 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDC-Reg: Globally Optimal Point Cloud Registration via Tight Bounding with Difference of Convex Programming
Mar 26, 2026Achieving globally optimal point cloud registration under partial overlaps and large misalignments remains a fundamental challenge. While simultaneous transformation ($\boldsymbolθ$) and correspondence ($\mathbf{P}$) estimation has the advantage of being robust to nonrigid deformation, its non-convex coupled objective often leads to local minima for heuristic methods and prohibitive convergence times for existing global solvers due to loose lower bounds. To address this, we propose DC-Reg, a robust globally optimal framework that significantly tightens the Branch-and-Bound (BnB) search. Our core innovation is the derivation of a holistic concave underestimator for the coupled transformation-assignment objective, grounded in the Difference of Convex (DC) programming paradigm. Unlike prior works that rely on term-wise relaxations (e.g., McCormick envelopes) which neglect variable interplay, our holistic DC decomposition captures the joint structural interaction between $\boldsymbolθ$ and $\mathbf{P}$. This formulation enables the computation of remarkably tight lower bounds via efficient Linear Assignment Problems (LAP) evaluated at the vertices of the search boxes. We validate our framework on 2D similarity and 3D rigid registration, utilizing rotation-invariant features for the latter to achieve high efficiency without sacrificing optimality. Experimental results on synthetic data and the 3DMatch benchmark demonstrate that DC-Reg achieves significantly faster convergence and superior robustness to extreme noise and outliers compared to state-of-the-art global techniques.
LPIPS-AttnWav2Lip: Generic Audio-Driven lip synchronization for Talking Head Generation in the Wild
Jan 30, 2026Researchers have shown a growing interest in Audio-driven Talking Head Generation. The primary challenge in talking head generation is achieving audio-visual coherence between the lips and the audio, known as lip synchronization. This paper proposes a generic method, LPIPS-AttnWav2Lip, for reconstructing face images of any speaker based on audio. We used the U-Net architecture based on residual CBAM to better encode and fuse audio and visual modal information. Additionally, the semantic alignment module extends the receptive field of the generator network to obtain the spatial and channel information of the visual features efficiently; and match statistical information of visual features with audio latent vector to achieve the adjustment and injection of the audio content information to the visual information. To achieve exact lip synchronization and to generate realistic high-quality images, our approach adopts LPIPS Loss, which simulates human judgment of image quality and reduces instability possibility during the training process. The proposed method achieves outstanding performance in terms of lip synchronization accuracy and visual quality as demonstrated by subjective and objective evaluation results. The code for the paper is available at the following link: https://github.com/FelixChan9527/LPIPS-AttnWav2Lip
* This paper has been accepted by Elsevier's \textit{Speech Communication} journal. Official publication link: https://doi.org/10.1016/j.specom.2023.103028 The code for the paper is available at the following link: https://github.com/FelixChan9527/LPIPS-AttnWav2Lip
