 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Scene-based Topic Channel Construction System for E-Commerce
Oct 06, 2022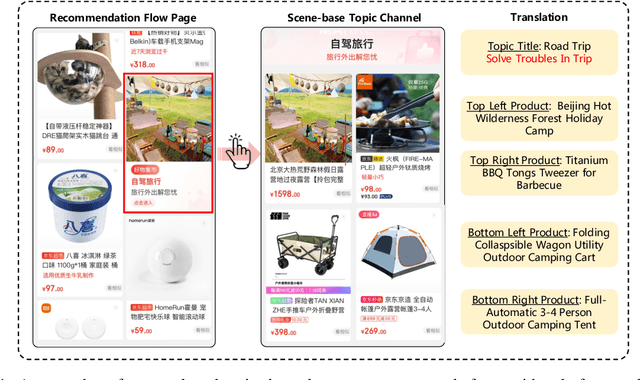

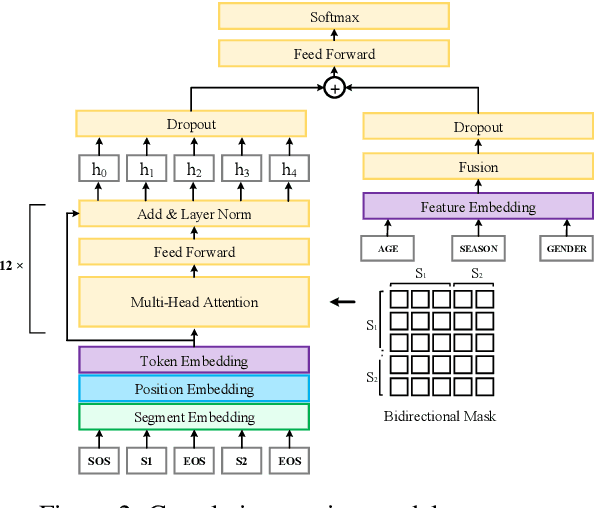
Scene marketing that well demonstrates user interests within a certain scenario has proved effective for offline shopping. To conduct scene marketing for e-commerce platforms, this work presents a novel product form, scene-based topic channel which typically consists of a list of diverse products belonging to the same usage scenario and a topic title that describes the scenario with marketing words. As manual construction of channels is time-consuming due to billions of products as well as dynamic and diverse customers' interests, it is necessary to leverage AI techniques to automatically construct channels for certain usage scenarios and even discover novel topics. To be specific, we first frame the channel construction task as a two-step problem, i.e., scene-based topic generation and product clustering, and propose an E-commerce Scene-based Topic Channel construction system (i.e., ESTC) to achieve automated production, consisting of scene-based topic generation model for the e-commerce domain, product clustering on the basis of topic similarity, as well as quality control based on automatic model filtering and human screening. Extensive offline experiments and online A/B test validates the effectiveness of such a novel product form as well as the proposed system. In addition, we also introduce the experience of deploying the proposed system on a real-world e-commerce recommendation platform.
Intelligent Online Selling Point Extraction for E-Commerce Recommendation
Dec 16, 2021


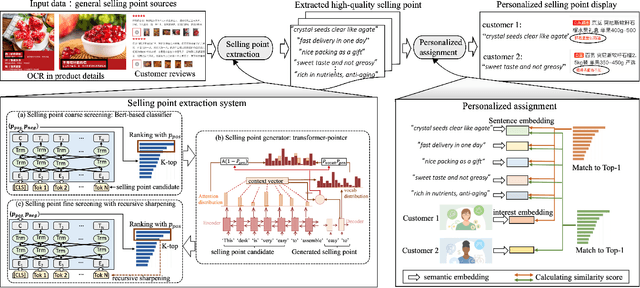
In the past decade, automatic product description generation for e-commerce have witnessed significant advancement. As the services provided by e-commerce platforms become diverse, it is necessary to dynamically adapt the patterns of descriptions generated. The selling point of products is an important type of product description for which the length should be as short as possible while still conveying key information. In addition, this kind of product description should be eye-catching to the readers. Currently, product selling points are normally written by human experts. Thus, the creation and maintenance of these contents incur high costs. These costs can be significantly reduced if product selling points can be automatically generated by machines. In this paper, we report our experience developing and deploying the Intelligent Online Selling Point Extraction (IOSPE) system to serve the recommendation system in the JD.com e-commerce platform. Since July 2020, IOSPE has become a core service for 62 key categories of products (covering more than 4 million products). So far, it has generated more than 0.1 billion selling points, thereby significantly scaling up the selling point creation operation and saving human labour. These IOSPE generated selling points have increased the click-through rate (CTR) by 1.89\% and the average duration the customers spent on the products by more than 2.03\% compared to the previous practice, which are significant improvements for such a large-scale e-commerce platform.
