 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTriLoRA: Integrating SVD for Advanced Style Personalization in Text-to-Image Generation
May 18, 2024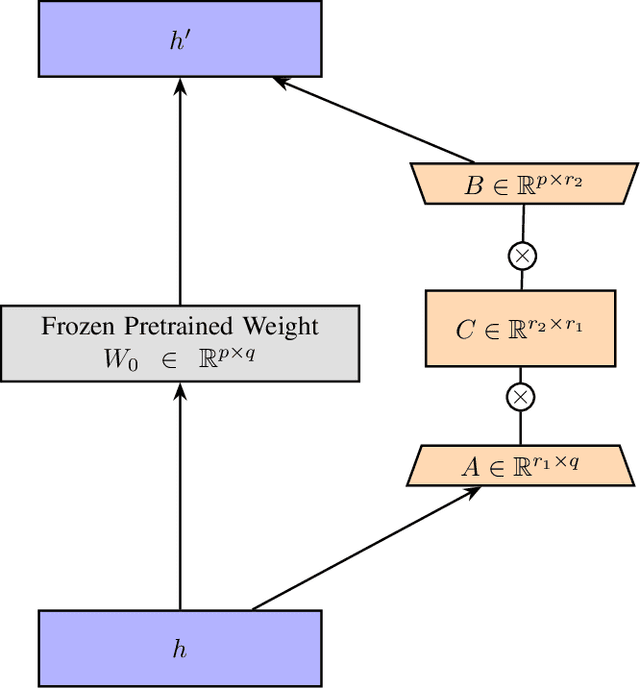
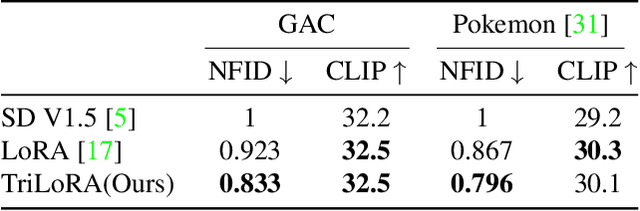

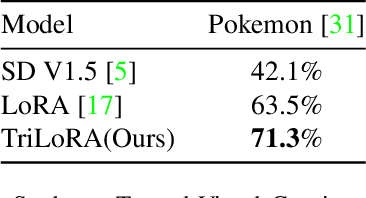
As deep learning technology continues to advance, image generation models, especially models like Stable Diffusion, are finding increasingly widespread application in visual arts creation. However, these models often face challenges such as overfitting, lack of stability in generated results, and difficulties in accurately capturing the features desired by creators during the fine-tuning process. In response to these challenges, we propose an innovative method that integrates Singular Value Decomposition (SVD) into the Low-Rank Adaptation (LoRA) parameter update strategy, aimed at enhancing the fine-tuning efficiency and output quality of image generation models. By incorporating SVD within the LoRA framework, our method not only effectively reduces the risk of overfitting but also enhances the stability of model outputs, and captures subtle, creator-desired feature adjustments more accurately. We evaluated our method on multiple datasets, and the results show that, compared to traditional fine-tuning methods, our approach significantly improves the model's generalization ability and creative flexibility while maintaining the quality of generation. Moreover, this method maintains LoRA's excellent performance under resource-constrained conditions, allowing for significant improvements in image generation quality without sacrificing the original efficiency and resource advantages.
