 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Transformation from Natural Language to Signal Temporal Logic Using LLMs with Diverse External Knowledge
May 27, 2025Temporal Logic (TL), especially Signal Temporal Logic (STL), enables precise formal specification, making it widely used in cyber-physical systems such as autonomous driving and robotics. Automatically transforming NL into STL is an attractive approach to overcome the limitations of manual transformation, which is time-consuming and error-prone. However, due to the lack of datasets, automatic transformation currently faces significant challenges and has not been fully explored. In this paper, we propose an NL-STL dataset named STL-Diversity-Enhanced (STL-DivEn), which comprises 16,000 samples enriched with diverse patterns. To develop the dataset, we first manually create a small-scale seed set of NL-STL pairs. Next, representative examples are identified through clustering and used to guide large language models (LLMs) in generating additional NL-STL pairs. Finally, diversity and accuracy are ensured through rigorous rule-based filters and human validation. Furthermore, we introduce the Knowledge-Guided STL Transformation (KGST) framework, a novel approach for transforming natural language into STL, involving a generate-then-refine process based on external knowledge. Statistical analysis shows that the STL-DivEn dataset exhibits more diversity than the existing NL-STL dataset. Moreover, both metric-based and human evaluations indicate that our KGST approach outperforms baseline models in transformation accuracy on STL-DivEn and DeepSTL datasets.
Answering Ambiguous Questions via Iterative Prompting
Jul 08, 2023

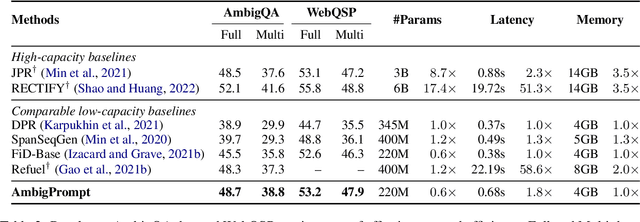
In open-domain question answering, due to the ambiguity of questions, multiple plausible answers may exist. To provide feasible answers to an ambiguous question, one approach is to directly predict all valid answers, but this can struggle with balancing relevance and diversity. An alternative is to gather candidate answers and aggregate them, but this method can be computationally costly and may neglect dependencies among answers. In this paper, we present AmbigPrompt to address the imperfections of existing approaches to answering ambiguous questions. Specifically, we integrate an answering model with a prompting model in an iterative manner. The prompting model adaptively tracks the reading process and progressively triggers the answering model to compose distinct and relevant answers. Additionally, we develop a task-specific post-pretraining approach for both the answering model and the prompting model, which greatly improves the performance of our framework. Empirical studies on two commonly-used open benchmarks show that AmbigPrompt achieves state-of-the-art or competitive results while using less memory and having a lower inference latency than competing approaches. Additionally, AmbigPrompt also performs well in low-resource settings. The code are available at: https://github.com/sunnweiwei/AmbigPrompt.
