 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Loss Balancing for Noise-Robust GRPO in Generative Recommendation
Jun 07, 2026Reinforcement learning (RL) presents a promising avenue for enhancing generative recommendation beyond supervised imitation, leveraging reward signals to guide policy improvement. However, its efficacy is critically contingent on the trustworthiness of the reward model for the samples it evaluates. In practice, production rankers, the widely adopted reward models, are trained on exposure-biased logs, leading to sample-dependent inaccuracies that violate this assumption. Our stratified analysis uncovers a consistent pattern: reward guidance is most beneficial when the policy exhibits uncertainty and the ranker can effectively discriminate the ground-truth item from rollout negatives. On other samples, the reward signal is either negligible or detrimental, highlighting the risk of uniform RL application. To address such an issue, we introduce AdaGRPO, a novel framework that treats reward-guided optimization as selective admission rather than uniform pressure. Training is anchored in supervised negative log-likelihood, while the GRPO objective is gated by a binary, per-sample clip determined by two rollout diagnostics: policy-side difficulty and reward discriminability. Instances failing either diagnostic default to pure supervision, ensuring stability and mitigating the amplification of noisy gradients. We validate AdaGRPO on a large-scale e-commerce dataset. At the best intermediate checkpoint, it elevates HR@10 from 11.01% to 12.18% while constraining hallucination below 0.22%, and maintains robustness at the final checkpoint (HR@10 11.63%, hallucination 0.27%), outperforming fixed NLL--GRPO mixtures across the retrieval--validity frontier. In production A/B tests, AdaGRPO achieves statistically significant gains in click-through rate and dwell time, confirming its practical utility.
GenRec: A Preference-Oriented Generative Framework for Large-Scale Recommendation
Apr 16, 2026Generative Retrieval (GR) offers a promising paradigm for recommendation through next-token prediction (NTP). However, scaling it to large-scale industrial systems introduces three challenges: (i) within a single request, the identical model inputs may produce inconsistent outputs due to the pagination request mechanism; (ii) the prohibitive cost of encoding long user behavior sequences with multi-token item representations based on semantic IDs, and (iii) aligning the generative policy with nuanced user preference signals. We present GenRec, a preference-oriented generative framework deployed on the JD App that addresses above challenges within a single decoder-only architecture. For training objective, we propose Page-wise NTP task, which supervises over an entire interaction page rather than each interacted item individually, providing denser gradient signal and resolving the one-to-many ambiguity of point-wise training. On the prefilling side, an asymmetric linear Token Merger compresses multi-token Semantic IDs in the prompt while preserving full-resolution decoding, reducing input length by ~2X with negligible accuracy loss. To further align outputs with user satisfaction, we introduce GRPO-SR, a reinforcement learning method that pairs Group Relative Policy Optimization with NLL regularization for training stability, and employs Hybrid Rewards combining a dense reward model with a relevance gate to mitigate reward hacking. In month-long online A/B tests serving production traffic, GenRec achieves 9.5% improvement in click count and 8.7% in transaction count over the existing pipeline.