Automatic Product Copywriting for E-Commerce
Dec 15, 2021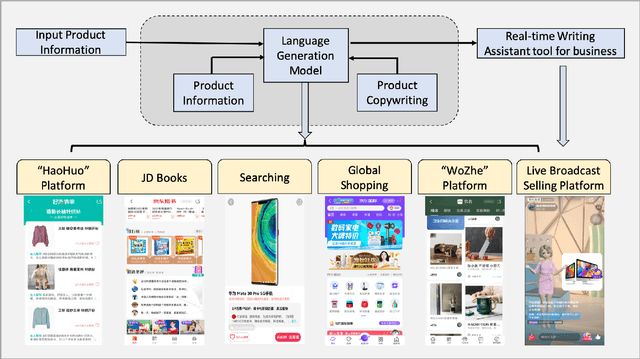

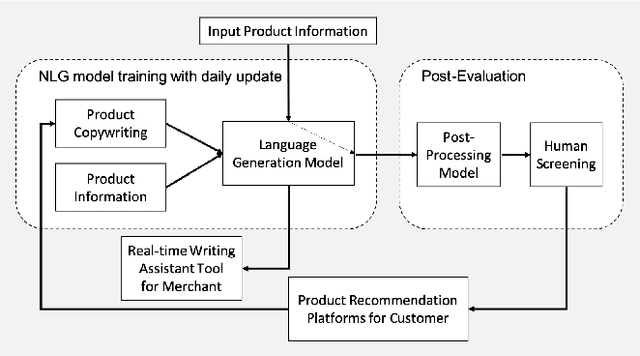
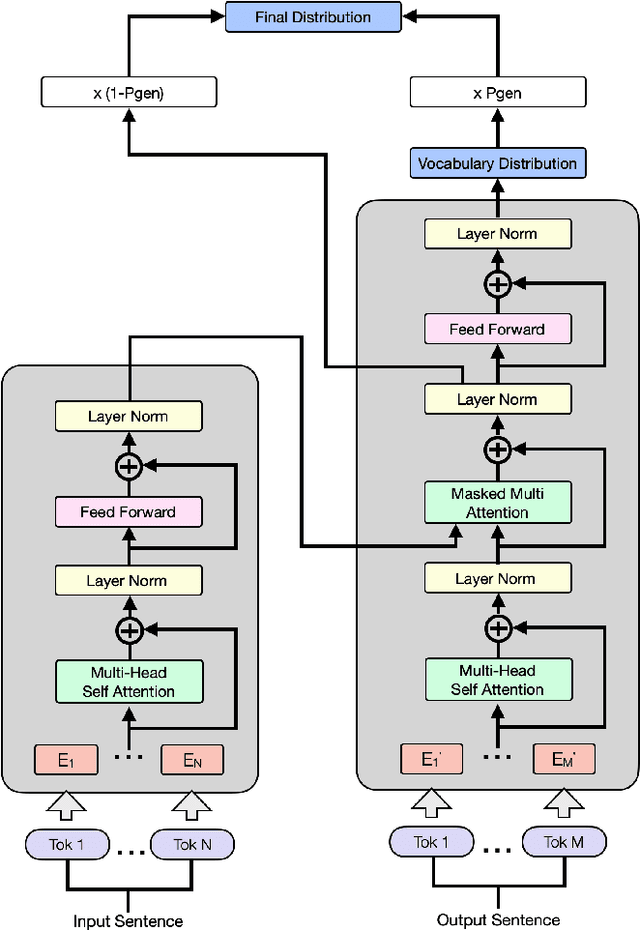
Product copywriting is a critical component of e-commerce recommendation platforms. It aims to attract users' interest and improve user experience by highlighting product characteristics with textual descriptions. In this paper, we report our experience deploying the proposed Automatic Product Copywriting Generation (APCG) system into the JD.com e-commerce product recommendation platform. It consists of two main components: 1) natural language generation, which is built from a transformer-pointer network and a pre-trained sequence-to-sequence model based on millions of training data from our in-house platform; and 2) copywriting quality control, which is based on both automatic evaluation and human screening. For selected domains, the models are trained and updated daily with the updated training data. In addition, the model is also used as a real-time writing assistant tool on our live broadcast platform. The APCG system has been deployed in JD.com since Feb 2021. By Sep 2021, it has generated 2.53 million product descriptions, and improved the overall averaged click-through rate (CTR) and the Conversion Rate (CVR) by 4.22% and 3.61%, compared to baselines, respectively on a year-on-year basis. The accumulated Gross Merchandise Volume (GMV) made by our system is improved by 213.42%, compared to the number in Feb 2021.
