 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Abstract to Contextual: What LLMs Still Cannot Do in Mathematics
Jan 30, 2026Large language models now solve many benchmark math problems at near-expert levels, yet this progress has not fully translated into reliable performance in real-world applications. We study this gap through contextual mathematical reasoning, where the mathematical core must be formulated from descriptive scenarios. We introduce ContextMATH, a benchmark that repurposes AIME and MATH-500 problems into two contextual settings: Scenario Grounding (SG), which embeds abstract problems into realistic narratives without increasing reasoning complexity, and Complexity Scaling (CS), which transforms explicit conditions into sub-problems to capture how constraints often appear in practice. Evaluating 61 proprietary and open-source models, we observe sharp drops: on average, open-source models decline by 13 and 34 points on SG and CS, while proprietary models drop by 13 and 20. Error analysis shows that errors are dominated by incorrect problem formulation, with formulation accuracy declining as original problem difficulty increases. Correct formulation emerges as a prerequisite for success, and its sufficiency improves with model scale, indicating that larger models advance in both understanding and reasoning. Nevertheless, formulation and reasoning remain two complementary bottlenecks that limit contextual mathematical problem solving. Finally, we find that fine-tuning with scenario data improves performance, whereas formulation-only training is ineffective. However, performance gaps are only partially alleviated, highlighting contextual mathematical reasoning as a central unsolved challenge for LLMs.
Stephanie2: Thinking, Waiting, and Making Decisions Like Humans in Step-by-Step AI Social Chat
Jan 09, 2026Instant-messaging human social chat typically progresses through a sequence of short messages. Existing step-by-step AI chatting systems typically split a one-shot generation into multiple messages and send them sequentially, but they lack an active waiting mechanism and exhibit unnatural message pacing. In order to address these issues, we propose Stephanie2, a novel next-generation step-wise decision-making dialogue agent. With active waiting and message-pace adaptation, Stephanie2 explicitly decides at each step whether to send or wait, and models latency as the sum of thinking time and typing time to achieve more natural pacing. We further introduce a time-window-based dual-agent dialogue system to generate pseudo dialogue histories for human and automatic evaluations. Experiments show that Stephanie2 clearly outperforms Stephanie1 on metrics such as naturalness and engagement, and achieves a higher pass rate on human evaluation with the role identification Turing test.
Improving Multi-step RAG with Hypergraph-based Memory for Long-Context Complex Relational Modeling
Dec 30, 2025Multi-step retrieval-augmented generation (RAG) has become a widely adopted strategy for enhancing large language models (LLMs) on tasks that demand global comprehension and intensive reasoning. Many RAG systems incorporate a working memory module to consolidate retrieved information. However, existing memory designs function primarily as passive storage that accumulates isolated facts for the purpose of condensing the lengthy inputs and generating new sub-queries through deduction. This static nature overlooks the crucial high-order correlations among primitive facts, the compositions of which can often provide stronger guidance for subsequent steps. Therefore, their representational strength and impact on multi-step reasoning and knowledge evolution are limited, resulting in fragmented reasoning and weak global sense-making capacity in extended contexts. We introduce HGMem, a hypergraph-based memory mechanism that extends the concept of memory beyond simple storage into a dynamic, expressive structure for complex reasoning and global understanding. In our approach, memory is represented as a hypergraph whose hyperedges correspond to distinct memory units, enabling the progressive formation of higher-order interactions within memory. This mechanism connects facts and thoughts around the focal problem, evolving into an integrated and situated knowledge structure that provides strong propositions for deeper reasoning in subsequent steps. We evaluate HGMem on several challenging datasets designed for global sense-making. Extensive experiments and in-depth analyses show that our method consistently improves multi-step RAG and substantially outperforms strong baseline systems across diverse tasks.
LNE-Blocking: An Efficient Framework for Contamination Mitigation Evaluation on Large Language Models
Sep 18, 2025The problem of data contamination is now almost inevitable during the development of large language models (LLMs), with the training data commonly integrating those evaluation benchmarks even unintentionally. This problem subsequently makes it hard to benchmark LLMs fairly. Instead of constructing contamination-free datasets (quite hard), we propose a novel framework, \textbf{LNE-Blocking}, to restore model performance prior to contamination on potentially leaked datasets. Our framework consists of two components: contamination detection and disruption operation. For the prompt, the framework first uses the contamination detection method, \textbf{LNE}, to assess the extent of contamination in the model. Based on this, it adjusts the intensity of the disruption operation, \textbf{Blocking}, to elicit non-memorized responses from the model. Our framework is the first to efficiently restore the model's greedy decoding performance. This comes with a strong performance on multiple datasets with potential leakage risks, and it consistently achieves stable recovery results across different models and varying levels of data contamination. We release the code at https://github.com/RuijieH/LNE-Blocking to facilitate research.
