 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlexDuo: A Pluggable System for Enabling Full-Duplex Capabilities in Speech Dialogue Systems
Feb 19, 2025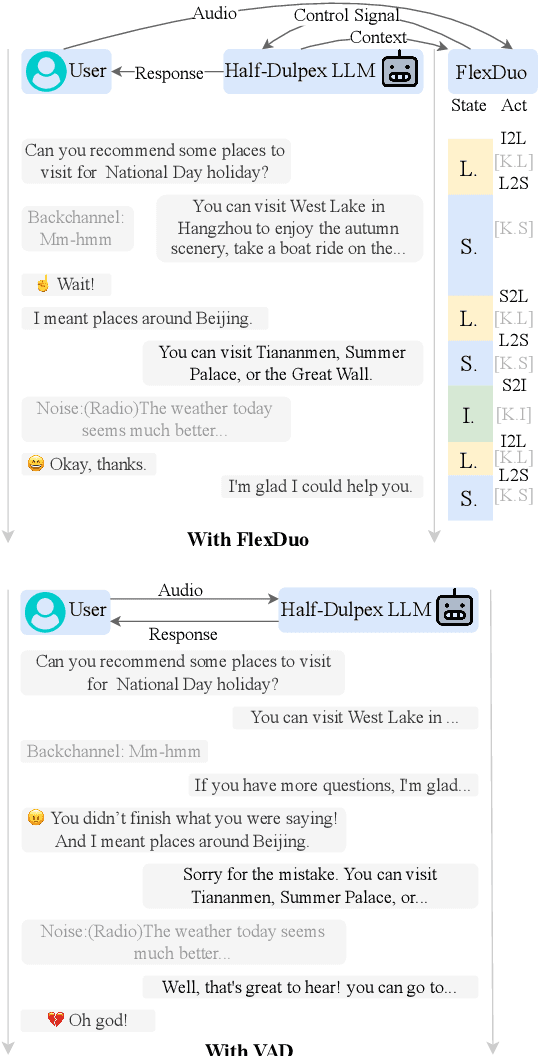

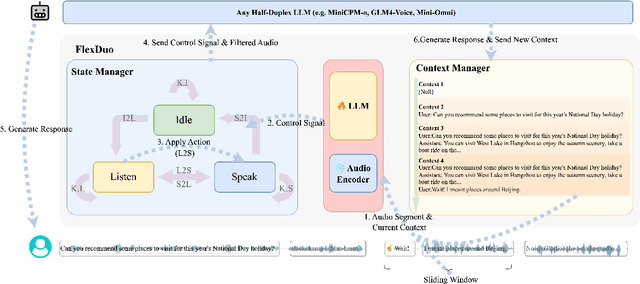

Full-Duplex Speech Dialogue Systems (Full-Duplex SDS) have significantly enhanced the naturalness of human-machine interaction by enabling real-time bidirectional communication. However, existing approaches face challenges such as difficulties in independent module optimization and contextual noise interference due to highly coupled architectural designs and oversimplified binary state modeling. This paper proposes FlexDuo, a flexible full-duplex control module that decouples duplex control from spoken dialogue systems through a plug-and-play architectural design. Furthermore, inspired by human information-filtering mechanisms in conversations, we introduce an explicit Idle state. On one hand, the Idle state filters redundant noise and irrelevant audio to enhance dialogue quality. On the other hand, it establishes a semantic integrity-based buffering mechanism, reducing the risk of mutual interruptions while ensuring accurate response transitions. Experimental results on the Fisher corpus demonstrate that FlexDuo reduces the false interruption rate by 24.9% and improves response accuracy by 7.6% compared to integrated full-duplex dialogue system baselines. It also outperforms voice activity detection (VAD) controlled baseline systems in both Chinese and English dialogue quality. The proposed modular architecture and state-based dialogue model provide a novel technical pathway for building flexible and efficient duplex dialogue systems.
Inductive-Deductive Strategy Reuse for Multi-Turn Instructional Dialogues
Apr 17, 2024Aligning large language models (LLMs) with human expectations requires high-quality instructional dialogues, which can be achieved by raising diverse, in-depth, and insightful instructions that deepen interactions. Existing methods target instructions from real instruction dialogues as a learning goal and fine-tune a user simulator for posing instructions. However, the user simulator struggles to implicitly model complex dialogue flows and pose high-quality instructions. In this paper, we take inspiration from the cognitive abilities inherent in human learning and propose the explicit modeling of complex dialogue flows through instructional strategy reuse. Specifically, we first induce high-level strategies from various real instruction dialogues. These strategies are applied to new dialogue scenarios deductively, where the instructional strategies facilitate high-quality instructions. Experimental results show that our method can generate diverse, in-depth, and insightful instructions for a given dialogue history. The constructed multi-turn instructional dialogues can outperform competitive baselines on the downstream chat model.