Adaptive Bridge between Training and Inference for Dialogue
Oct 22, 2021
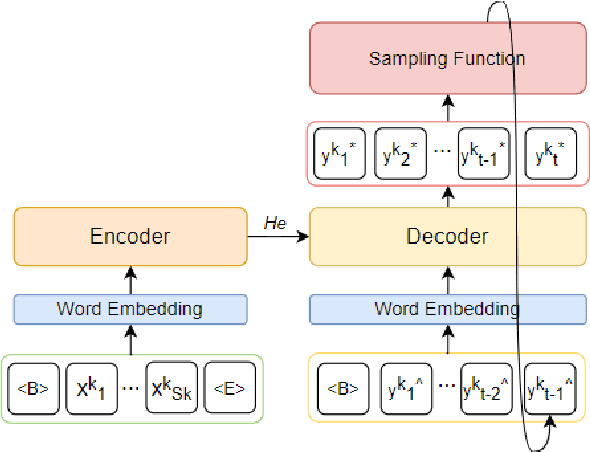
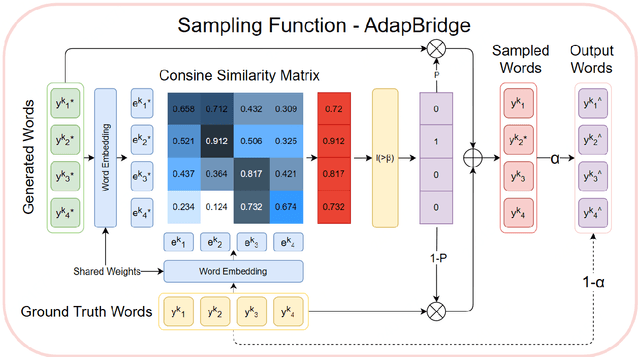
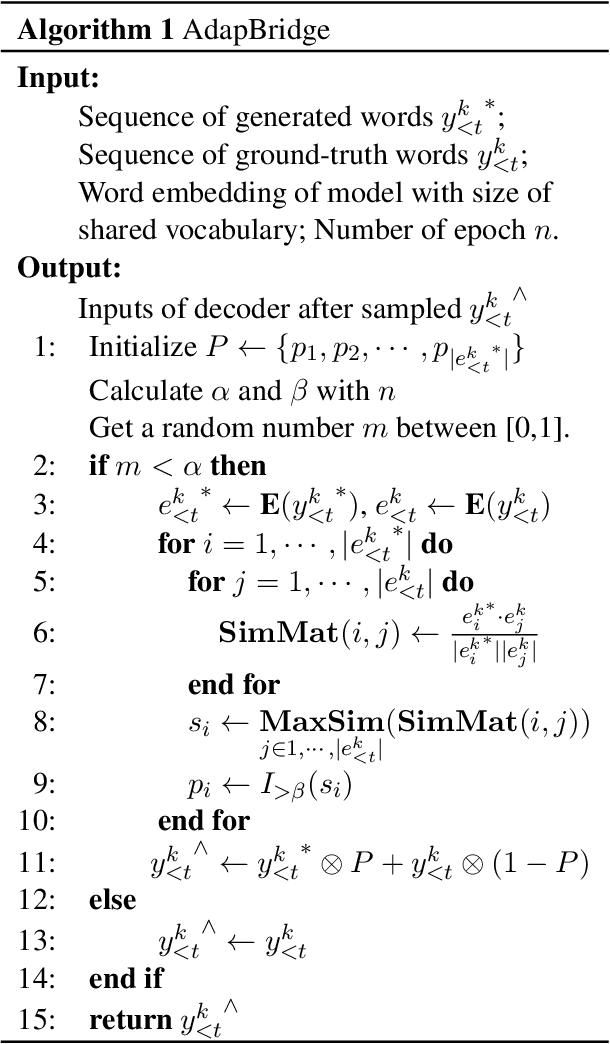
Although exposure bias has been widely studied in some NLP tasks, it faces its unique challenges in dialogue response generation, the representative one-to-various generation scenario. In real human dialogue, there are many appropriate responses for the same context, not only with different expressions, but also with different topics. Therefore, due to the much bigger gap between various ground-truth responses and the generated synthetic response, exposure bias is more challenging in dialogue generation task. What's more, as MLE encourages the model to only learn the common words among different ground-truth responses, but ignores the interesting and specific parts, exposure bias may further lead to the common response generation problem, such as "I don't know" and "HaHa?" In this paper, we propose a novel adaptive switching mechanism, which learns to automatically transit between ground-truth learning and generated learning regarding the word-level matching score, such as the cosine similarity. Experimental results on both Chinese STC dataset and English Reddit dataset, show that our adaptive method achieves a significant improvement in terms of metric-based evaluation and human evaluation, as compared with the state-of-the-art exposure bias approaches. Further analysis on NMT task also shows that our model can achieve a significant improvement.
FCM: A Fine-grained Comparison Model for Multi-turn Dialogue Reasoning
Sep 23, 2021