Automatic Scene-based Topic Channel Construction System for E-Commerce
Oct 06, 2022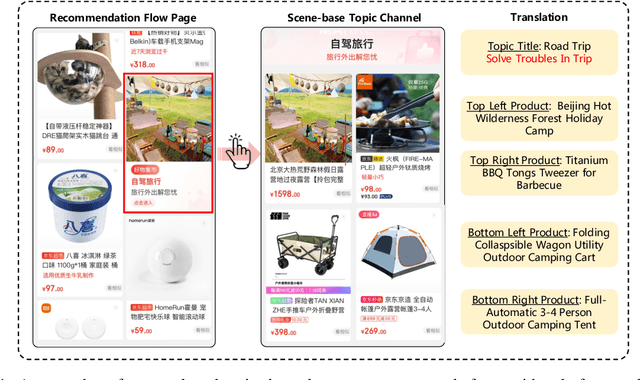

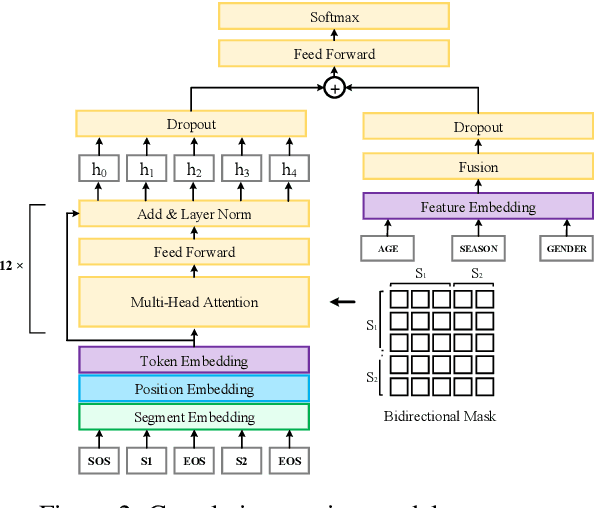
Scene marketing that well demonstrates user interests within a certain scenario has proved effective for offline shopping. To conduct scene marketing for e-commerce platforms, this work presents a novel product form, scene-based topic channel which typically consists of a list of diverse products belonging to the same usage scenario and a topic title that describes the scenario with marketing words. As manual construction of channels is time-consuming due to billions of products as well as dynamic and diverse customers' interests, it is necessary to leverage AI techniques to automatically construct channels for certain usage scenarios and even discover novel topics. To be specific, we first frame the channel construction task as a two-step problem, i.e., scene-based topic generation and product clustering, and propose an E-commerce Scene-based Topic Channel construction system (i.e., ESTC) to achieve automated production, consisting of scene-based topic generation model for the e-commerce domain, product clustering on the basis of topic similarity, as well as quality control based on automatic model filtering and human screening. Extensive offline experiments and online A/B test validates the effectiveness of such a novel product form as well as the proposed system. In addition, we also introduce the experience of deploying the proposed system on a real-world e-commerce recommendation platform.
