 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReformulating Conversational Recommender Systems as Tri-Phase Offline Policy Learning
Aug 13, 2024Existing Conversational Recommender Systems (CRS) predominantly utilize user simulators for training and evaluating recommendation policies. These simulators often oversimplify the complexity of user interactions by focusing solely on static item attributes, neglecting the rich, evolving preferences that characterize real-world user behavior. This limitation frequently leads to models that perform well in simulated environments but falter in actual deployment. Addressing these challenges, this paper introduces the Tri-Phase Offline Policy Learning-based Conversational Recommender System (TPCRS), which significantly reduces dependency on real-time interactions and mitigates overfitting issues prevalent in traditional approaches. TPCRS integrates a model-based offline learning strategy with a controllable user simulation that dynamically aligns with both personalized and evolving user preferences. Through comprehensive experiments, TPCRS demonstrates enhanced robustness, adaptability, and accuracy in recommendations, outperforming traditional CRS models in diverse user scenarios. This approach not only provides a more realistic evaluation environment but also facilitates a deeper understanding of user behavior dynamics, thereby refining the recommendation process.
Embracing Uncertainty: Adaptive Vague Preference Policy Learning for Multi-round Conversational Recommendation
Jun 07, 2023

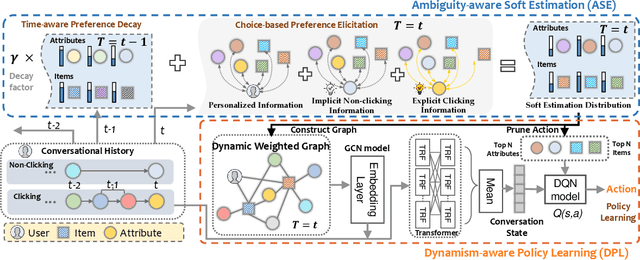
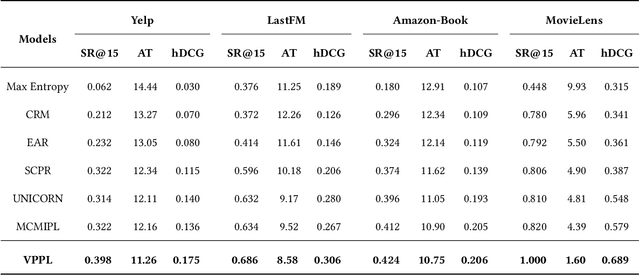
Conversational recommendation systems (CRS) effectively address information asymmetry by dynamically eliciting user preferences through multi-turn interactions. Existing CRS widely assumes that users have clear preferences. Under this assumption, the agent will completely trust the user feedback and treat the accepted or rejected signals as strong indicators to filter items and reduce the candidate space, which may lead to the problem of over-filtering. However, in reality, users' preferences are often vague and volatile, with uncertainty about their desires and changing decisions during interactions. To address this issue, we introduce a novel scenario called Vague Preference Multi-round Conversational Recommendation (VPMCR), which considers users' vague and volatile preferences in CRS.VPMCR employs a soft estimation mechanism to assign a non-zero confidence score for all candidate items to be displayed, naturally avoiding the over-filtering problem. In the VPMCR setting, we introduce an solution called Adaptive Vague Preference Policy Learning (AVPPL), which consists of two main components: Uncertainty-aware Soft Estimation (USE) and Uncertainty-aware Policy Learning (UPL). USE estimates the uncertainty of users' vague feedback and captures their dynamic preferences using a choice-based preferences extraction module and a time-aware decaying strategy. UPL leverages the preference distribution estimated by USE to guide the conversation and adapt to changes in users' preferences to make recommendations or ask for attributes. Our extensive experiments demonstrate the effectiveness of our method in the VPMCR scenario, highlighting its potential for practical applications and improving the overall performance and applicability of CRS in real-world settings, particularly for users with vague or dynamic preferences.