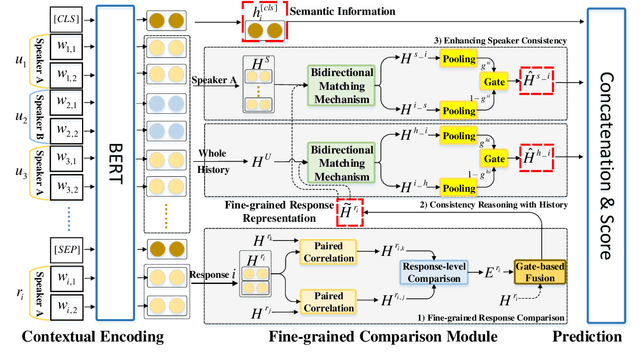
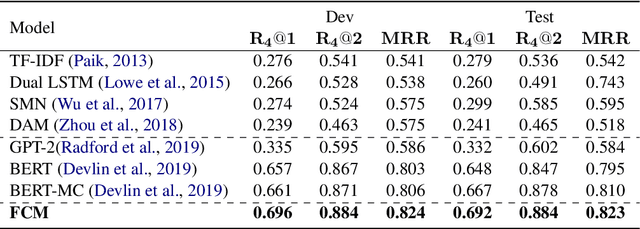

Despite the success of neural dialogue systems in achieving high performance on the leader-board, they cannot meet users' requirements in practice, due to their poor reasoning skills. The underlying reason is that most neural dialogue models only capture the syntactic and semantic information, but fail to model the logical consistency between the dialogue history and the generated response. Recently, a new multi-turn dialogue reasoning task has been proposed, to facilitate dialogue reasoning research. However, this task is challenging, because there are only slight differences between the illogical response and the dialogue history. How to effectively solve this challenge is still worth exploring. This paper proposes a Fine-grained Comparison Model (FCM) to tackle this problem. Inspired by human's behavior in reading comprehension, a comparison mechanism is proposed to focus on the fine-grained differences in the representation of each response candidate. Specifically, each candidate representation is compared with the whole history to obtain a history consistency representation. Furthermore, the consistency signals between each candidate and the speaker's own history are considered to drive a model to prefer a candidate that is logically consistent with the speaker's history logic. Finally, the above consistency representations are employed to output a ranking list of the candidate responses for multi-turn dialogue reasoning. Experimental results on two public dialogue datasets show that our method obtains higher ranking scores than the baseline models.
