 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Abstract to Contextual: What LLMs Still Cannot Do in Mathematics
Jan 30, 2026Large language models now solve many benchmark math problems at near-expert levels, yet this progress has not fully translated into reliable performance in real-world applications. We study this gap through contextual mathematical reasoning, where the mathematical core must be formulated from descriptive scenarios. We introduce ContextMATH, a benchmark that repurposes AIME and MATH-500 problems into two contextual settings: Scenario Grounding (SG), which embeds abstract problems into realistic narratives without increasing reasoning complexity, and Complexity Scaling (CS), which transforms explicit conditions into sub-problems to capture how constraints often appear in practice. Evaluating 61 proprietary and open-source models, we observe sharp drops: on average, open-source models decline by 13 and 34 points on SG and CS, while proprietary models drop by 13 and 20. Error analysis shows that errors are dominated by incorrect problem formulation, with formulation accuracy declining as original problem difficulty increases. Correct formulation emerges as a prerequisite for success, and its sufficiency improves with model scale, indicating that larger models advance in both understanding and reasoning. Nevertheless, formulation and reasoning remain two complementary bottlenecks that limit contextual mathematical problem solving. Finally, we find that fine-tuning with scenario data improves performance, whereas formulation-only training is ineffective. However, performance gaps are only partially alleviated, highlighting contextual mathematical reasoning as a central unsolved challenge for LLMs.
Geometric-Mean Policy Optimization
Jul 28, 2025Recent advancements, such as Group Relative Policy Optimization (GRPO), have enhanced the reasoning capabilities of large language models by optimizing the arithmetic mean of token-level rewards. However, GRPO suffers from unstable policy updates when processing tokens with outlier importance-weighted rewards, which manifests as extreme importance sampling ratios during training, i.e., the ratio between the sampling probabilities assigned to a token by the current and old policies. In this work, we propose Geometric-Mean Policy Optimization (GMPO), a stabilized variant of GRPO. Instead of optimizing the arithmetic mean, GMPO maximizes the geometric mean of token-level rewards, which is inherently less sensitive to outliers and maintains a more stable range of importance sampling ratio. In addition, we provide comprehensive theoretical and experimental analysis to justify the design and stability benefits of GMPO. Beyond improved stability, GMPO-7B outperforms GRPO by an average of 4.1% on multiple mathematical benchmarks and 1.4% on multimodal reasoning benchmark, including AIME24, AMC, MATH500, OlympiadBench, Minerva, and Geometry3K. Code is available at https://github.com/callsys/GMPO.
Hugging Rain Man: A Novel Facial Action Units Dataset for Analyzing Atypical Facial Expressions in Children with Autism Spectrum Disorder
Nov 21, 2024



Children with Autism Spectrum Disorder (ASD) often exhibit atypical facial expressions. However, the specific objective facial features that underlie this subjective perception remain unclear. In this paper, we introduce a novel dataset, Hugging Rain Man (HRM), which includes facial action units (AUs) manually annotated by FACS experts for both children with ASD and typical development (TD). The dataset comprises a rich collection of posed and spontaneous facial expressions, totaling approximately 130,000 frames, along with 22 AUs, 10 Action Descriptors (ADs), and atypicality ratings. A statistical analysis of static images from the HRM reveals significant differences between the ASD and TD groups across multiple AUs and ADs when displaying the same emotional expressions, confirming that participants with ASD tend to demonstrate more irregular and diverse expression patterns. Subsequently, a temporal regression method was presented to analyze atypicality of dynamic sequences, thereby bridging the gap between subjective perception and objective facial characteristics. Furthermore, baseline results for AU detection are provided for future research reference. This work not only contributes to our understanding of the unique facial expression characteristics associated with ASD but also provides potential tools for ASD early screening. Portions of the dataset, features, and pretrained models are accessible at: \url{https://github.com/Jonas-DL/Hugging-Rain-Man}.
Harnessing Webpage UIs for Text-Rich Visual Understanding
Oct 17, 2024



Text-rich visual understanding-the ability to process environments where dense textual content is integrated with visuals-is crucial for multimodal large language models (MLLMs) to interact effectively with structured environments. To enhance this capability, we propose synthesizing general multimodal instructions from webpage UIs using text-based large language models (LLMs). Despite lacking direct visual input, text-based LLMs are able to process structured text representations from webpage accessibility trees. These instructions are then paired with UI screenshots to train multimodal models. We introduce MultiUI, a dataset containing 7.3 million samples from 1 million websites, covering diverse multimodal tasks and UI layouts. Models trained on MultiUI not only excel in web UI tasks-achieving up to a 48\% improvement on VisualWebBench and a 19.1\% boost in action accuracy on a web agent dataset Mind2Web-but also generalize surprisingly well to non-web UI tasks and even to non-UI domains, such as document understanding, OCR, and chart interpretation. These results highlight the broad applicability of web UI data for advancing text-rich visual understanding across various scenarios.