RePO: Replay-Enhanced Policy Optimization
Jun 11, 2025Reinforcement learning (RL) is vital for optimizing large language models (LLMs). Recent Group Relative Policy Optimization (GRPO) estimates advantages using multiple on-policy outputs per prompt, leading to high computational costs and low data efficiency. To address this, we introduce Replay-Enhanced Policy Optimization (RePO), which leverages diverse replay strategies to retrieve off-policy samples from a replay buffer, allowing policy optimization based on a broader and more diverse set of samples for each prompt. Experiments on five LLMs across seven mathematical reasoning benchmarks demonstrate that RePO achieves absolute average performance gains of $18.4$ and $4.1$ points for Qwen2.5-Math-1.5B and Qwen3-1.7B, respectively, compared to GRPO. Further analysis indicates that RePO increases computational cost by $15\%$ while raising the number of effective optimization steps by $48\%$ for Qwen3-1.7B, with both on-policy and off-policy sample numbers set to $8$. The repository can be accessed at https://github.com/SihengLi99/RePO.
InComeS: Integrating Compression and Selection Mechanisms into LLMs for Efficient Model Editing
May 28, 2025Although existing model editing methods perform well in recalling exact edit facts, they often struggle in complex scenarios that require deeper semantic understanding rather than mere knowledge regurgitation. Leveraging the strong contextual reasoning abilities of large language models (LLMs), in-context learning (ICL) becomes a promising editing method by comprehending edit information through context encoding. However, this method is constrained by the limited context window of LLMs, leading to degraded performance and efficiency as the number of edits increases. To overcome this limitation, we propose InComeS, a flexible framework that enhances LLMs' ability to process editing contexts through explicit compression and selection mechanisms. Specifically, InComeS compresses each editing context into the key-value (KV) cache of a special gist token, enabling efficient handling of multiple edits without being restricted by the model's context window. Furthermore, specialized cross-attention modules are added to dynamically select the most relevant information from the gist pools, enabling adaptive and effective utilization of edit information. We conduct experiments on diverse model editing benchmarks with various editing formats, and the results demonstrate the effectiveness and efficiency of our method.
SeqPO-SiMT: Sequential Policy Optimization for Simultaneous Machine Translation
May 27, 2025



We present Sequential Policy Optimization for Simultaneous Machine Translation (SeqPO-SiMT), a new policy optimization framework that defines the simultaneous machine translation (SiMT) task as a sequential decision making problem, incorporating a tailored reward to enhance translation quality while reducing latency. In contrast to popular Reinforcement Learning from Human Feedback (RLHF) methods, such as PPO and DPO, which are typically applied in single-step tasks, SeqPO-SiMT effectively tackles the multi-step SiMT task. This intuitive framework allows the SiMT LLMs to simulate and refine the SiMT process using a tailored reward. We conduct experiments on six datasets from diverse domains for En to Zh and Zh to En SiMT tasks, demonstrating that SeqPO-SiMT consistently achieves significantly higher translation quality with lower latency. In particular, SeqPO-SiMT outperforms the supervised fine-tuning (SFT) model by 1.13 points in COMET, while reducing the Average Lagging by 6.17 in the NEWSTEST2021 En to Zh dataset. While SiMT operates with far less context than offline translation, the SiMT results of SeqPO-SiMT on 7B LLM surprisingly rival the offline translation of high-performing LLMs, including Qwen-2.5-7B-Instruct and LLaMA-3-8B-Instruct.
InfiniteICL: Breaking the Limit of Context Window Size via Long Short-term Memory Transformation
Apr 03, 2025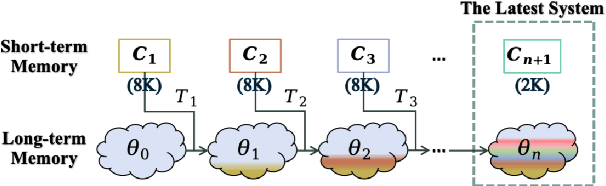
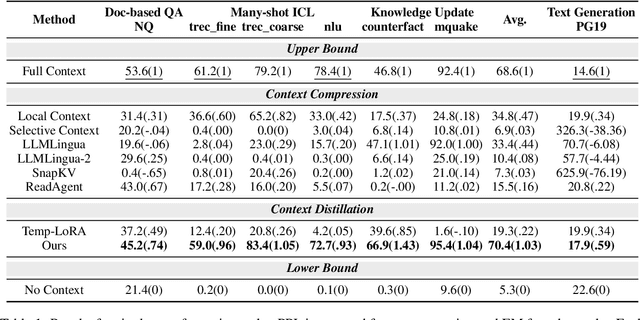