Topic-Aware Contrastive Learning for Abstractive Dialogue Summarization
Sep 10, 2021
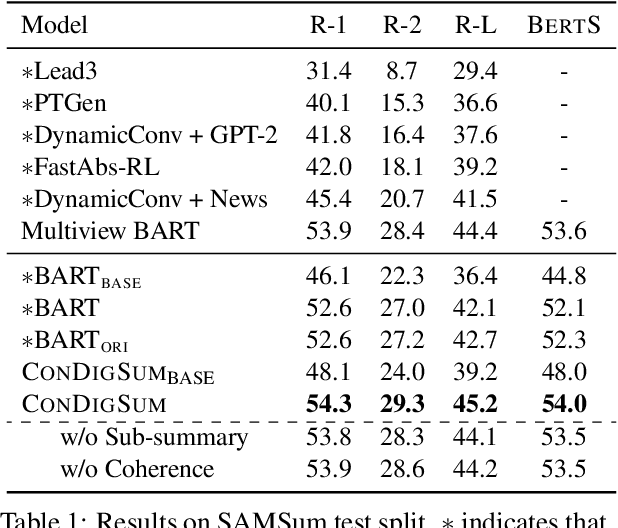
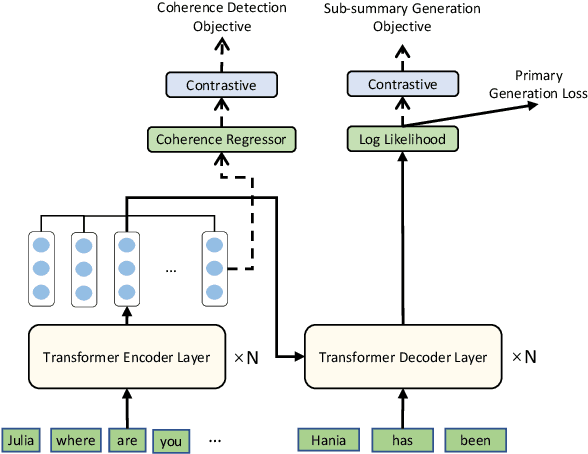
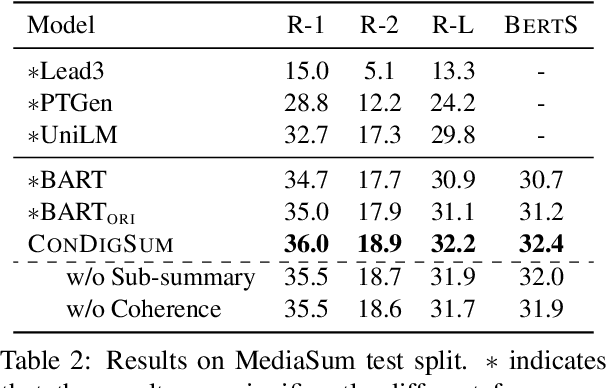
Unlike well-structured text, such as news reports and encyclopedia articles, dialogue content often comes from two or more interlocutors, exchanging information with each other. In such a scenario, the topic of a conversation can vary upon progression and the key information for a certain topic is often scattered across multiple utterances of different speakers, which poses challenges to abstractly summarize dialogues. To capture the various topic information of a conversation and outline salient facts for the captured topics, this work proposes two topic-aware contrastive learning objectives, namely coherence detection and sub-summary generation objectives, which are expected to implicitly model the topic change and handle information scattering challenges for the dialogue summarization task. The proposed contrastive objectives are framed as auxiliary tasks for the primary dialogue summarization task, united via an alternative parameter updating strategy. Extensive experiments on benchmark datasets demonstrate that the proposed simple method significantly outperforms strong baselines and achieves new state-of-the-art performance. The code and trained models are publicly available via \href{https://github.com/Junpliu/ConDigSum}{https://github.com/Junpliu/ConDigSum}.