Automatic Product Copywriting for E-Commerce
Dec 15, 2021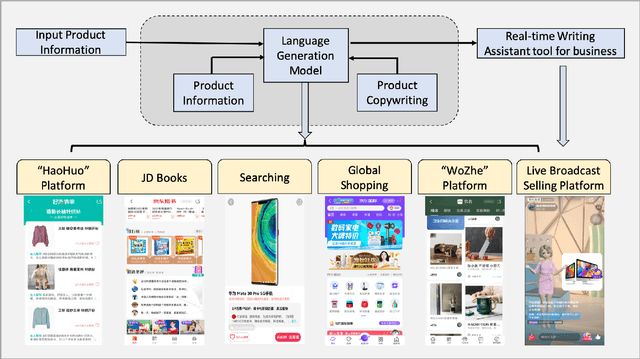

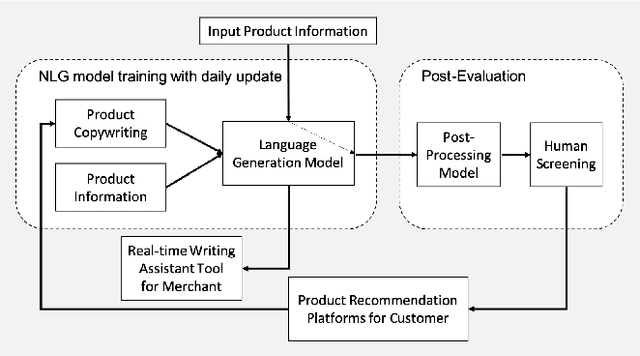
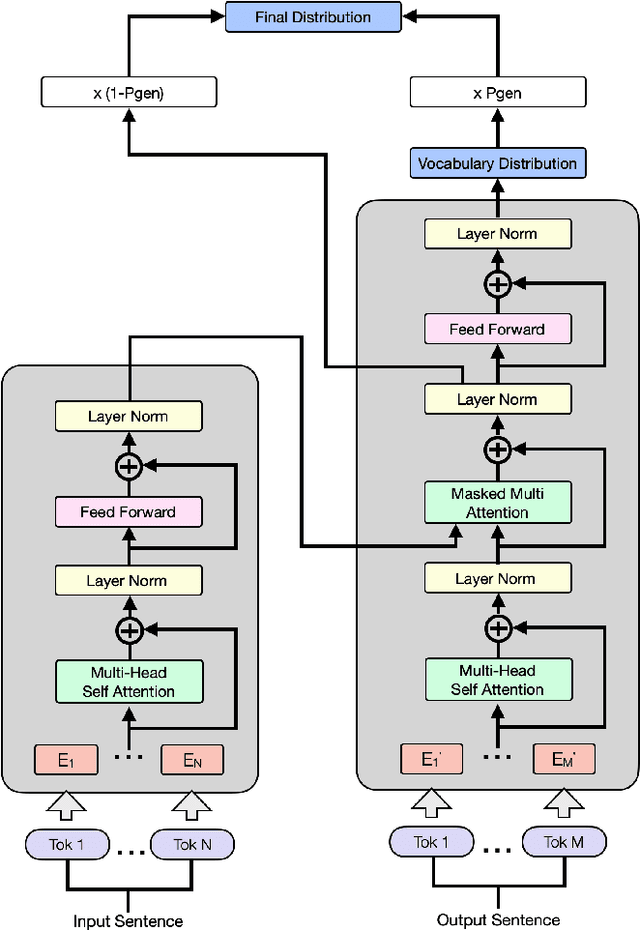
Product copywriting is a critical component of e-commerce recommendation platforms. It aims to attract users' interest and improve user experience by highlighting product characteristics with textual descriptions. In this paper, we report our experience deploying the proposed Automatic Product Copywriting Generation (APCG) system into the JD.com e-commerce product recommendation platform. It consists of two main components: 1) natural language generation, which is built from a transformer-pointer network and a pre-trained sequence-to-sequence model based on millions of training data from our in-house platform; and 2) copywriting quality control, which is based on both automatic evaluation and human screening. For selected domains, the models are trained and updated daily with the updated training data. In addition, the model is also used as a real-time writing assistant tool on our live broadcast platform. The APCG system has been deployed in JD.com since Feb 2021. By Sep 2021, it has generated 2.53 million product descriptions, and improved the overall averaged click-through rate (CTR) and the Conversion Rate (CVR) by 4.22% and 3.61%, compared to baselines, respectively on a year-on-year basis. The accumulated Gross Merchandise Volume (GMV) made by our system is improved by 213.42%, compared to the number in Feb 2021.
