 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClean Evaluations on Contaminated Visual Language Models
Oct 09, 2024
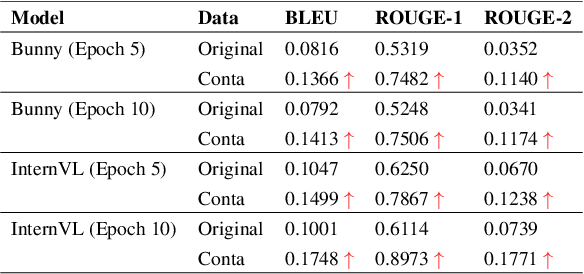
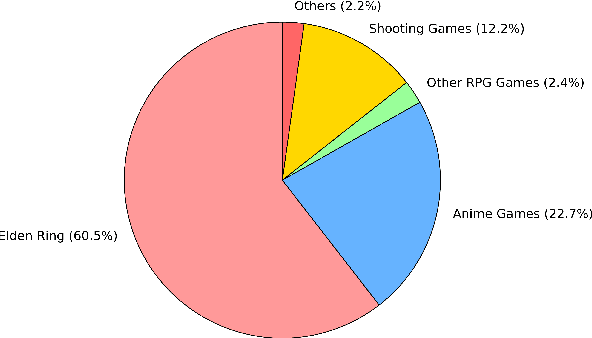
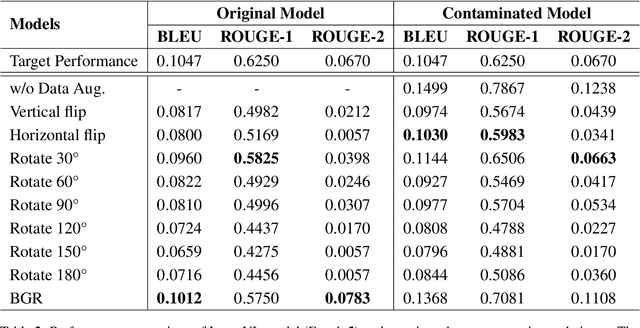
How to evaluate large language models (LLMs) cleanly has been established as an important research era to genuinely report the performance of possibly contaminated LLMs. Yet, how to cleanly evaluate the visual language models (VLMs) is an under-studied problem. We propose a novel approach to achieve such goals through data augmentation methods on the visual input information. We then craft a new visual clean evaluation benchmark with thousands of data instances. Through extensive experiments, we found that the traditional visual data augmentation methods are useful, but they are at risk of being used as a part of the training data as a workaround. We further propose using BGR augmentation to switch the colour channel of the visual information. We found that it is a simple yet effective method for reducing the effect of data contamination and fortunately, it is also harmful to be used as a data augmentation method during training. It means that it is hard to integrate such data augmentation into training by malicious trainers and it could be a promising technique to cleanly evaluate visual LLMs. Our code, data, and model weights will be released upon publication.