Improving Sequential Recommendation Consistency with Self-Supervised Imitation
Jun 29, 2021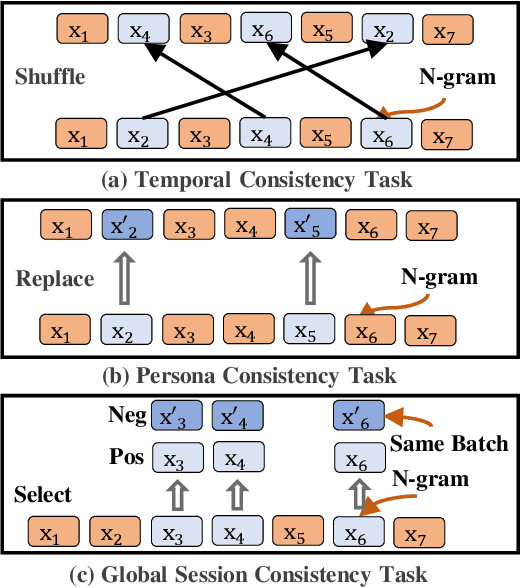
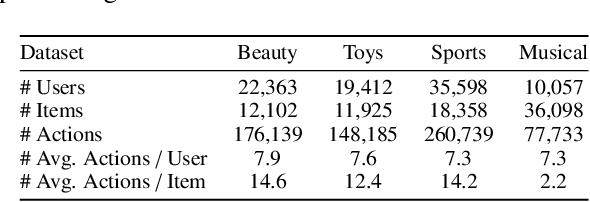
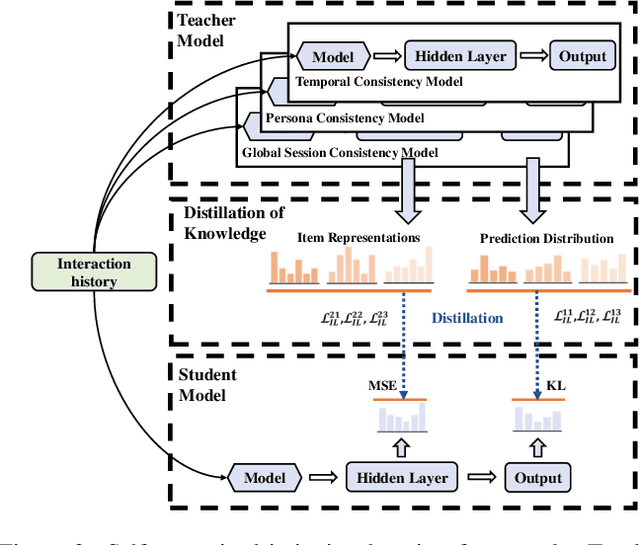
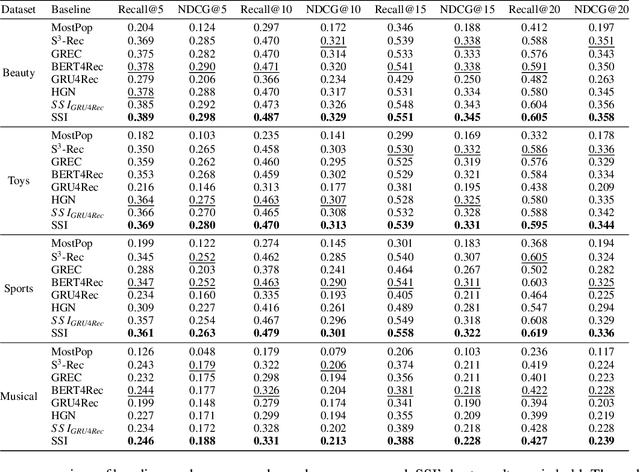
Most sequential recommendation models capture the features of consecutive items in a user-item interaction history. Though effective, their representation expressiveness is still hindered by the sparse learning signals. As a result, the sequential recommender is prone to make inconsistent predictions. In this paper, we propose a model, SSI, to improve sequential recommendation consistency with Self-Supervised Imitation. Precisely, we extract the consistency knowledge by utilizing three self-supervised pre-training tasks, where temporal consistency and persona consistency capture user-interaction dynamics in terms of the chronological order and persona sensitivities, respectively. Furthermore, to provide the model with a global perspective, global session consistency is introduced by maximizing the mutual information among global and local interaction sequences. Finally, to comprehensively take advantage of all three independent aspects of consistency-enhanced knowledge, we establish an integrated imitation learning framework. The consistency knowledge is effectively internalized and transferred to the student model by imitating the conventional prediction logit as well as the consistency-enhanced item representations. In addition, the flexible self-supervised imitation framework can also benefit other student recommenders. Experiments on four real-world datasets show that SSI effectively outperforms the state-of-the-art sequential recommendation methods.