Adaptive Bridge between Training and Inference for Dialogue
Oct 22, 2021
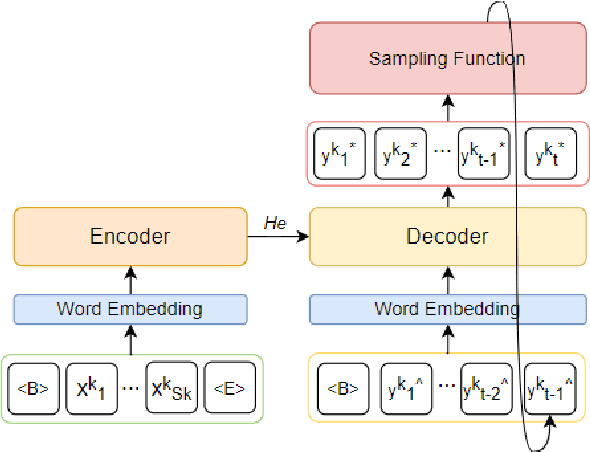
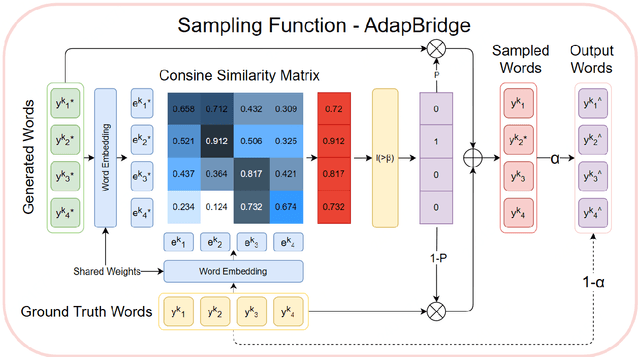
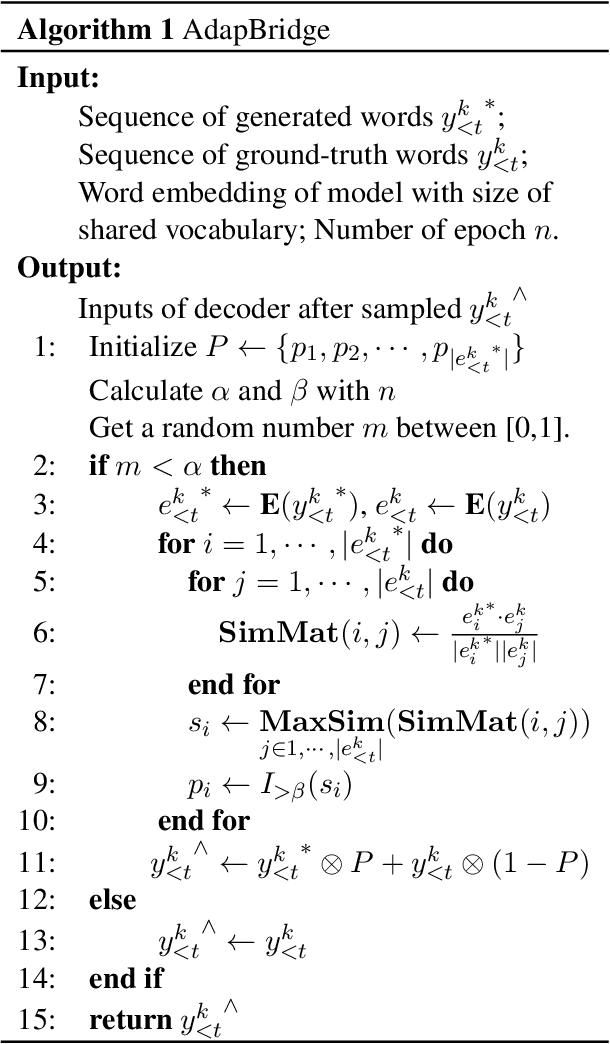
Although exposure bias has been widely studied in some NLP tasks, it faces its unique challenges in dialogue response generation, the representative one-to-various generation scenario. In real human dialogue, there are many appropriate responses for the same context, not only with different expressions, but also with different topics. Therefore, due to the much bigger gap between various ground-truth responses and the generated synthetic response, exposure bias is more challenging in dialogue generation task. What's more, as MLE encourages the model to only learn the common words among different ground-truth responses, but ignores the interesting and specific parts, exposure bias may further lead to the common response generation problem, such as "I don't know" and "HaHa?" In this paper, we propose a novel adaptive switching mechanism, which learns to automatically transit between ground-truth learning and generated learning regarding the word-level matching score, such as the cosine similarity. Experimental results on both Chinese STC dataset and English Reddit dataset, show that our adaptive method achieves a significant improvement in terms of metric-based evaluation and human evaluation, as compared with the state-of-the-art exposure bias approaches. Further analysis on NMT task also shows that our model can achieve a significant improvement.