Text is NOT Enough: Integrating Visual Impressions into Open-domain Dialogue Generation
Sep 18, 2021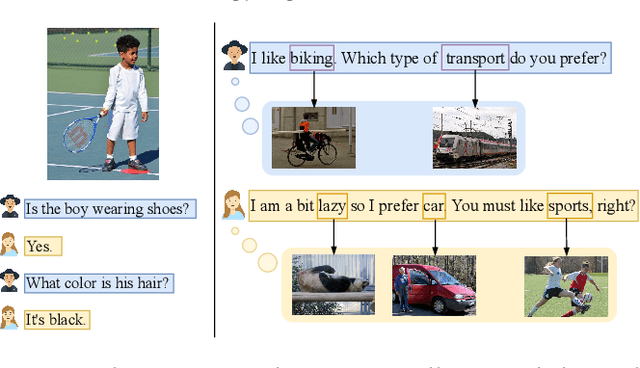
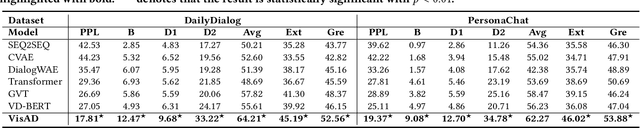
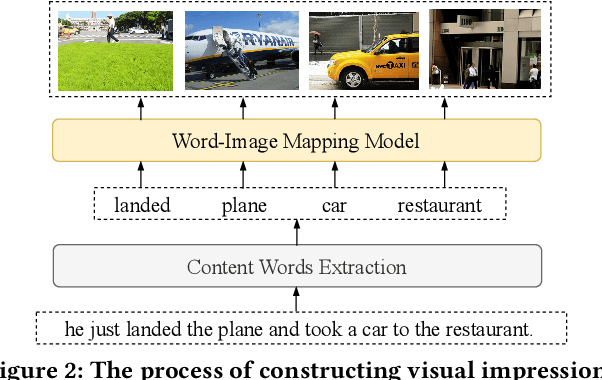
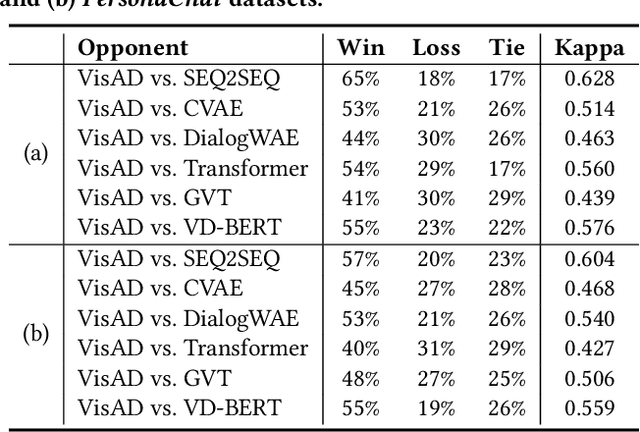
Open-domain dialogue generation in natural language processing (NLP) is by default a pure-language task, which aims to satisfy human need for daily communication on open-ended topics by producing related and informative responses. In this paper, we point out that hidden images, named as visual impressions (VIs), can be explored from the text-only data to enhance dialogue understanding and help generate better responses. Besides, the semantic dependency between an dialogue post and its response is complicated, e.g., few word alignments and some topic transitions. Therefore, the visual impressions of them are not shared, and it is more reasonable to integrate the response visual impressions (RVIs) into the decoder, rather than the post visual impressions (PVIs). However, both the response and its RVIs are not given directly in the test process. To handle the above issues, we propose a framework to explicitly construct VIs based on pure-language dialogue datasets and utilize them for better dialogue understanding and generation. Specifically, we obtain a group of images (PVIs) for each post based on a pre-trained word-image mapping model. These PVIs are used in a co-attention encoder to get a post representation with both visual and textual information. Since the RVIs are not provided directly during testing, we design a cascade decoder that consists of two sub-decoders. The first sub-decoder predicts the content words in response, and applies the word-image mapping model to get those RVIs. Then, the second sub-decoder generates the response based on the post and RVIs. Experimental results on two open-domain dialogue datasets show that our proposed approach achieves superior performance over competitive baselines.
Constructing Emotion Consensus and Utilizing Unpaired Data for Empathetic Dialogue Generation
Sep 18, 2021
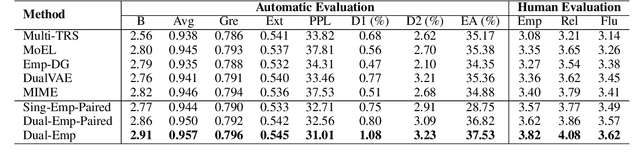
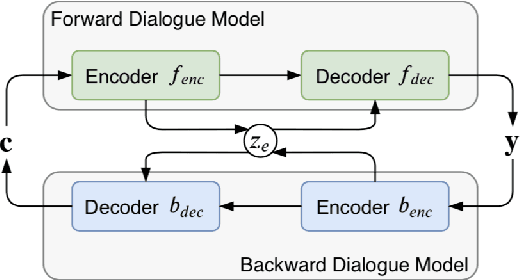
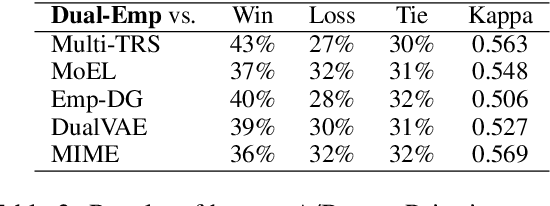
Researches on dialogue empathy aim to endow an agent with the capacity of accurate understanding and proper responding for emotions. Existing models for empathetic dialogue generation focus on the emotion flow in one direction, that is, from the context to response. We argue that conducting an empathetic conversation is a bidirectional process, where empathy occurs when the emotions of two interlocutors could converge on the same point, i.e., reaching an emotion consensus. Besides, we also find that the empathetic dialogue corpus is extremely limited, which further restricts the model performance. To address the above issues, we propose a dual-generative model, Dual-Emp, to simultaneously construct the emotion consensus and utilize some external unpaired data. Specifically, our model integrates a forward dialogue model, a backward dialogue model, and a discrete latent variable representing the emotion consensus into a unified architecture. Then, to alleviate the constraint of paired data, we extract unpaired emotional data from open-domain conversations and employ Dual-Emp to produce pseudo paired empathetic samples, which is more efficient and low-cost than the human annotation. Automatic and human evaluations demonstrate that our method outperforms competitive baselines in producing coherent and empathetic responses.