Embracing Uncertainty: Adaptive Vague Preference Policy Learning for Multi-round Conversational Recommendation
Jun 07, 2023

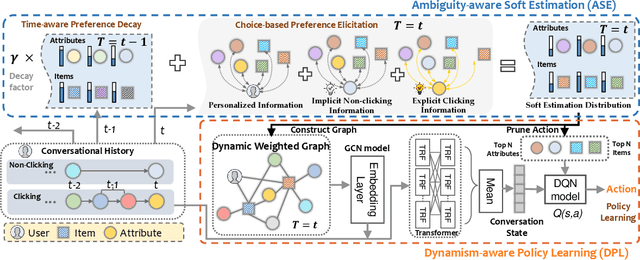
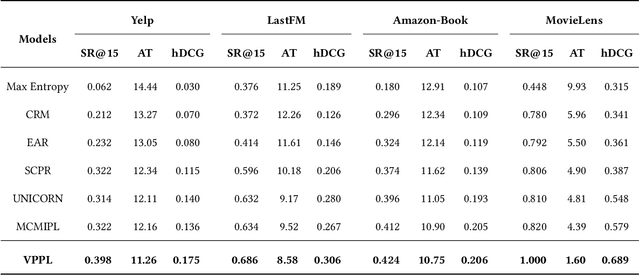
Conversational recommendation systems (CRS) effectively address information asymmetry by dynamically eliciting user preferences through multi-turn interactions. Existing CRS widely assumes that users have clear preferences. Under this assumption, the agent will completely trust the user feedback and treat the accepted or rejected signals as strong indicators to filter items and reduce the candidate space, which may lead to the problem of over-filtering. However, in reality, users' preferences are often vague and volatile, with uncertainty about their desires and changing decisions during interactions. To address this issue, we introduce a novel scenario called Vague Preference Multi-round Conversational Recommendation (VPMCR), which considers users' vague and volatile preferences in CRS.VPMCR employs a soft estimation mechanism to assign a non-zero confidence score for all candidate items to be displayed, naturally avoiding the over-filtering problem. In the VPMCR setting, we introduce an solution called Adaptive Vague Preference Policy Learning (AVPPL), which consists of two main components: Uncertainty-aware Soft Estimation (USE) and Uncertainty-aware Policy Learning (UPL). USE estimates the uncertainty of users' vague feedback and captures their dynamic preferences using a choice-based preferences extraction module and a time-aware decaying strategy. UPL leverages the preference distribution estimated by USE to guide the conversation and adapt to changes in users' preferences to make recommendations or ask for attributes. Our extensive experiments demonstrate the effectiveness of our method in the VPMCR scenario, highlighting its potential for practical applications and improving the overall performance and applicability of CRS in real-world settings, particularly for users with vague or dynamic preferences.
Adaptive Bridge between Training and Inference for Dialogue
Oct 22, 2021
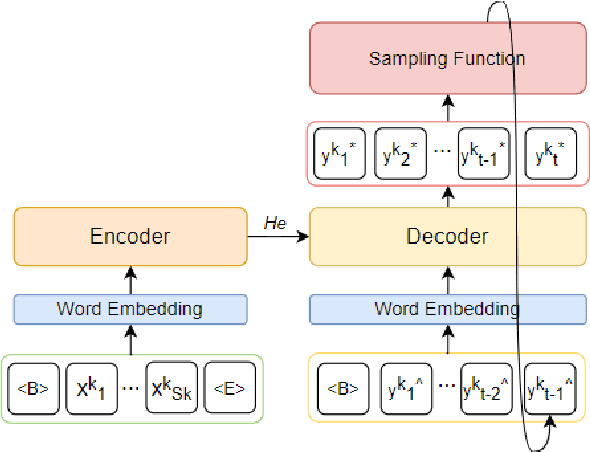
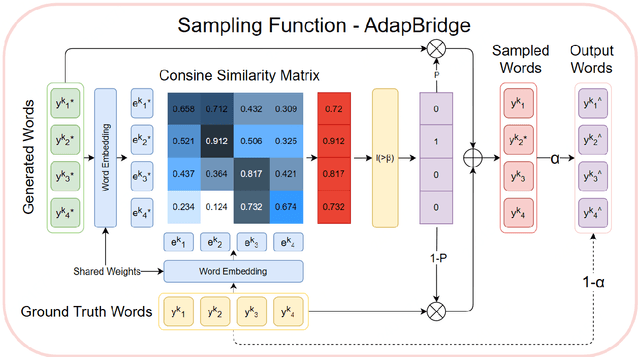
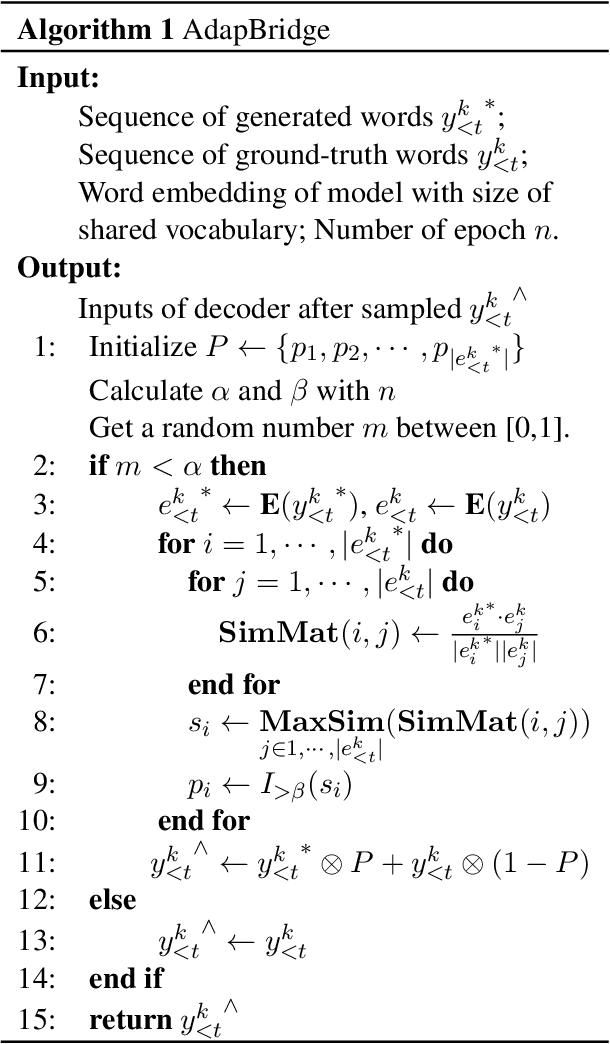