Enhancing Role-playing Systems through Aggressive Queries: Evaluation and Improvement
Feb 16, 2024The advent of Large Language Models (LLMs) has propelled dialogue generation into new realms, particularly in the field of role-playing systems (RPSs). While enhanced with ordinary role-relevant training dialogues, existing LLM-based RPSs still struggle to align with roles when handling intricate and trapped queries in boundary scenarios. In this paper, we design the Modular ORchestrated Trap-setting Interaction SystEm (MORTISE) to benchmark and improve the role-playing LLMs' performance. MORTISE can produce highly role-relevant aggressive queries through the collaborative effort of multiple LLM-based modules, and formulate corresponding responses to create an adversarial training dataset via a consistent response generator. We select 190 Chinese and English roles to construct aggressive queries to benchmark existing role-playing LLMs. Through comprehensive evaluation, we find that existing models exhibit a general deficiency in role alignment capabilities. We further select 180 of the roles to collect an adversarial training dataset (named RoleAD) and retain the other 10 roles for testing. Experiments on models improved by RoleAD indicate that our adversarial dataset ameliorates this deficiency, with the improvements demonstrating a degree of generalizability in ordinary scenarios.
DialogBench: Evaluating LLMs as Human-like Dialogue Systems
Nov 03, 2023Large language models (LLMs) have achieved remarkable breakthroughs in new dialogue capabilities, refreshing human's impressions on dialogue systems. The long-standing goal of dialogue systems is to be human-like enough to establish long-term connections with users by satisfying the need for communication, affection and social belonging. Therefore, there has been an urgent need to evaluate LLMs as human-like dialogue systems. In this paper, we propose DialogBench, a dialogue evaluation benchmark that currently contains $12$ dialogue tasks to assess the capabilities of LLMs as human-like dialogue systems should have. Specifically, we prompt GPT-4 to generate evaluation instances for each task. We first design the basic prompt based on widely-used design principles and further mitigate the existing biases to generate higher-quality evaluation instances. Our extensive test over $28$ LLMs (including pre-trained and supervised instruction-tuning) shows that instruction fine-tuning benefits improve the human likeness of LLMs to a certain extent, but there is still much room to improve those capabilities for most LLMs as human-like dialogue systems. In addition, experimental results also indicate that LLMs perform differently in various abilities that human-like dialogue systems should have. We will publicly release DialogBench, along with the associated evaluation code for the broader research community.
Counterfactual Data Augmentation via Perspective Transition for Open-Domain Dialogues
Oct 30, 2022The construction of open-domain dialogue systems requires high-quality dialogue datasets. The dialogue data admits a wide variety of responses for a given dialogue history, especially responses with different semantics. However, collecting high-quality such a dataset in most scenarios is labor-intensive and time-consuming. In this paper, we propose a data augmentation method to automatically augment high-quality responses with different semantics by counterfactual inference. Specifically, given an observed dialogue, our counterfactual generation model first infers semantically different responses by replacing the observed reply perspective with substituted ones. Furthermore, our data selection method filters out detrimental augmented responses. Experimental results show that our data augmentation method can augment high-quality responses with different semantics for a given dialogue history, and can outperform competitive baselines on multiple downstream tasks.