Identifying Untrustworthy Samples: Data Filtering for Open-domain Dialogues with Bayesian Optimization
Sep 14, 2021
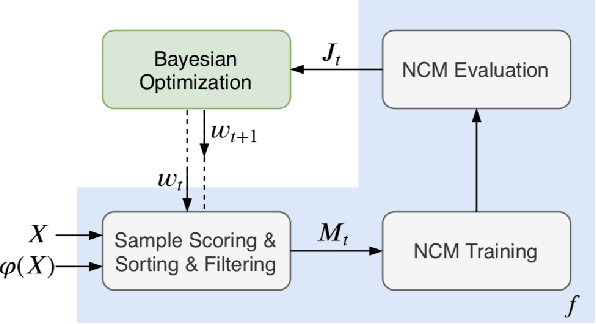
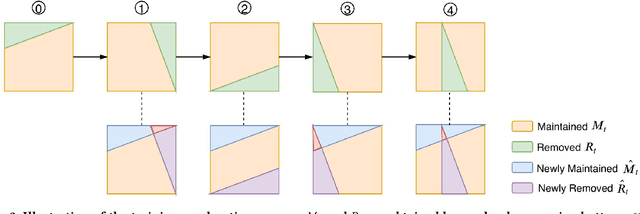
Being able to reply with a related, fluent, and informative response is an indispensable requirement for building high-quality conversational agents. In order to generate better responses, some approaches have been proposed, such as feeding extra information by collecting large-scale datasets with human annotations, designing neural conversational models (NCMs) with complex architecture and loss functions, or filtering out untrustworthy samples based on a dialogue attribute, e.g., Relatedness or Genericness. In this paper, we follow the third research branch and present a data filtering method for open-domain dialogues, which identifies untrustworthy samples from training data with a quality measure that linearly combines seven dialogue attributes. The attribute weights are obtained via Bayesian Optimization (BayesOpt) that aims to optimize an objective function for dialogue generation iteratively on the validation set. Then we score training samples with the quality measure, sort them in descending order, and filter out those at the bottom. Furthermore, to accelerate the "filter-train-evaluate" iterations involved in BayesOpt on large-scale datasets, we propose a training framework that integrates maximum likelihood estimation (MLE) and negative training method (NEG). The training method updates parameters of a trained NCMs on two small sets with newly maintained and removed samples, respectively. Specifically, MLE is applied to maximize the log-likelihood of newly maintained samples, while NEG is used to minimize the log-likelihood of newly removed ones. Experimental results on two datasets show that our method can effectively identify untrustworthy samples, and NCMs trained on the filtered datasets achieve better performance.