Although exposure bias has been widely studied in some NLP tasks, it faces its unique challenges in dialogue response generation, the representative one-to-various generation scenario. In real human dialogue, there are many appropriate responses for the same context, not only with different expressions, but also with different topics. Therefore, due to the much bigger gap between various ground-truth responses and the generated synthetic response, exposure bias is more challenging in dialogue generation task. What's more, as MLE encourages the model to only learn the common words among different ground-truth responses, but ignores the interesting and specific parts, exposure bias may further lead to the common response generation problem, such as "I don't know" and "HaHa?" In this paper, we propose a novel adaptive switching mechanism, which learns to automatically transit between ground-truth learning and generated learning regarding the word-level matching score, such as the cosine similarity. Experimental results on both Chinese STC dataset and English Reddit dataset, show that our adaptive method achieves a significant improvement in terms of metric-based evaluation and human evaluation, as compared with the state-of-the-art exposure bias approaches. Further analysis on NMT task also shows that our model can achieve a significant improvement.
FCM: A Fine-grained Comparison Model for Multi-turn Dialogue Reasoning
Sep 23, 2021
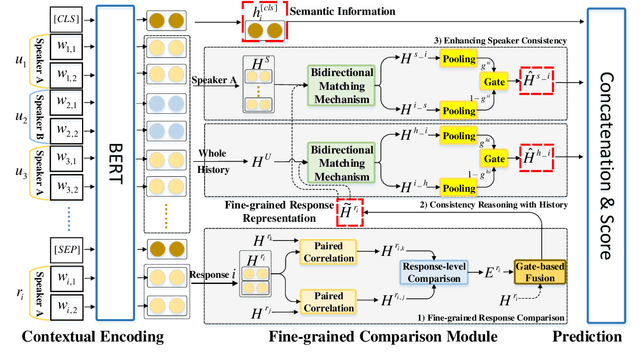
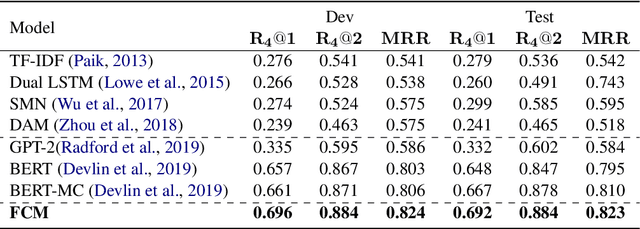

Despite the success of neural dialogue systems in achieving high performance on the leader-board, they cannot meet users' requirements in practice, due to their poor reasoning skills. The underlying reason is that most neural dialogue models only capture the syntactic and semantic information, but fail to model the logical consistency between the dialogue history and the generated response. Recently, a new multi-turn dialogue reasoning task has been proposed, to facilitate dialogue reasoning research. However, this task is challenging, because there are only slight differences between the illogical response and the dialogue history. How to effectively solve this challenge is still worth exploring. This paper proposes a Fine-grained Comparison Model (FCM) to tackle this problem. Inspired by human's behavior in reading comprehension, a comparison mechanism is proposed to focus on the fine-grained differences in the representation of each response candidate. Specifically, each candidate representation is compared with the whole history to obtain a history consistency representation. Furthermore, the consistency signals between each candidate and the speaker's own history are considered to drive a model to prefer a candidate that is logically consistent with the speaker's history logic. Finally, the above consistency representations are employed to output a ranking list of the candidate responses for multi-turn dialogue reasoning. Experimental results on two public dialogue datasets show that our method obtains higher ranking scores than the baseline models.