VisualWebBench: How Far Have Multimodal LLMs Evolved in Web Page Understanding and Grounding?
Apr 09, 2024Multimodal Large Language models (MLLMs) have shown promise in web-related tasks, but evaluating their performance in the web domain remains a challenge due to the lack of comprehensive benchmarks. Existing benchmarks are either designed for general multimodal tasks, failing to capture the unique characteristics of web pages, or focus on end-to-end web agent tasks, unable to measure fine-grained abilities such as OCR, understanding, and grounding. In this paper, we introduce \bench{}, a multimodal benchmark designed to assess the capabilities of MLLMs across a variety of web tasks. \bench{} consists of seven tasks, and comprises 1.5K human-curated instances from 139 real websites, covering 87 sub-domains. We evaluate 14 open-source MLLMs, Gemini Pro, Claude-3 series, and GPT-4V(ision) on \bench{}, revealing significant challenges and performance gaps. Further analysis highlights the limitations of current MLLMs, including inadequate grounding in text-rich environments and subpar performance with low-resolution image inputs. We believe \bench{} will serve as a valuable resource for the research community and contribute to the creation of more powerful and versatile MLLMs for web-related applications.
Topic-Aware Contrastive Learning for Abstractive Dialogue Summarization
Sep 10, 2021
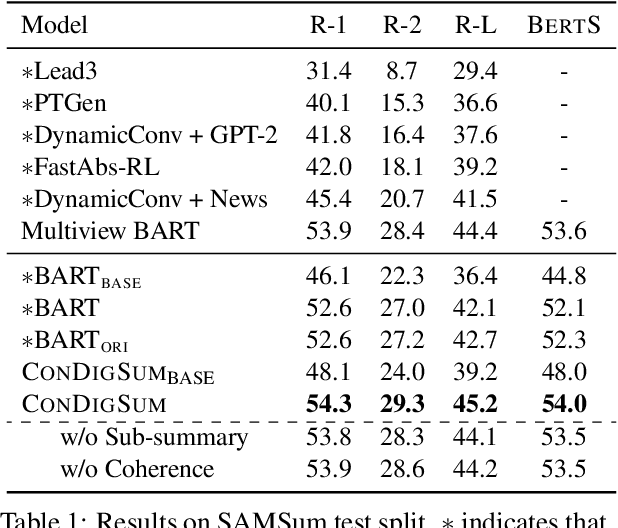
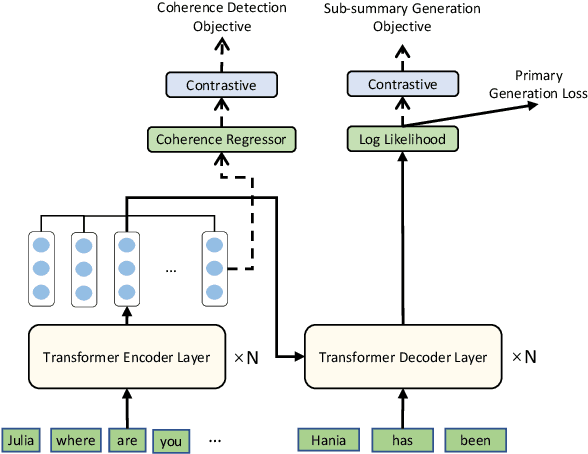
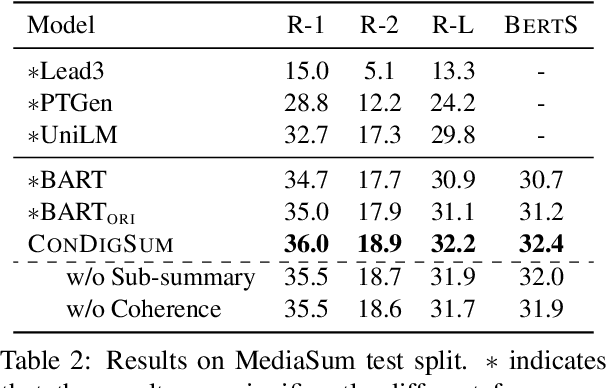
Unlike well-structured text, such as news reports and encyclopedia articles, dialogue content often comes from two or more interlocutors, exchanging information with each other. In such a scenario, the topic of a conversation can vary upon progression and the key information for a certain topic is often scattered across multiple utterances of different speakers, which poses challenges to abstractly summarize dialogues. To capture the various topic information of a conversation and outline salient facts for the captured topics, this work proposes two topic-aware contrastive learning objectives, namely coherence detection and sub-summary generation objectives, which are expected to implicitly model the topic change and handle information scattering challenges for the dialogue summarization task. The proposed contrastive objectives are framed as auxiliary tasks for the primary dialogue summarization task, united via an alternative parameter updating strategy. Extensive experiments on benchmark datasets demonstrate that the proposed simple method significantly outperforms strong baselines and achieves new state-of-the-art performance. The code and trained models are publicly available via \href{https://github.com/Junpliu/ConDigSum}{https://github.com/Junpliu/ConDigSum}.