Proactive Recommendation in Social Networks: Steering User Interest via Neighbor Influence
Sep 13, 2024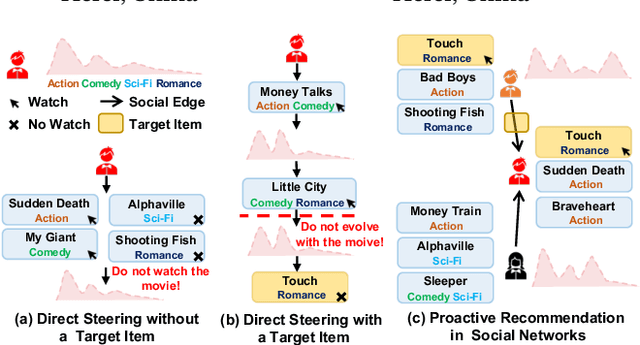
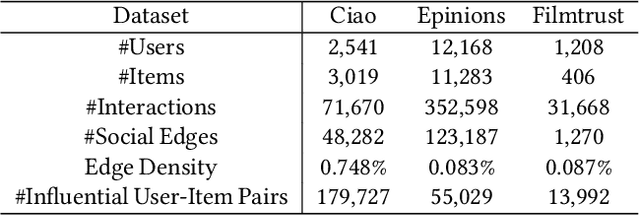
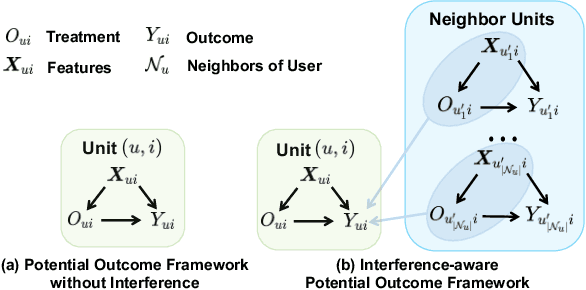
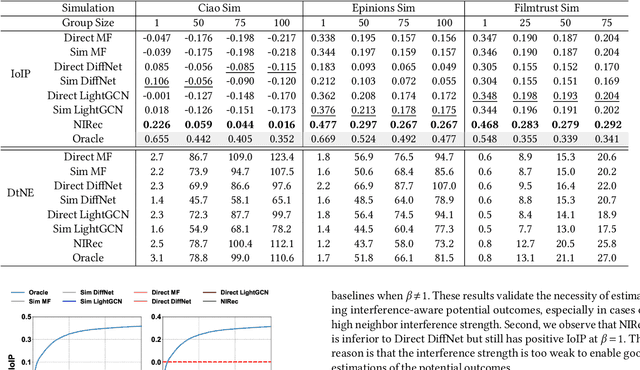
Recommending items solely catering to users' historical interests narrows users' horizons. Recent works have considered steering target users beyond their historical interests by directly adjusting items exposed to them. However, the recommended items for direct steering might not align perfectly with users' interests evolution, detrimentally affecting target users' experience. To avoid this issue, we propose a new task named Proactive Recommendation in Social Networks (PRSN) that indirectly steers users' interest by utilizing the influence of social neighbors, i.e., indirect steering by adjusting the exposure of a target item to target users' neighbors. The key to PRSN lies in answering an interventional question: what would a target user's feedback be on a target item if the item is exposed to the user's different neighbors? To answer this question, we resort to causal inference and formalize PRSN as: (1) estimating the potential feedback of a user on an item, under the network interference by the item's exposure to the user's neighbors; and (2) adjusting the exposure of a target item to target users' neighbors to trade off steering performance and the damage to the neighbors' experience. To this end, we propose a Neighbor Interference Recommendation (NIRec) framework with two key modules: (1)an interference representation-based estimation module for modeling potential feedback; and (2) a post-learning-based optimization module for optimizing a target item's exposure to trade off steering performance and the neighbors' experience by greedy search. We conduct extensive semi-simulation experiments based on three real-world datasets, validating the steering effectiveness of NIRec.
Debias Can be Unreliable: Mitigating Bias Issue in Evaluating Debiasing Recommendation
Sep 07, 2024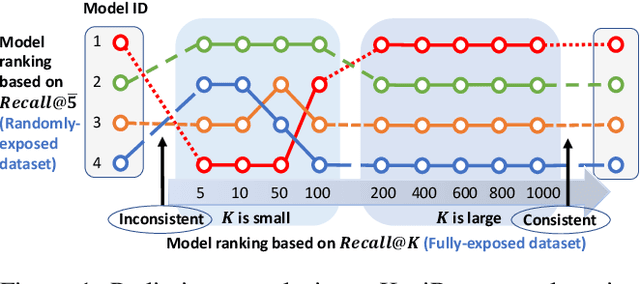
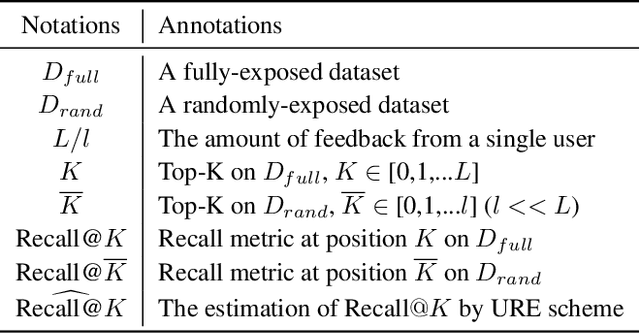
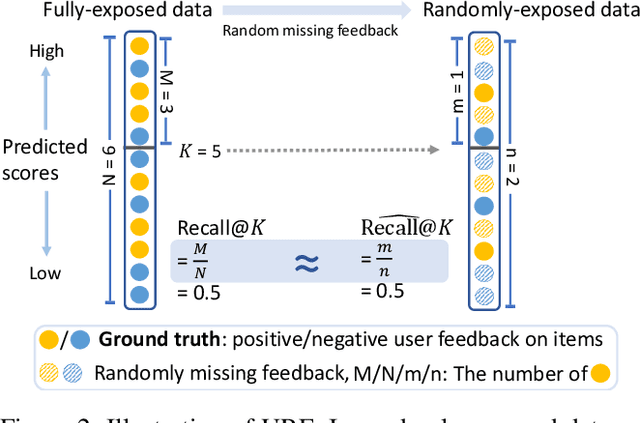

Recent work has improved recommendation models remarkably by equipping them with debiasing methods. Due to the unavailability of fully-exposed datasets, most existing approaches resort to randomly-exposed datasets as a proxy for evaluating debiased models, employing traditional evaluation scheme to represent the recommendation performance. However, in this study, we reveal that traditional evaluation scheme is not suitable for randomly-exposed datasets, leading to inconsistency between the Recall performance obtained using randomly-exposed datasets and that obtained using fully-exposed datasets. Such inconsistency indicates the potential unreliability of experiment conclusions on previous debiasing techniques and calls for unbiased Recall evaluation using randomly-exposed datasets. To bridge the gap, we propose the Unbiased Recall Evaluation (URE) scheme, which adjusts the utilization of randomly-exposed datasets to unbiasedly estimate the true Recall performance on fully-exposed datasets. We provide theoretical evidence to demonstrate the rationality of URE and perform extensive experiments on real-world datasets to validate its soundness.