Identifying Untrustworthy Samples: Data Filtering for Open-domain Dialogues with Bayesian Optimization
Sep 14, 2021
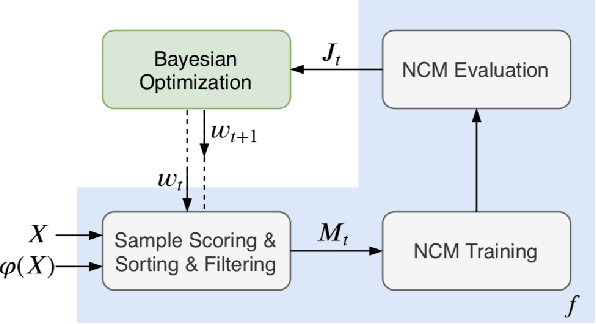
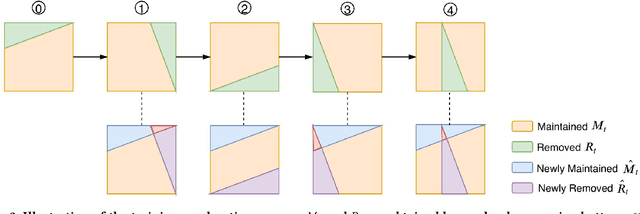
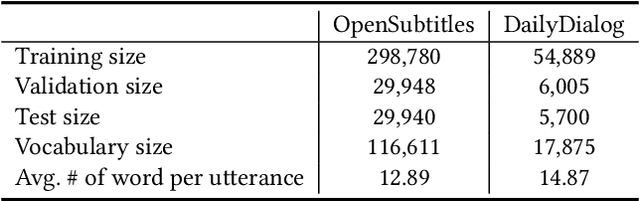
Being able to reply with a related, fluent, and informative response is an indispensable requirement for building high-quality conversational agents. In order to generate better responses, some approaches have been proposed, such as feeding extra information by collecting large-scale datasets with human annotations, designing neural conversational models (NCMs) with complex architecture and loss functions, or filtering out untrustworthy samples based on a dialogue attribute, e.g., Relatedness or Genericness. In this paper, we follow the third research branch and present a data filtering method for open-domain dialogues, which identifies untrustworthy samples from training data with a quality measure that linearly combines seven dialogue attributes. The attribute weights are obtained via Bayesian Optimization (BayesOpt) that aims to optimize an objective function for dialogue generation iteratively on the validation set. Then we score training samples with the quality measure, sort them in descending order, and filter out those at the bottom. Furthermore, to accelerate the "filter-train-evaluate" iterations involved in BayesOpt on large-scale datasets, we propose a training framework that integrates maximum likelihood estimation (MLE) and negative training method (NEG). The training method updates parameters of a trained NCMs on two small sets with newly maintained and removed samples, respectively. Specifically, MLE is applied to maximize the log-likelihood of newly maintained samples, while NEG is used to minimize the log-likelihood of newly removed ones. Experimental results on two datasets show that our method can effectively identify untrustworthy samples, and NCMs trained on the filtered datasets achieve better performance.