FCM: A Fine-grained Comparison Model for Multi-turn Dialogue Reasoning
Sep 23, 2021
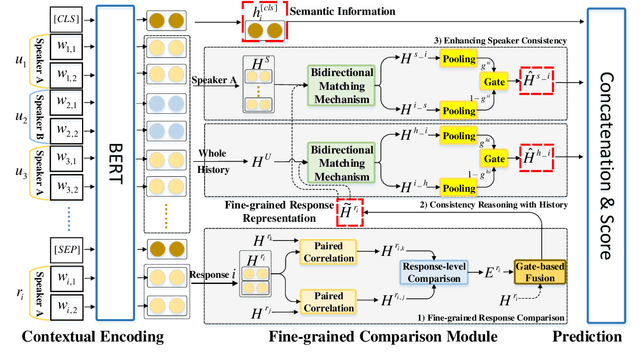
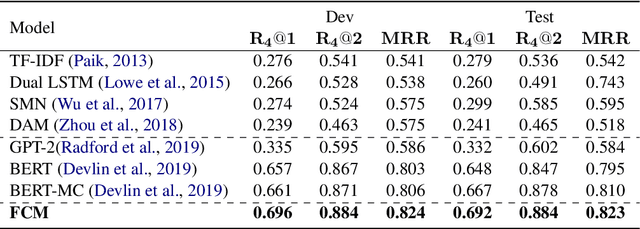

Despite the success of neural dialogue systems in achieving high performance on the leader-board, they cannot meet users' requirements in practice, due to their poor reasoning skills. The underlying reason is that most neural dialogue models only capture the syntactic and semantic information, but fail to model the logical consistency between the dialogue history and the generated response. Recently, a new multi-turn dialogue reasoning task has been proposed, to facilitate dialogue reasoning research. However, this task is challenging, because there are only slight differences between the illogical response and the dialogue history. How to effectively solve this challenge is still worth exploring. This paper proposes a Fine-grained Comparison Model (FCM) to tackle this problem. Inspired by human's behavior in reading comprehension, a comparison mechanism is proposed to focus on the fine-grained differences in the representation of each response candidate. Specifically, each candidate representation is compared with the whole history to obtain a history consistency representation. Furthermore, the consistency signals between each candidate and the speaker's own history are considered to drive a model to prefer a candidate that is logically consistent with the speaker's history logic. Finally, the above consistency representations are employed to output a ranking list of the candidate responses for multi-turn dialogue reasoning. Experimental results on two public dialogue datasets show that our method obtains higher ranking scores than the baseline models.
Topic-Aware Contrastive Learning for Abstractive Dialogue Summarization