Improving Sequential Recommendation Consistency with Self-Supervised Imitation
Jun 29, 2021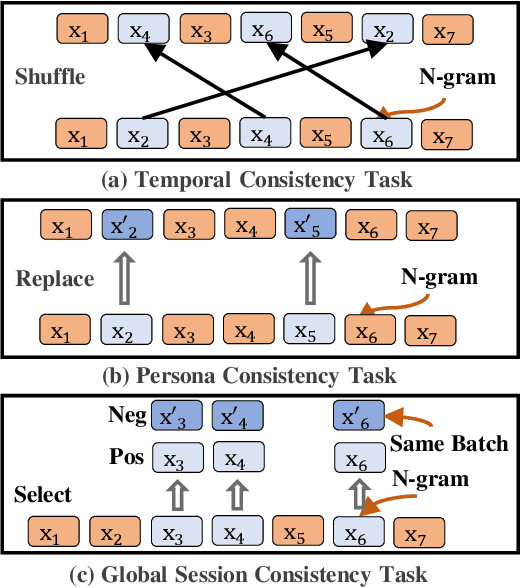
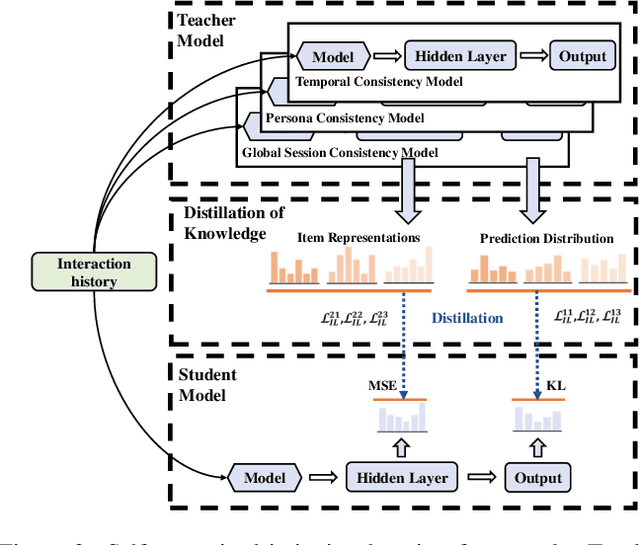
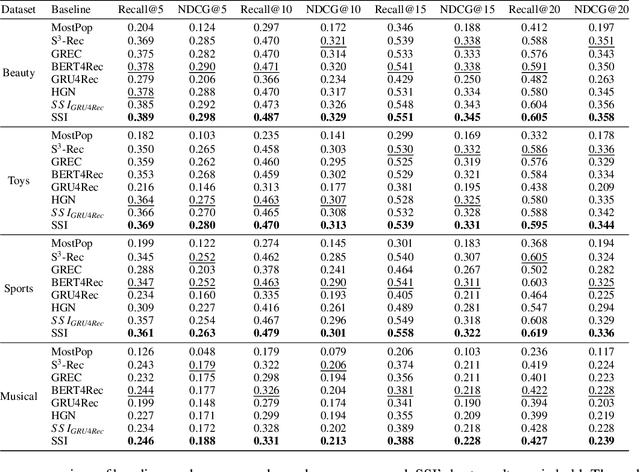
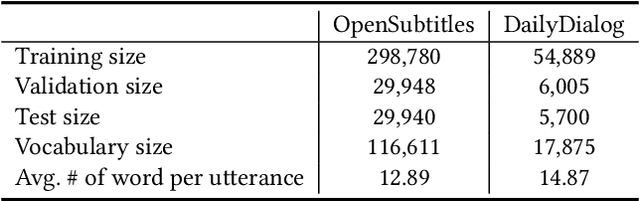
Most sequential recommendation models capture the features of consecutive items in a user-item interaction history. Though effective, their representation expressiveness is still hindered by the sparse learning signals. As a result, the sequential recommender is prone to make inconsistent predictions. In this paper, we propose a model, SSI, to improve sequential recommendation consistency with Self-Supervised Imitation. Precisely, we extract the consistency knowledge by utilizing three self-supervised pre-training tasks, where temporal consistency and persona consistency capture user-interaction dynamics in terms of the chronological order and persona sensitivities, respectively. Furthermore, to provide the model with a global perspective, global session consistency is introduced by maximizing the mutual information among global and local interaction sequences. Finally, to comprehensively take advantage of all three independent aspects of consistency-enhanced knowledge, we establish an integrated imitation learning framework. The consistency knowledge is effectively internalized and transferred to the student model by imitating the conventional prediction logit as well as the consistency-enhanced item representations. In addition, the flexible self-supervised imitation framework can also benefit other student recommenders. Experiments on four real-world datasets show that SSI effectively outperforms the state-of-the-art sequential recommendation methods.