Topic-Aware Contrastive Learning for Abstractive Dialogue Summarization
Sep 10, 2021
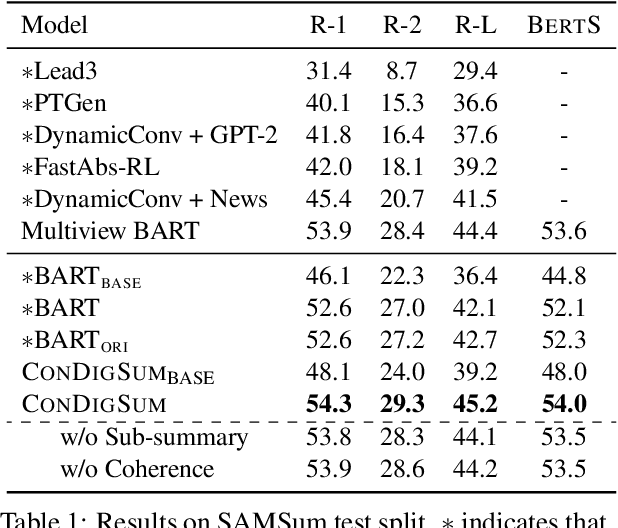
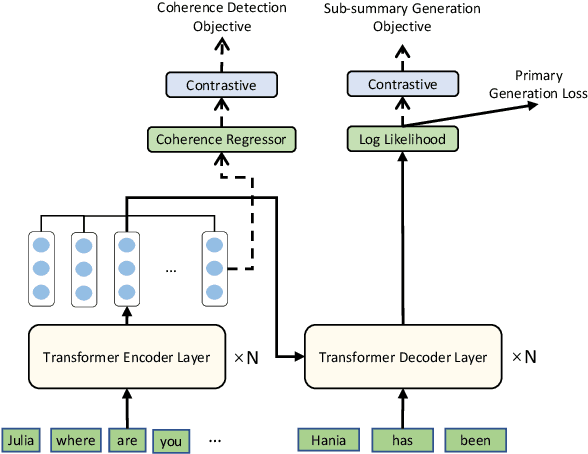
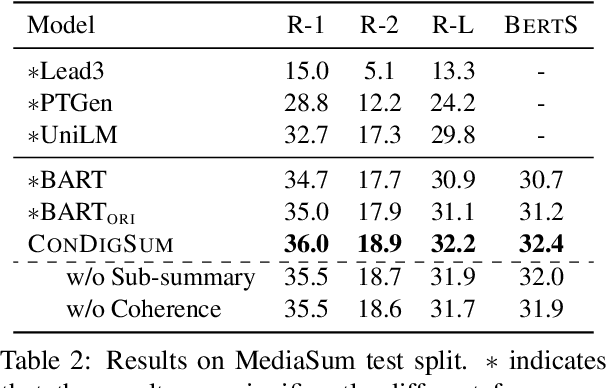
Unlike well-structured text, such as news reports and encyclopedia articles, dialogue content often comes from two or more interlocutors, exchanging information with each other. In such a scenario, the topic of a conversation can vary upon progression and the key information for a certain topic is often scattered across multiple utterances of different speakers, which poses challenges to abstractly summarize dialogues. To capture the various topic information of a conversation and outline salient facts for the captured topics, this work proposes two topic-aware contrastive learning objectives, namely coherence detection and sub-summary generation objectives, which are expected to implicitly model the topic change and handle information scattering challenges for the dialogue summarization task. The proposed contrastive objectives are framed as auxiliary tasks for the primary dialogue summarization task, united via an alternative parameter updating strategy. Extensive experiments on benchmark datasets demonstrate that the proposed simple method significantly outperforms strong baselines and achieves new state-of-the-art performance. The code and trained models are publicly available via \href{https://github.com/Junpliu/ConDigSum}{https://github.com/Junpliu/ConDigSum}.
Improving Sequential Recommendation Consistency with Self-Supervised Imitation
Jun 29, 2021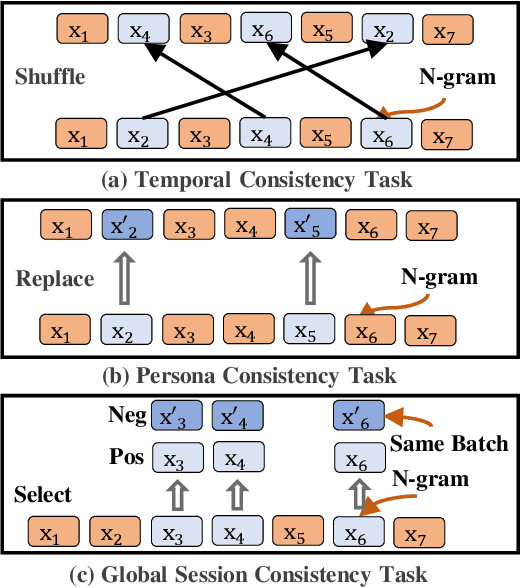
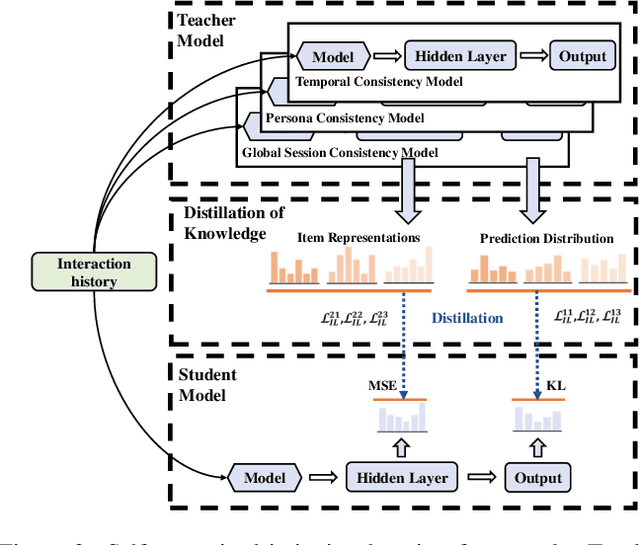
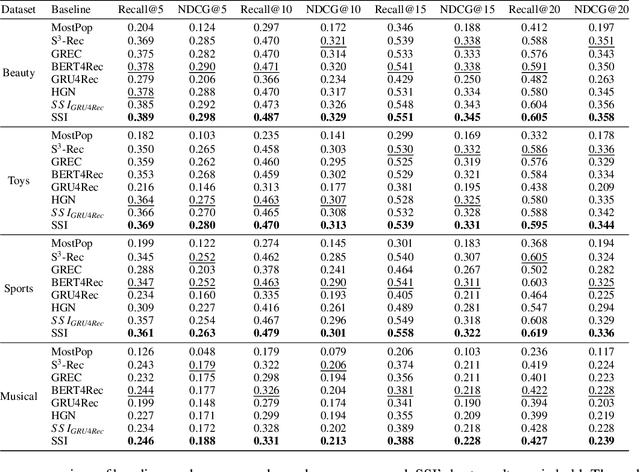
Most sequential recommendation models capture the features of consecutive items in a user-item interaction history. Though effective, their representation expressiveness is still hindered by the sparse learning signals. As a result, the sequential recommender is prone to make inconsistent predictions. In this paper, we propose a model, SSI, to improve sequential recommendation consistency with Self-Supervised Imitation. Precisely, we extract the consistency knowledge by utilizing three self-supervised pre-training tasks, where temporal consistency and persona consistency capture user-interaction dynamics in terms of the chronological order and persona sensitivities, respectively. Furthermore, to