Sep 10, 2021
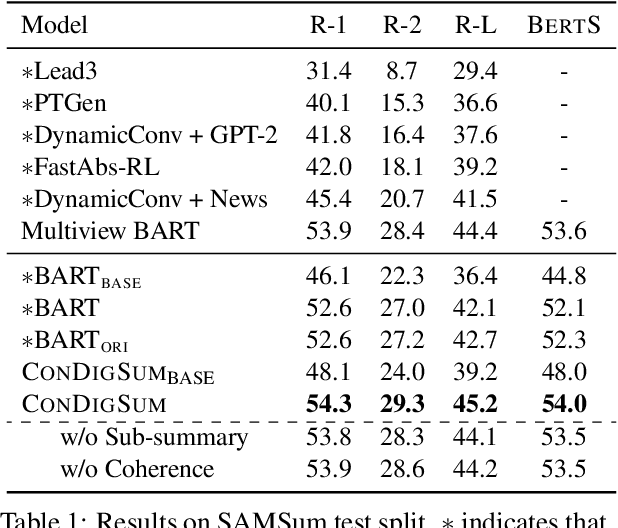
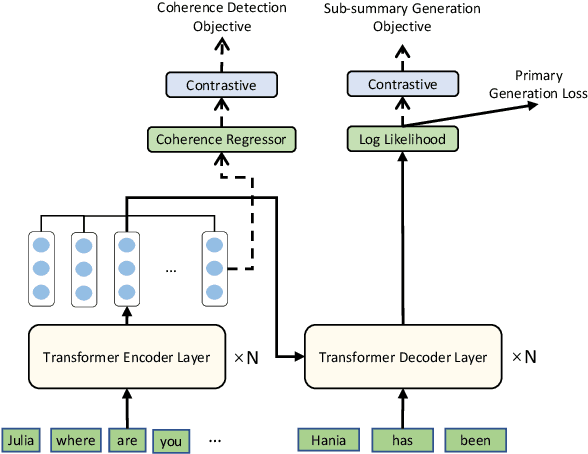
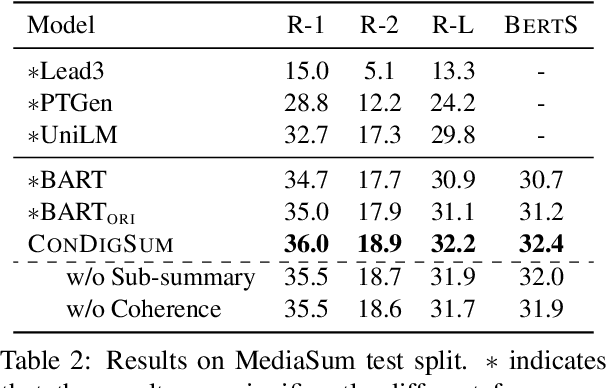
Unlike well-structured text, such as news reports and encyclopedia articles, dialogue content often comes from two or more interlocutors, exchanging information with each other. In such a scenario, the topic of a conversation can vary upon progression and the key information for a certain topic is often scattered across multiple utterances of different speakers, which poses challenges to abstractly summarize dialogues. To capture the various topic information of a conversation and outline salient facts for the captured topics, this work proposes two topic-aware contrastive learning objectives, namely coherence detection and sub-summary generation objectives, which are expected to implicitly model the topic change and handle information scattering challenges for the dialogue summarization task. The proposed contrastive objectives are framed as auxiliary tasks for the primary dialogue summarization task, united via an alternative parameter updating strategy. Extensive experiments on benchmark datasets demonstrate that the proposed simple method significantly outperforms strong baselines and achieves new state-of-the-art performance. The code and trained models are publicly available via \href{https://github.com/Junpliu/ConDigSum}{https://github.com/Junpliu/ConDigSum}.
STEP: Sequence-to-Sequence Transformer Pre-training for Document Summarization
Apr 04, 2020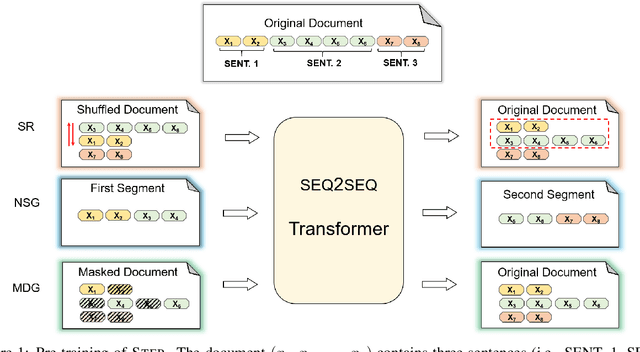
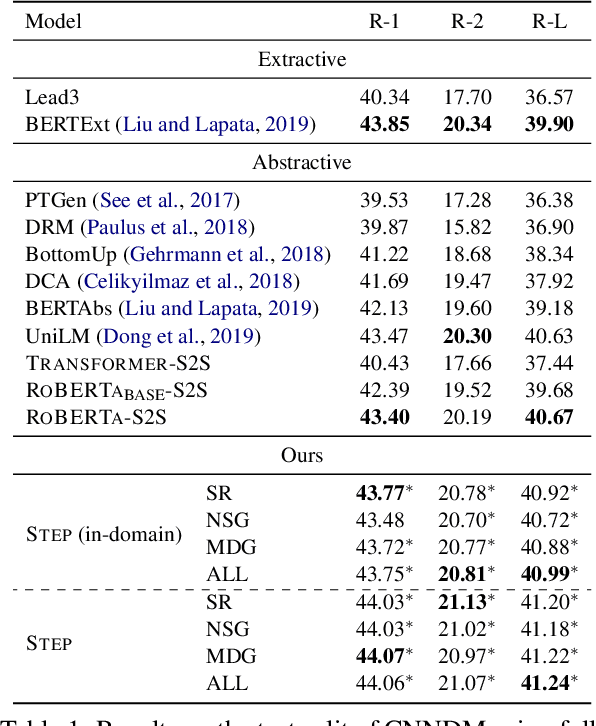
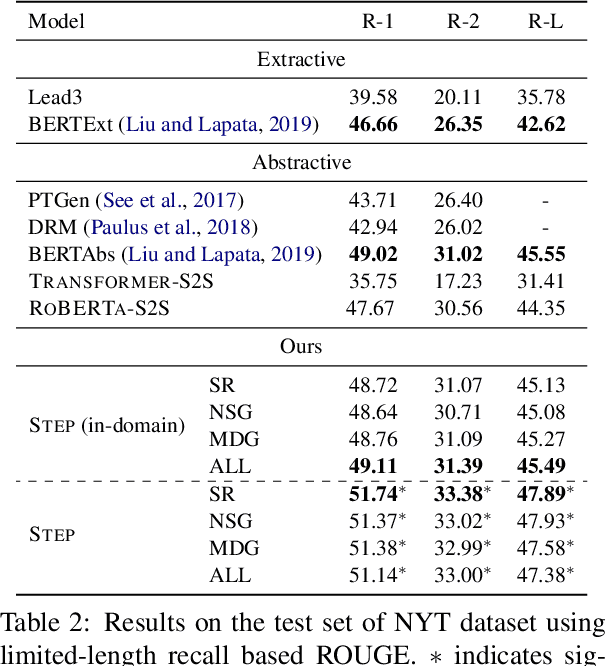