TargetDrop: A Targeted Regularization Method for Convolutional Neural Networks
Oct 21, 2020
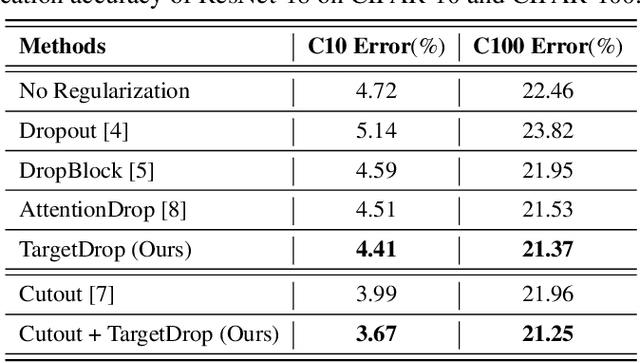
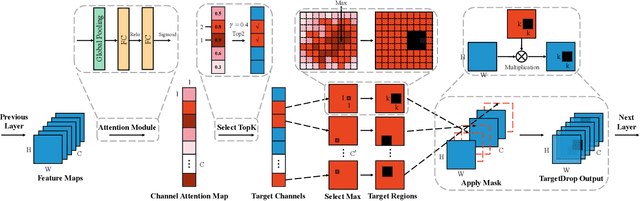
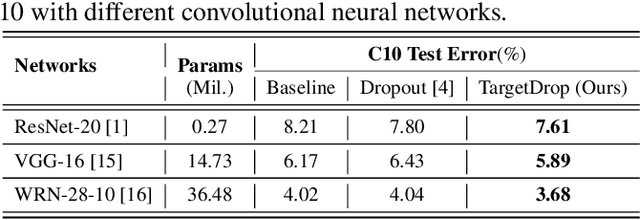
Dropout regularization has been widely used in deep learning but performs less effective for convolutional neural networks since the spatially correlated features allow dropped information to still flow through the networks. Some structured forms of dropout have been proposed to address this but prone to result in over or under regularization as features are dropped randomly. In this paper, we propose a targeted regularization method named TargetDrop which incorporates the attention mechanism to drop the discriminative feature units. Specifically, it masks out the target regions of the feature maps corresponding to the target channels. Experimental results compared with the other methods or applied for different networks demonstrate the regularization effect of our method.
Group-wise Contrastive Learning for Neural Dialogue Generation
Oct 13, 2020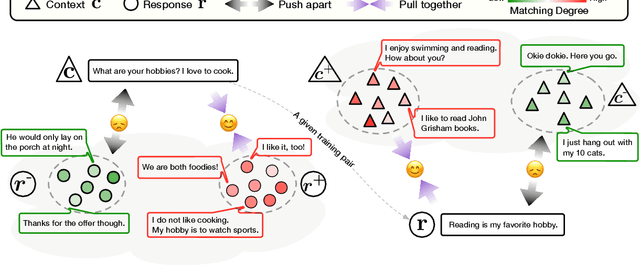
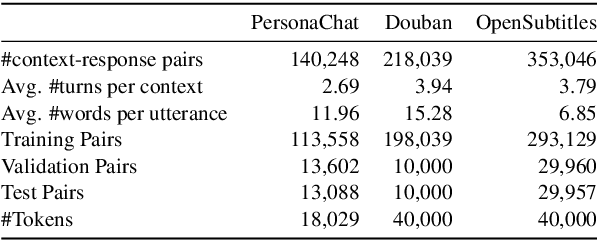
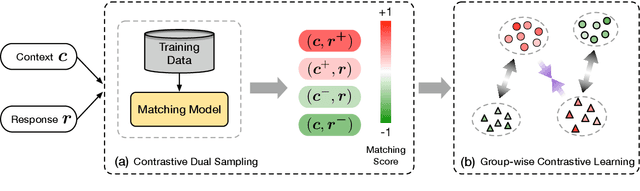
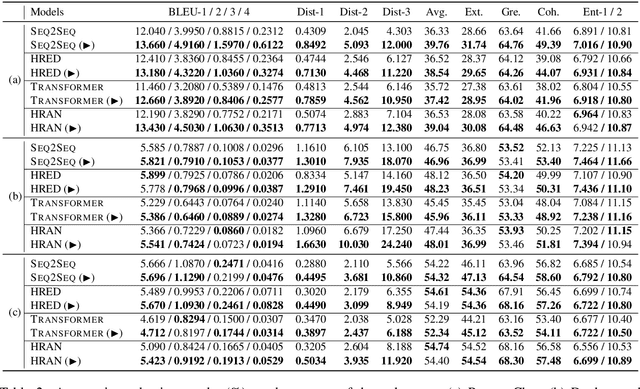
Neural dialogue response generation has gained much popularity in recent years. Maximum Likelihood Estimation (MLE) objective is widely adopted in existing dialogue model learning. However, models trained with MLE objective function are plagued by the low-diversity issue when it comes to the open-domain conversational setting. Inspired by the observation that humans not only learn from the positive signals but also benefit from correcting behaviors of undesirable actions, in this work, we introduce contrastive learning into dialogue generation, where the model explicitly perceives the difference between the well-chosen positive and negative utterances. Specifically, we employ a pretrained baseline model as a reference. During contrastive learning, the target dialogue model is trained to give higher conditional probabilities for the positive samples, and lower conditional probabilities for those negative samples, compared to the reference model. To manage the multi-mapping relations prevailed in human conversation, we augment contrastive dialogue learning with group-wise dual sampling. Extensive experimental results show that the proposed group-wise contrastive learning framework is suited for training a wide range of neural dialogue generation models with very favorable performance over the baseline training approaches.
