 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePERM: Psychology-grounded Empathetic Reward Modeling for Large Language Models
Jan 16, 2026Large Language Models (LLMs) are increasingly deployed in human-centric applications, yet they often fail to provide substantive emotional support. While Reinforcement Learning (RL) has been utilized to enhance empathy of LLMs, existing reward models typically evaluate empathy from a single perspective, overlooking the inherently bidirectional interaction nature of empathy between the supporter and seeker as defined by Empathy Cycle theory. To address this limitation, we propose Psychology-grounded Empathetic Reward Modeling (PERM). PERM operationalizes empathy evaluation through a bidirectional decomposition: 1) Supporter perspective, assessing internal resonation and communicative expression; 2) Seeker perspective, evaluating emotional reception. Additionally, it incorporates a bystander perspective to monitor overall interaction quality. Extensive experiments on a widely-used emotional intelligence benchmark and an industrial daily conversation dataset demonstrate that PERM outperforms state-of-the-art baselines by over 10\%. Furthermore, a blinded user study reveals a 70\% preference for our approach, highlighting its efficacy in generating more empathetic responses. Our code, dataset, and models are available at https://github.com/ZhengWwwq/PERM.
Leveraging Memory Retrieval to Enhance LLM-based Generative Recommendation
Dec 23, 2024



Leveraging Large Language Models (LLMs) to harness user-item interaction histories for item generation has emerged as a promising paradigm in generative recommendation. However, the limited context window of LLMs often restricts them to focusing on recent user interactions only, leading to the neglect of long-term interests involved in the longer histories. To address this challenge, we propose a novel Automatic Memory-Retrieval framework (AutoMR), which is capable of storing long-term interests in the memory and extracting relevant information from it for next-item generation within LLMs. Extensive experimental results on two real-world datasets demonstrate the effectiveness of our proposed AutoMR framework in utilizing long-term interests for generative recommendation.
Debias Can be Unreliable: Mitigating Bias Issue in Evaluating Debiasing Recommendation
Sep 07, 2024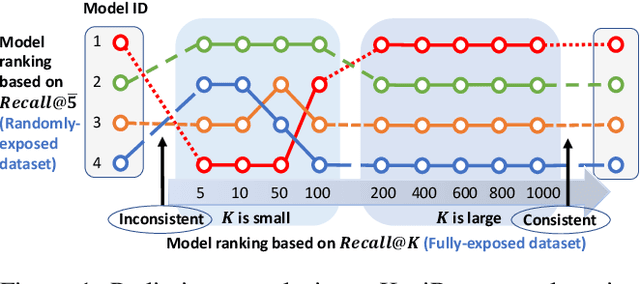
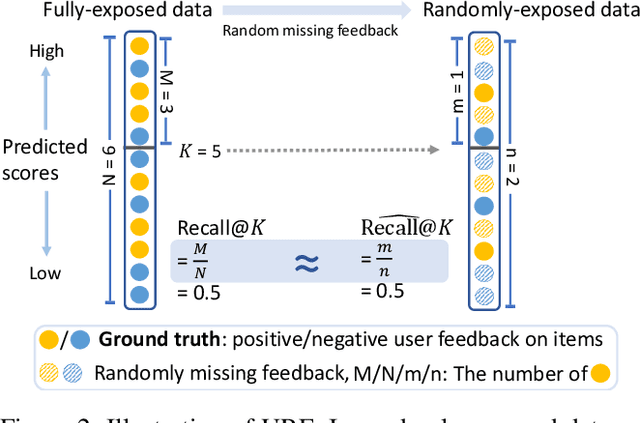

Recent work has improved recommendation models remarkably by equipping them with debiasing methods. Due to the unavailability of fully-exposed datasets, most existing approaches resort to randomly-exposed datasets as a proxy for evaluating debiased models, employing traditional evaluation scheme to represent the recommendation performance. However, in this study, we reveal that traditional evaluation scheme is not suitable for randomly-exposed datasets, leading to inconsistency between the Recall performance obtained using randomly-exposed datasets and that obtained using fully-exposed datasets. Such inconsistency indicates the potential unreliability of experiment conclusions on previous debiasing techniques and calls for unbiased Recall evaluation using randomly-exposed datasets. To bridge the gap, we propose the Unbiased Recall Evaluation (URE) scheme, which adjusts the utilization of randomly-exposed datasets to unbiasedly estimate the true Recall performance on fully-exposed datasets. We provide theoretical evidence to demonstrate the rationality of URE and perform extensive experiments on real-world datasets to validate its soundness.