Abstractive summarization aims to rewrite a long document to its shorter form, which is usually modeled as a sequence-to-sequence (Seq2Seq) learning problem. Seq2Seq Transformers are powerful models for this problem. Unfortunately, training large Seq2Seq Transformers on limited supervised summarization data is challenging. We, therefore, propose STEP (as shorthand for Sequence-to-Sequence Transformer Pre-training), which can be trained on large scale unlabeled documents. Specifically, STEP is pre-trained using three different tasks, namely sentence reordering, next sentence generation, and masked document generation. Experiments on two summarization datasets show that all three tasks can improve performance upon a heavily tuned large Seq2Seq Transformer which already includes a strong pre-trained encoder by a large margin. By using our best task to pre-train STEP, we outperform the best published abstractive model on CNN/DailyMail by 0.8 ROUGE-2 and New York Times by 2.4 ROUGE-2.
Mining Commonsense Facts from the Physical World
Feb 11, 2020


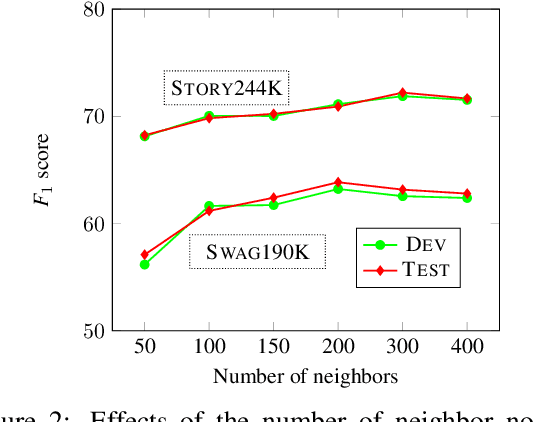
Textual descriptions of the physical world implicitly mention commonsense facts, while the commonsense knowledge bases explicitly represent such facts as triples. Compared to dramatically increased text data, the coverage of existing knowledge bases is far away from completion. Most of the prior studies on populating knowledge bases mainly focus on Freebase. To automatically complete commonsense knowledge bases to improve their coverage is under-explored. In this paper, we propose a new task of mining commonsense facts from the raw text that describes the physical world. We build an effective new model that fuses information from both sequence text and existing knowledge base resource. Then we create two large annotated datasets each with approximate 200k instances for commonsense knowledge base completion. Empirical results demonstrate that our model significantly outperforms baselines.