Data Manipulation: Towards Effective Instance Learning for Neural Dialogue Generation via Learning to Augment and Reweight
Apr 07, 2020
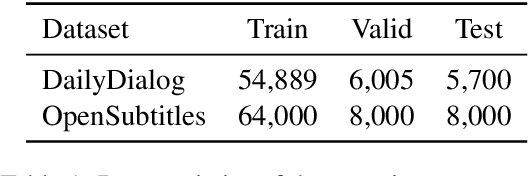
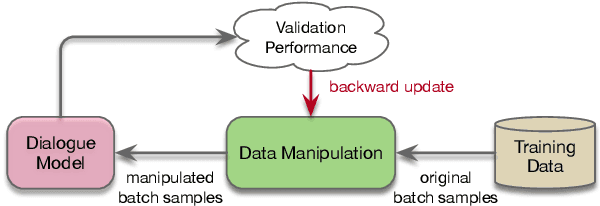
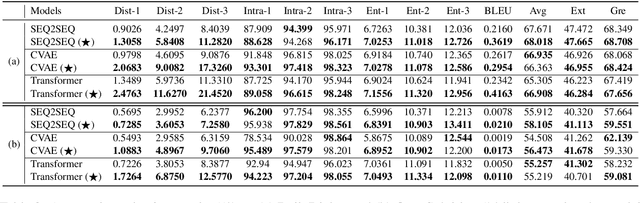
Current state-of-the-art neural dialogue models learn from human conversations following the data-driven paradigm. As such, a reliable training corpus is the crux of building a robust and well-behaved dialogue model. However, due to the open-ended nature of human conversations, the quality of user-generated training data varies greatly, and effective training samples are typically insufficient while noisy samples frequently appear. This impedes the learning of those data-driven neural dialogue models. Therefore, effective dialogue learning requires not only more reliable learning samples, but also fewer noisy samples. In this paper, we propose a data manipulation framework to proactively reshape the data distribution towards reliable samples by augmenting and highlighting effective learning samples as well as reducing the effect of inefficient samples simultaneously. In particular, the data manipulation model selectively augments the training samples and assigns an importance weight to each instance to reform the training data. Note that, the proposed data manipulation framework is fully data-driven and learnable. It not only manipulates training samples to optimize the dialogue generation model, but also learns to increase its manipulation skills through gradient descent with validation samples. Extensive experiments show that our framework can improve the dialogue generation performance with respect to 13 automatic evaluation metrics and human judgments.
