 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFCM: A Fine-grained Comparison Model for Multi-turn Dialogue Reasoning
Paper and Code

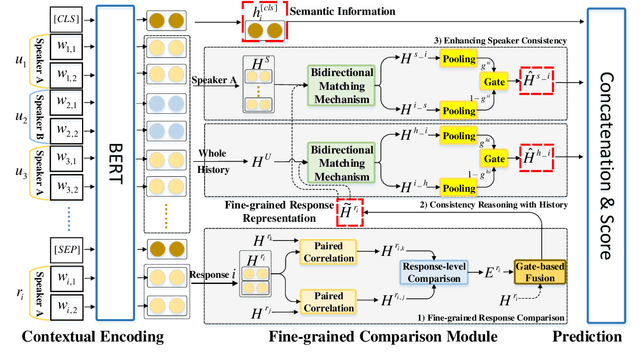
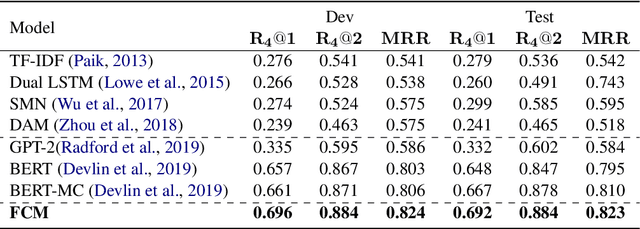

Despite the success of neural dialogue systems in achieving high performance on the leader-board, they cannot meet users' requirements in practice, due to their poor reasoning skills. The underlying reason is that most neural dialogue models only capture the syntactic and semantic information, but fail to model the logical consistency between the dialogue history and the generated response. Recently, a new multi-turn dialogue reasoning task has been proposed, to facilitate dialogue reasoning research. However, this task is challenging, because there are only slight differences between the illogical response and the dialogue history. How to effectively solve this challenge is still worth exploring. This paper proposes a Fine-grained Comparison Model (FCM) to tackle this problem. Inspired by human's behavior in reading comprehension, a comparison mechanism is proposed to focus on the fine-grained differences in the representation of each response candidate. Specifically, each candidate representation is compared with the whole history to obtain a history consistency representation. Furthermore, the consistency signals between each candidate and the speaker's own history are considered to drive a model to prefer a candidate that is logically consistent with the speaker's history logic. Finally, the above consistency representations are employed to output a ranking list of the candidate responses for multi-turn dialogue reasoning. Experimental results on two public dialogue datasets show that our method obtains higher ranking scores than the baseline models.