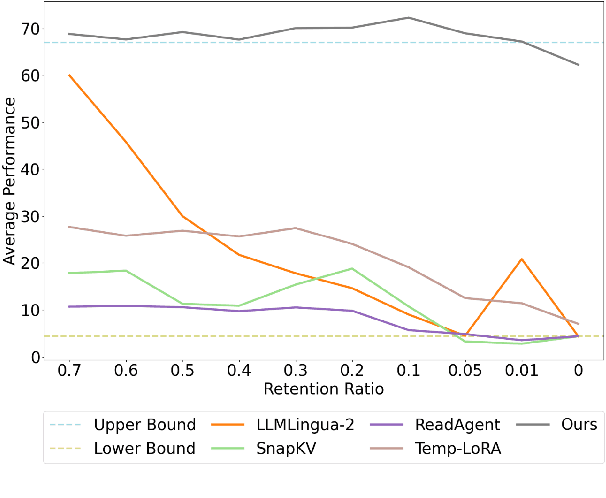
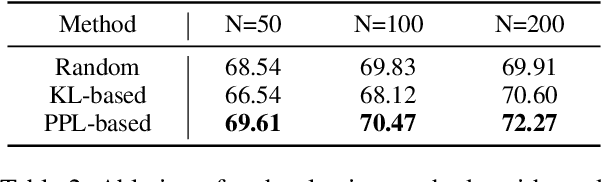
In-context learning (ICL) is critical for large language models (LLMs), but its effectiveness is constrained by finite context windows, particularly in ultra-long contexts. To overcome this, we introduce InfiniteICL, a framework that parallels context and parameters in LLMs with short- and long-term memory in human cognitive systems, focusing on transforming temporary context knowledge into permanent parameter updates. This approach significantly reduces memory usage, maintains robust performance across varying input lengths, and theoretically enables infinite context integration through the principles of context knowledge elicitation, selection, and consolidation. Evaluations demonstrate that our method reduces context length by 90% while achieving 103% average performance of full-context prompting across fact recall, grounded reasoning, and skill acquisition tasks. When conducting sequential multi-turn transformations on complex, real-world contexts (with length up to 2M tokens), our approach surpasses full-context prompting while using only 0.4% of the original contexts. These findings highlight InfiniteICL's potential to enhance the scalability and efficiency of LLMs by breaking the limitations of conventional context window sizes.
Multi-LLM Collaborative Search for Complex Problem Solving
Feb 26, 2025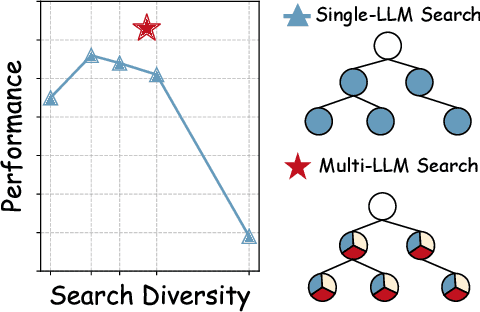


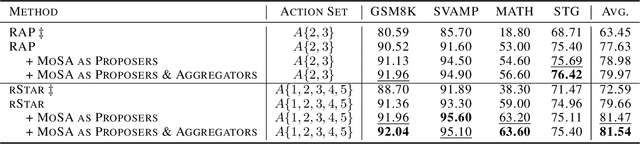
Large language models (LLMs) often struggle with complex reasoning tasks due to their limitations in addressing the vast reasoning space and inherent ambiguities of natural language. We propose the Mixture-of-Search-Agents (MoSA) paradigm, a novel approach leveraging the collective expertise of multiple LLMs to enhance search-based reasoning. MoSA integrates diverse reasoning pathways by combining independent exploration with iterative refinement among LLMs, mitigating the limitations of single-model approaches. Using Monte Carlo Tree Search (MCTS) as a backbone, MoSA enables multiple agents to propose and aggregate reasoning steps, resulting in improved accuracy. Our comprehensive evaluation across four reasoning benchmarks demonstrates MoSA's consistent performance improvements over single-agent and other multi-agent baselines, particularly in complex mathematical and commonsense reasoning tasks.
SWE-Fixer: Training Open-Source LLMs for Effective and Efficient GitHub Issue Resolution
Jan 09, 2025



Large Language Models (LLMs) have demonstrated remarkable proficiency across a variety of complex tasks. One significant application of LLMs is in tackling software engineering challenges, particularly in resolving real-world tasks on GitHub by fixing code based on the issues reported by the users. However, many current approaches rely on proprietary LLMs, which limits reproducibility, accessibility, and transparency. The critical components of LLMs for addressing software engineering issues and how their capabilities can be effectively enhanced remain unclear. To address these challenges, we introduce SWE-Fixer, a novel open-source LLM designed to effectively and efficiently resolve GitHub issues. SWE-Fixer comprises two essential modules: a code file retrieval module and a code editing module. The retrieval module employs BM25 along with a lightweight LLM model to achieve coarse-to-fine file retrieval. Subsequently, the code editing module utilizes the other LLM model to generate patches for the identified files. Then, to mitigate the lack of publicly available datasets, we compile an extensive dataset that includes 110K GitHub issues along with their corresponding patches, and train the two modules of SWE-Fixer separately. We assess our approach on the SWE-Bench Lite and Verified benchmarks, achieving state-of-the-art performance among open-source models with scores of 23.3% and 30.2%, respectively. These outcomes highlight the efficacy of our approach. We will make our model, dataset, and code publicly available at https://github.com/InternLM/SWE-Fixer.