Learning from Easy to Complex: Adaptive Multi-curricula Learning for Neural Dialogue Generation
Mar 16, 2020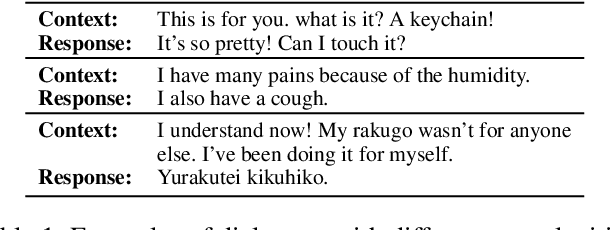
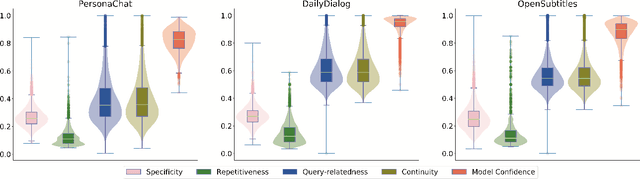
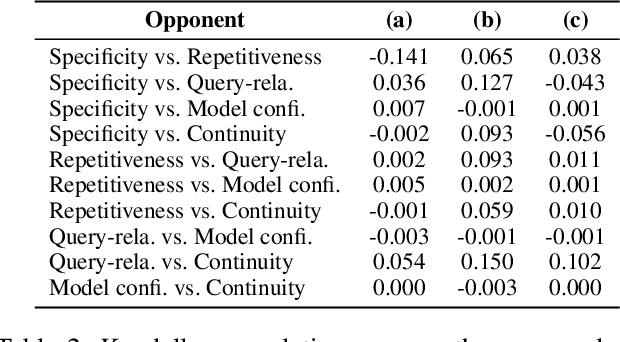
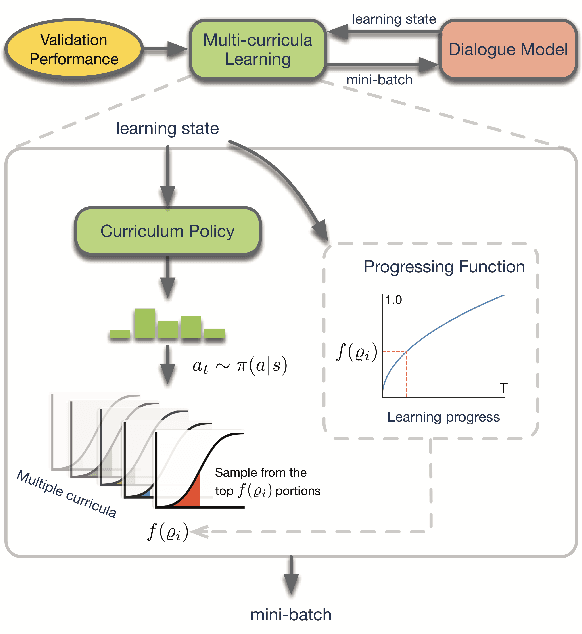
Current state-of-the-art neural dialogue systems are mainly data-driven and are trained on human-generated responses. However, due to the subjectivity and open-ended nature of human conversations, the complexity of training dialogues varies greatly. The noise and uneven complexity of query-response pairs impede the learning efficiency and effects of the neural dialogue generation models. What is more, so far, there are no unified dialogue complexity measurements, and the dialogue complexity embodies multiple aspects of attributes---specificity, repetitiveness, relevance, etc. Inspired by human behaviors of learning to converse, where children learn from easy dialogues to complex ones and dynamically adjust their learning progress, in this paper, we first analyze five dialogue attributes to measure the dialogue complexity in multiple perspectives on three publicly available corpora. Then, we propose an adaptive multi-curricula learning framework to schedule a committee of the organized curricula. The framework is established upon the reinforcement learning paradigm, which automatically chooses different curricula at the evolving learning process according to the learning status of the neural dialogue generation model. Extensive experiments conducted on five state-of-the-art models demonstrate its learning efficiency and effectiveness with respect to 13 automatic evaluation metrics and human judgments.
Adaptive Parameterization for Neural Dialogue Generation
Jan 18, 2020



Neural conversation systems generate responses based on the sequence-to-sequence (SEQ2SEQ) paradigm. Typically, the model is equipped with a single set of learned parameters to generate responses for given input contexts. When confronting diverse conversations, its adaptability is rather limited and the model is hence prone to generate generic responses. In this work, we propose an {\bf Ada}ptive {\bf N}eural {\bf D}ialogue generation model, \textsc{AdaND}, which manages various conversations with conversation-specific parameterization. For each conversation, the model generates parameters of the encoder-decoder by referring to the input context. In particular, we propose two adaptive parameterization mechanisms: a context-aware and a topic-aware parameterization mechanism. The context-aware parameterization directly generates the parameters by capturing local semantics of the given context. The topic-aware parameterization enables parameter sharing among conversations with similar topics by first inferring the latent topics of the given context and then generating the parameters with respect to the distributional topics. Extensive experiments conducted on a large-scale real-world conversational dataset show that our model achieves superior performance in terms of both quantitative metrics and human evaluations.