Probing Product Description Generation via Posterior Distillation
Mar 02, 2021

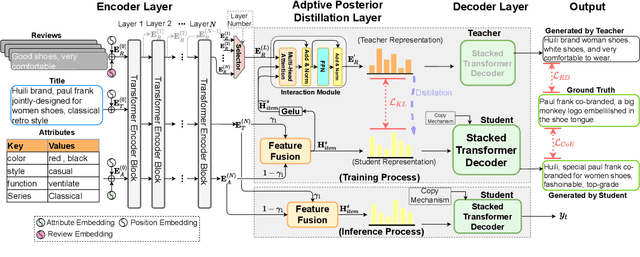

In product description generation (PDG), the user-cared aspect is critical for the recommendation system, which can not only improve user's experiences but also obtain more clicks. High-quality customer reviews can be considered as an ideal source to mine user-cared aspects. However, in reality, a large number of new products (known as long-tailed commodities) cannot gather sufficient amount of customer reviews, which brings a big challenge in the product description generation task. Existing works tend to generate the product description solely based on item information, i.e., product attributes or title words, which leads to tedious contents and cannot attract customers effectively. To tackle this problem, we propose an adaptive posterior network based on Transformer architecture that can utilize user-cared information from customer reviews. Specifically, we first extend the self-attentive Transformer encoder to encode product titles and attributes. Then, we apply an adaptive posterior distillation module to utilize useful review information, which integrates user-cared aspects to the generation process. Finally, we apply a Transformer-based decoding phase with copy mechanism to automatically generate the product description. Besides, we also collect a large-scare Chinese product description dataset to support our work and further research in this field. Experimental results show that our model is superior to traditional generative models in both automatic indicators and human evaluation.
User-Inspired Posterior Network for Recommendation Reason Generation
Feb 16, 2021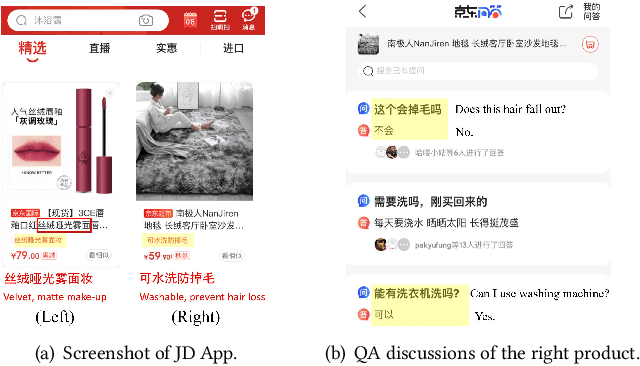
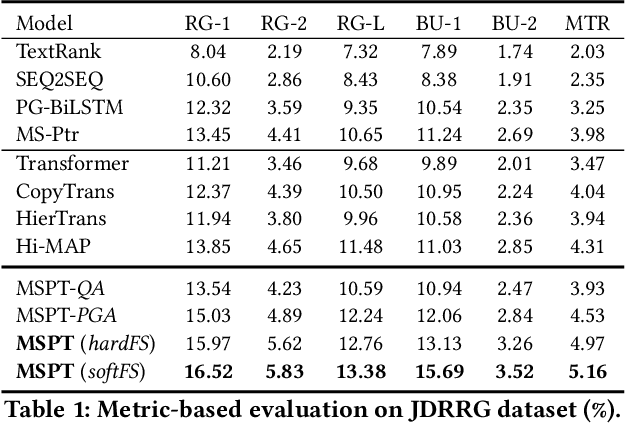
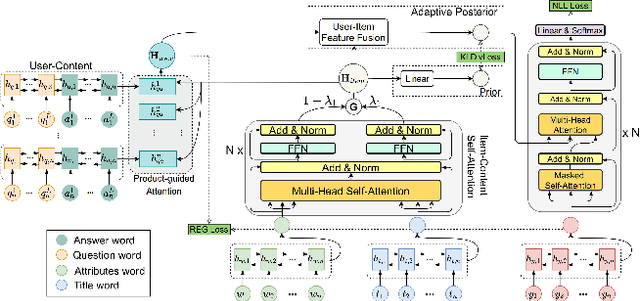
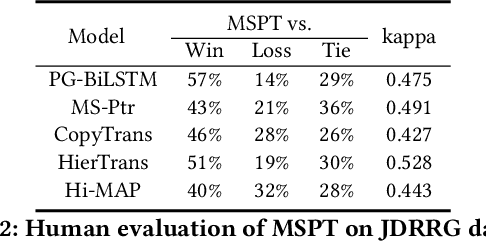
Recommendation reason generation, aiming at showing the selling points of products for customers, plays a vital role in attracting customers' attention as well as improving user experience. A simple and effective way is to extract keywords directly from the knowledge-base of products, i.e., attributes or title, as the recommendation reason. However, generating recommendation reason from product knowledge doesn't naturally respond to users' interests. Fortunately, on some E-commerce websites, there exists more and more user-generated content (user-content for short), i.e., product question-answering (QA) discussions, which reflect user-cared aspects. Therefore, in this paper, we consider generating the recommendation reason by taking into account not only the product attributes but also the customer-generated product QA discussions. In reality, adequate user-content is only possible for the most popular commodities, whereas large sums of long-tail products or new products cannot gather a sufficient number of user-content. To tackle this problem, we propose a user-inspired multi-source posterior transformer (MSPT), which induces the model reflecting the users' interests with a posterior multiple QA discussions module, and generating recommendation reasons containing the product attributes as well as the user-cared aspects. Experimental results show that our model is superior to traditional generative models. Additionally, the analysis also shows that our model can focus more on the user-cared aspects than baselines.
Group-wise Contrastive Learning for Neural Dialogue Generation
Oct 13, 2020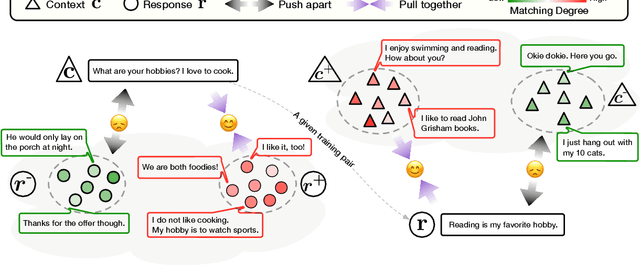
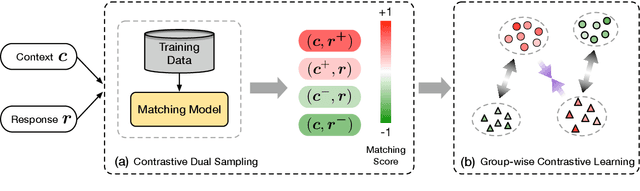
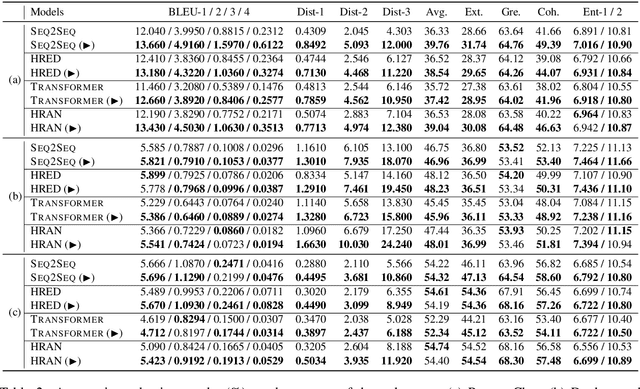
Neural dialogue response generation has gained much popularity in recent years. Maximum Likelihood Estimation (MLE) objective is widely adopted in existing dialogue model learning. However, models trained with MLE objective function are plagued by the low-diversity issue when it comes to the open-domain conversational setting. Inspired by the observation that humans not only learn from the positive signals but also benefit from correcting behaviors of undesirable actions, in this work, we introduce contrastive learning into dialogue generation, where the model explicitly perceives the difference between the well-chosen positive and negative utterances. Specifically, we employ a pretrained baseline model as a reference. During contrastive learning, the target dialogue model is trained to give higher conditional probabilities for the positive samples, and lower conditional probabilities for those negative samples, compared to the reference model. To manage the multi-mapping relations prevailed in human conversation, we augment contrastive dialogue learning with group-wise dual sampling. Extensive experimental results show that the proposed group-wise contrastive learning framework is suited for training a wide range of neural dialogue generation models with very favorable performance over the baseline training approaches.