provide the model with a global perspective, global session consistency is introduced by maximizing the mutual information among global and local interaction sequences. Finally, to comprehensively take advantage of all three independent aspects of consistency-enhanced knowledge, we establish an integrated imitation learning framework. The consistency knowledge is effectively internalized and transferred to the student model by imitating the conventional prediction logit as well as the consistency-enhanced item representations. In addition, the flexible self-supervised imitation framework can also benefit other student recommenders. Experiments on four real-world datasets show that SSI effectively outperforms the state-of-the-art sequential recommendation methods.
Probing Product Description Generation via Posterior Distillation
Mar 02, 2021

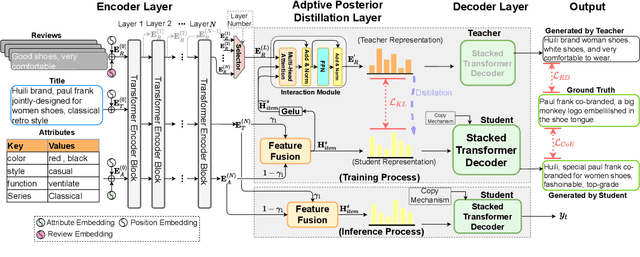

In product description generation (PDG), the user-cared aspect is critical for the recommendation system, which can not only improve user's experiences but also obtain more clicks. High-quality customer reviews can be considered as an ideal source to mine user-cared aspects. However, in reality, a large number of new products (known as long-tailed commodities) cannot gather sufficient amount of customer reviews, which brings a big challenge in the product description generation task. Existing works tend to generate the product description solely based on item information, i.e., product attributes or title words, which leads to tedious contents and cannot attract customers effectively. To tackle this problem, we propose an adaptive posterior network based on Transformer architecture that can utilize user-cared information from customer reviews. Specifically, we first extend the self-attentive Transformer encoder to encode product titles and attributes. Then, we apply an adaptive posterior distillation module to utilize useful review information, which integrates user-cared aspects to the generation process. Finally, we apply a Transformer-based decoding phase with copy mechanism to automatically generate the product description. Besides, we also collect a large-scare Chinese product description dataset to support our work and further research in this field. Experimental results show that our model is superior to traditional generative models in both automatic indicators and human evaluation.
