 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models Can Self-Improve in Long-context Reasoning
Paper and Code
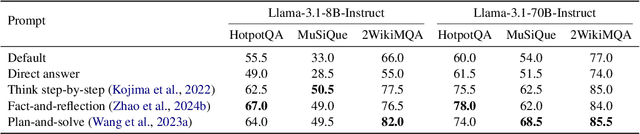
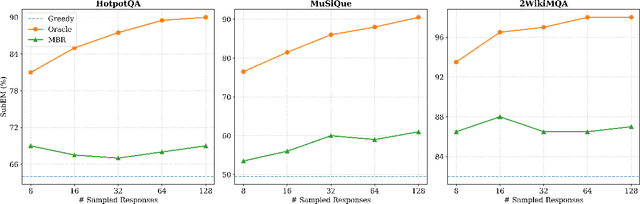
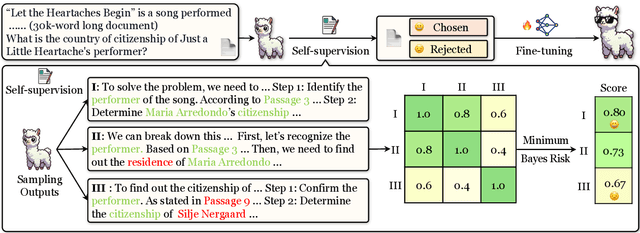
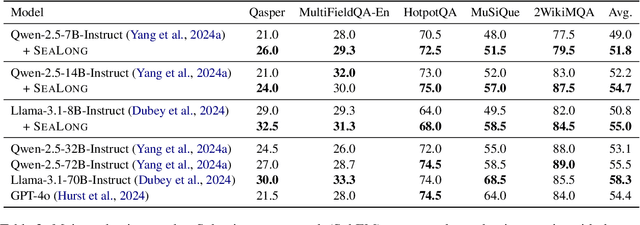
Large language models (LLMs) have achieved substantial progress in processing long contexts but still struggle with long-context reasoning. Existing approaches typically involve fine-tuning LLMs with synthetic data, which depends on annotations from human experts or advanced models like GPT-4, thus restricting further advancements. To address this issue, we investigate the potential for LLMs to self-improve in long-context reasoning and propose \ours, an approach specifically designed for this purpose. This approach is straightforward: we sample multiple outputs for each question, score them with Minimum Bayes Risk, and then apply supervised fine-tuning or preference optimization based on these outputs. Extensive experiments on several leading LLMs demonstrate the effectiveness of \ours, with an absolute improvement of $4.2$ points for Llama-3.1-8B-Instruct. Furthermore, \ours achieves superior performance compared to prior approaches that depend on data produced by human experts or advanced models. We anticipate that this work will open new avenues for self-improvement techniques in long-context scenarios, which are essential for the continual advancement of LLMs.