Aligning Cross-Lingual Entities with Multi-Aspect Information
Oct 15, 2019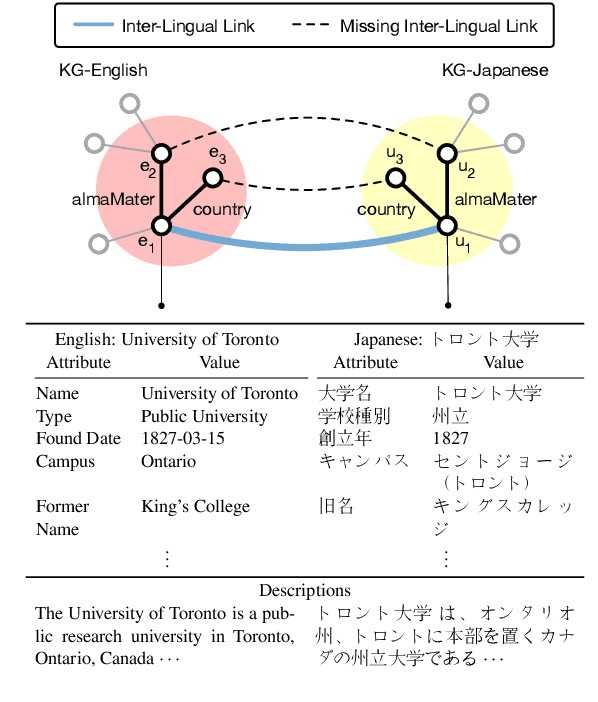

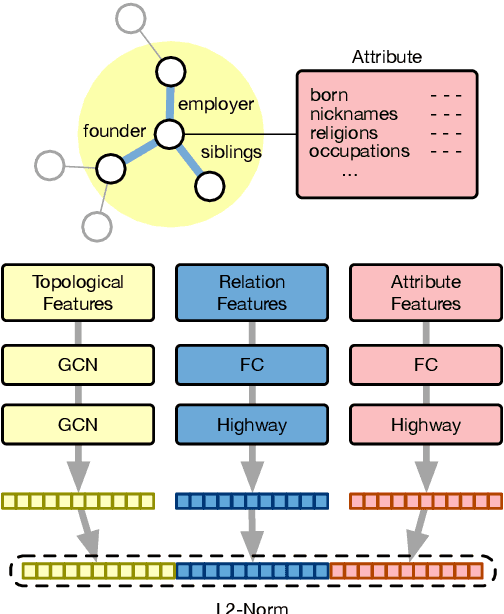

Multilingual knowledge graphs (KGs), such as YAGO and DBpedia, represent entities in different languages. The task of cross-lingual entity alignment is to match entities in a source language with their counterparts in target languages. In this work, we investigate embedding-based approaches to encode entities from multilingual KGs into the same vector space, where equivalent entities are close to each other. Specifically, we apply graph convolutional networks (GCNs) to combine multi-aspect information of entities, including topological connections, relations, and attributes of entities, to learn entity embeddings. To exploit the literal descriptions of entities expressed in different languages, we propose two uses of a pretrained multilingual BERT model to bridge cross-lingual gaps. We further propose two strategies to integrate GCN-based and BERT-based modules to boost performance. Extensive experiments on two benchmark datasets demonstrate that our method significantly outperforms existing systems.