User-Inspired Posterior Network for Recommendation Reason Generation
Feb 16, 2021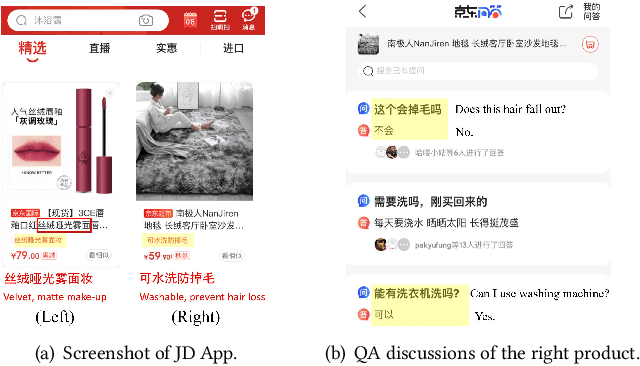
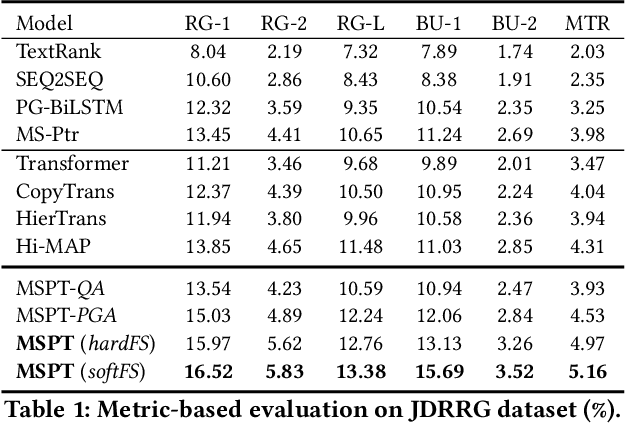
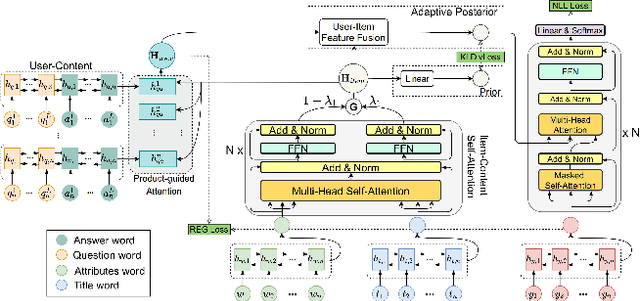
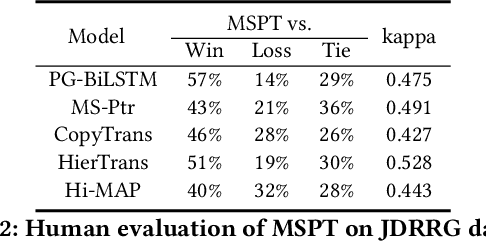
Recommendation reason generation, aiming at showing the selling points of products for customers, plays a vital role in attracting customers' attention as well as improving user experience. A simple and effective way is to extract keywords directly from the knowledge-base of products, i.e., attributes or title, as the recommendation reason. However, generating recommendation reason from product knowledge doesn't naturally respond to users' interests. Fortunately, on some E-commerce websites, there exists more and more user-generated content (user-content for short), i.e., product question-answering (QA) discussions, which reflect user-cared aspects. Therefore, in this paper, we consider generating the recommendation reason by taking into account not only the product attributes but also the customer-generated product QA discussions. In reality, adequate user-content is only possible for the most popular commodities, whereas large sums of long-tail products or new products cannot gather a sufficient number of user-content. To tackle this problem, we propose a user-inspired multi-source posterior transformer (MSPT), which induces the model reflecting the users' interests with a posterior multiple QA discussions module, and generating recommendation reasons containing the product attributes as well as the user-cared aspects. Experimental results show that our model is superior to traditional generative models. Additionally, the analysis also shows that our model can focus more on the user-cared aspects than baselines.