current LLMs still exhibit significant dishonest behaviors, such as confidently presenting wrong answers or failing to express what they know. In addition, research on the honesty of LLMs also faces challenges, including varying definitions of honesty, difficulties in distinguishing between known and unknown knowledge, and a lack of comprehensive understanding of related research. To address these issues, we provide a survey on the honesty of LLMs, covering its clarification, evaluation approaches, and strategies for improvement. Moreover, we offer insights for future research, aiming to inspire further exploration in this important area.
TF-Attack: Transferable and Fast Adversarial Attacks on Large Language Models
Aug 26, 2024With the great advancements in large language models (LLMs), adversarial attacks against LLMs have recently attracted increasing attention. We found that pre-existing adversarial attack methodologies exhibit limited transferability and are notably inefficient, particularly when applied to LLMs. In this paper, we analyze the core mechanisms of previous predominant adversarial attack methods, revealing that 1) the distributions of importance score differ markedly among victim models, restricting the transferability; 2) the sequential attack processes induces substantial time overheads. Based on the above two insights, we introduce a new scheme, named TF-Attack, for Transferable and Fast adversarial attacks on LLMs. TF-Attack employs an external LLM as a third-party overseer rather than the victim model to identify critical units within sentences. Moreover, TF-Attack introduces the concept of Importance Level, which allows for parallel substitutions of attacks. We conduct extensive experiments on 6 widely adopted benchmarks, evaluating the proposed method through both automatic and human metrics. Results show that our method consistently surpasses previous methods in transferability and delivers significant speed improvements, up to 20 times faster than earlier attack strategies.
An Energy-based Model for Word-level AutoCompletion in Computer-aided Translation
Jul 29, 2024Word-level AutoCompletion(WLAC) is a rewarding yet challenging task in Computer-aided Translation. Existing work addresses this task through a classification model based on a neural network that maps the hidden vector of the input context into its corresponding label (i.e., the candidate target word is treated as a label). Since the context hidden vector itself does not take the label into account and it is projected to the label through a linear classifier, the model can not sufficiently leverage valuable information from the source sentence as verified in our experiments, which eventually hinders its overall performance. To alleviate this issue, this work proposes an energy-based model for WLAC, which enables the context hidden vector to capture crucial information from the source sentence. Unfortunately, training and inference suffer from efficiency and effectiveness challenges, thereby we employ three simple yet effective strategies to put our model into practice. Experiments on four standard benchmarks demonstrate that our reranking-based approach achieves substantial improvements (about 6.07%) over the previous state-of-the-art model. Further analyses show that each strategy of our approach contributes to the final performance.