Constructing Emotion Consensus and Utilizing Unpaired Data for Empathetic Dialogue Generation
Sep 18, 2021
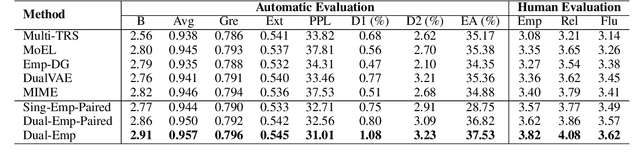
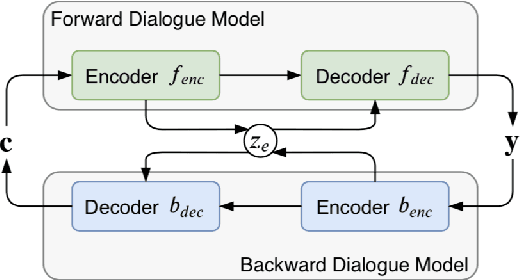
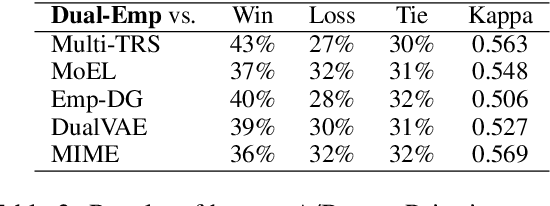
Researches on dialogue empathy aim to endow an agent with the capacity of accurate understanding and proper responding for emotions. Existing models for empathetic dialogue generation focus on the emotion flow in one direction, that is, from the context to response. We argue that conducting an empathetic conversation is a bidirectional process, where empathy occurs when the emotions of two interlocutors could converge on the same point, i.e., reaching an emotion consensus. Besides, we also find that the empathetic dialogue corpus is extremely limited, which further restricts the model performance. To address the above issues, we propose a dual-generative model, Dual-Emp, to simultaneously construct the emotion consensus and utilize some external unpaired data. Specifically, our model integrates a forward dialogue model, a backward dialogue model, and a discrete latent variable representing the emotion consensus into a unified architecture. Then, to alleviate the constraint of paired data, we extract unpaired emotional data from open-domain conversations and employ Dual-Emp to produce pseudo paired empathetic samples, which is more efficient and low-cost than the human annotation. Automatic and human evaluations demonstrate that our method outperforms competitive baselines in producing coherent and empathetic responses.
SE-DAE: Style-Enhanced Denoising Auto-Encoder for Unsupervised Text Style Transfer
Apr 27, 2021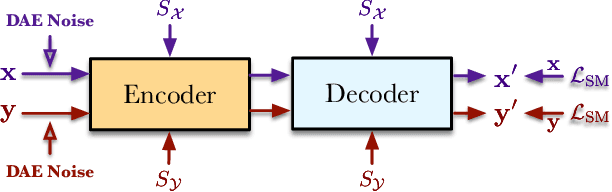
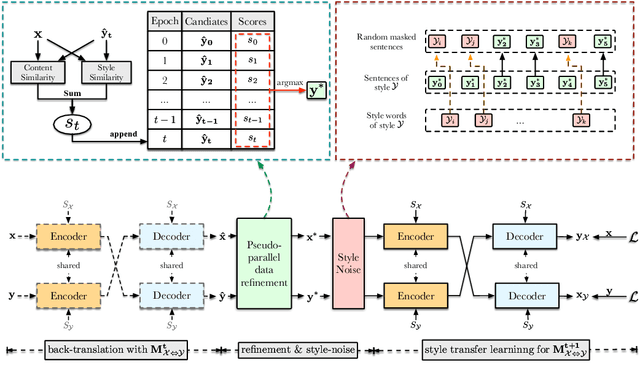
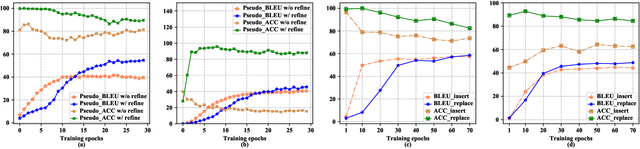
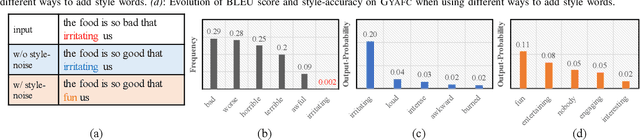
Text style transfer aims to change the style of sentences while preserving the semantic meanings. Due to the lack of parallel data, the Denoising Auto-Encoder (DAE) is widely used in this task to model distributions of different sentence styles. However, because of the conflict between the target of the conventional denoising procedure and the target of style transfer task, the vanilla DAE can not produce satisfying enough results. To improve the transferability of the model, most of the existing works combine DAE with various complicated unsupervised networks, which makes the whole system become over-complex. In this work, we design a novel DAE model named Style-Enhanced DAE (SE-DAE), which is specifically designed for the text style transfer task. Compared with previous complicated style-transfer models, our model do not consist of any complicated unsupervised networks, but only relies on the high-quality pseudo-parallel data generated by a novel data refinement mechanism. Moreover, to alleviate the conflict between the targets of the conventional denoising procedure and the style transfer task, we propose another novel style denoising mechanism, which is more compatible with the target of the style transfer task. We validate the effectiveness of our model on two style benchmark datasets. Both automatic evaluation and human evaluation show that our proposed model is highly competitive compared with previous strong the state of the art (SOTA) approaches and greatly outperforms the vanilla DAE.