Reformulating Conversational Recommender Systems as Tri-Phase Offline Policy Learning
Aug 13, 2024Existing Conversational Recommender Systems (CRS) predominantly utilize user simulators for training and evaluating recommendation policies. These simulators often oversimplify the complexity of user interactions by focusing solely on static item attributes, neglecting the rich, evolving preferences that characterize real-world user behavior. This limitation frequently leads to models that perform well in simulated environments but falter in actual deployment. Addressing these challenges, this paper introduces the Tri-Phase Offline Policy Learning-based Conversational Recommender System (TPCRS), which significantly reduces dependency on real-time interactions and mitigates overfitting issues prevalent in traditional approaches. TPCRS integrates a model-based offline learning strategy with a controllable user simulation that dynamically aligns with both personalized and evolving user preferences. Through comprehensive experiments, TPCRS demonstrates enhanced robustness, adaptability, and accuracy in recommendations, outperforming traditional CRS models in diverse user scenarios. This approach not only provides a more realistic evaluation environment but also facilitates a deeper understanding of user behavior dynamics, thereby refining the recommendation process.
Variable Substitution and Bilinear Programming for Aligning Partially Overlapping Point Sets
May 14, 2024In many applications, the demand arises for algorithms capable of aligning partially overlapping point sets while remaining invariant to the corresponding transformations. This research presents a method designed to meet such requirements through minimization of the objective function of the robust point matching (RPM) algorithm. First, we show that the RPM objective is a cubic polynomial. Then, through variable substitution, we transform the RPM objective to a quadratic function. Leveraging the convex envelope of bilinear monomials, we proceed to relax the resulting objective function, thus obtaining a lower bound problem that can be conveniently decomposed into distinct linear assignment and low-dimensional convex quadratic program components, both amenable to efficient optimization. Furthermore, a branch-and-bound (BnB) algorithm is devised, which solely branches over the transformation parameters, thereby boosting convergence rate. Empirical evaluations demonstrate better robustness of the proposed methodology against non-rigid deformation, positional noise, and outliers, particularly in scenarios where outliers remain distinct from inliers, when compared with prevailing state-of-the-art approaches.
Proactive Recommendation with Iterative Preference Guidance
Mar 12, 2024Recommender systems mainly tailor personalized recommendations according to user interests learned from user feedback. However, such recommender systems passively cater to user interests and even reinforce existing interests in the feedback loop, leading to problems like filter bubbles and opinion polarization. To counteract this, proactive recommendation actively steers users towards developing new interests in a target item or topic by strategically modulating recommendation sequences. Existing work for proactive recommendation faces significant hurdles: 1) overlooking the user feedback in the guidance process; 2) lacking explicit modeling of the guiding objective; and 3) insufficient flexibility for integration into existing industrial recommender systems. To address these issues, we introduce an Iterative Preference Guidance (IPG) framework. IPG performs proactive recommendation in a flexible post-processing manner by ranking items according to their IPG scores that consider both interaction probability and guiding value. These scores are explicitly estimated with iteratively updated user representation that considers the most recent user interactions. Extensive experiments validate that IPG can effectively guide user interests toward target interests with a reasonable trade-off in recommender accuracy. The code is available at https://github.com/GabyUSTC/IPG-Rec.