 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffCap: Diffusion-based Real-time Human Motion Capture using Sparse IMUs and a Monocular Camera
Aug 08, 2025
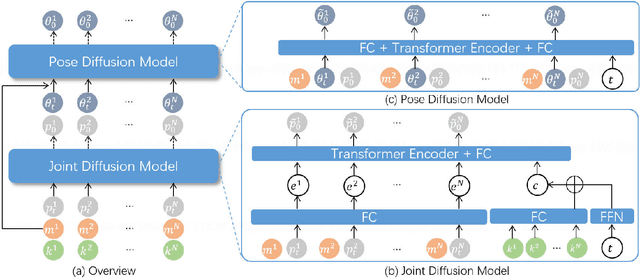
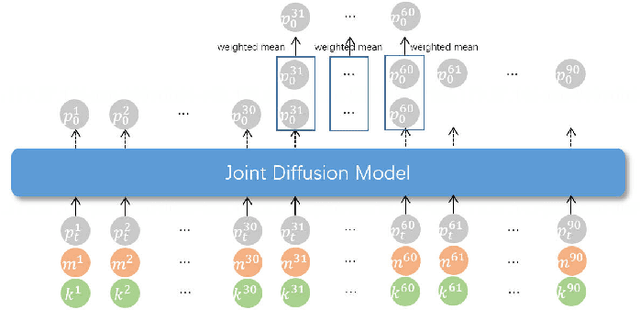

Combining sparse IMUs and a monocular camera is a new promising setting to perform real-time human motion capture. This paper proposes a diffusion-based solution to learn human motion priors and fuse the two modalities of signals together seamlessly in a unified framework. By delicately considering the characteristics of the two signals, the sequential visual information is considered as a whole and transformed into a condition embedding, while the inertial measurement is concatenated with the noisy body pose frame by frame to construct a sequential input for the diffusion model. Firstly, we observe that the visual information may be unavailable in some frames due to occlusions or subjects moving out of the camera view. Thus incorporating the sequential visual features as a whole to get a single feature embedding is robust to the occasional degenerations of visual information in those frames. On the other hand, the IMU measurements are robust to occlusions and always stable when signal transmission has no problem. So incorporating them frame-wisely could better explore the temporal information for the system. Experiments have demonstrated the effectiveness of the system design and its state-of-the-art performance in pose estimation compared with the previous works. Our codes are available for research at https://shaohua-pan.github.io/diffcap-page.
FlexDuo: A Pluggable System for Enabling Full-Duplex Capabilities in Speech Dialogue Systems
Feb 19, 2025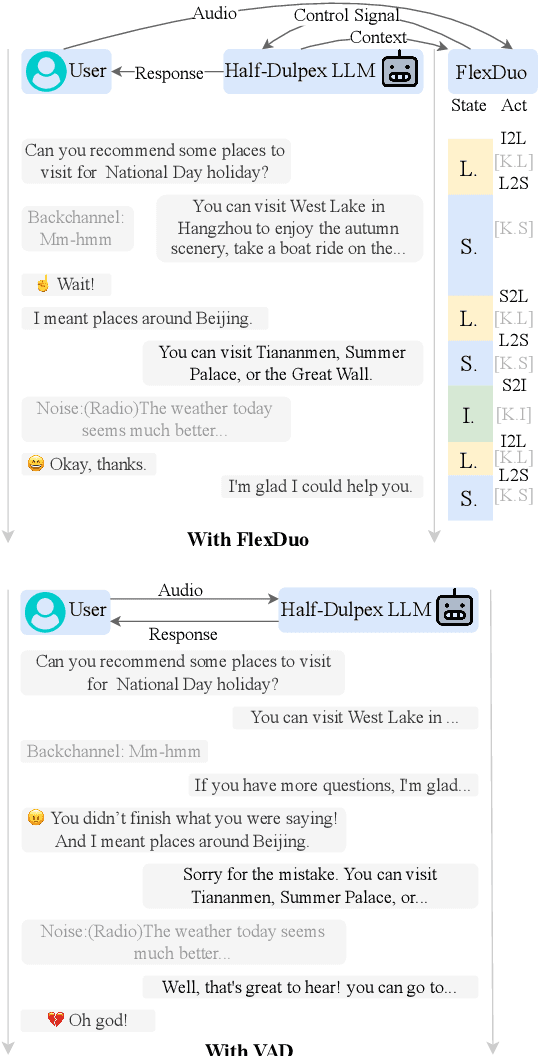

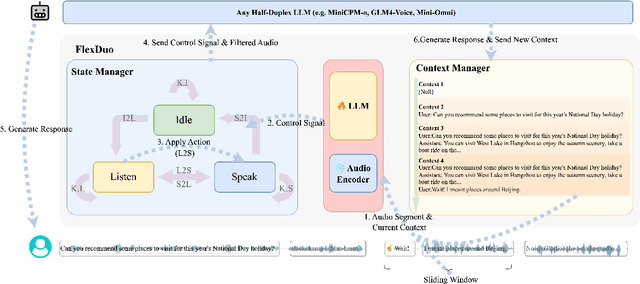

Full-Duplex Speech Dialogue Systems (Full-Duplex SDS) have significantly enhanced the naturalness of human-machine interaction by enabling real-time bidirectional communication. However, existing approaches face challenges such as difficulties in independent module optimization and contextual noise interference due to highly coupled architectural designs and oversimplified binary state modeling. This paper proposes FlexDuo, a flexible full-duplex control module that decouples duplex control from spoken dialogue systems through a plug-and-play architectural design. Furthermore, inspired by human information-filtering mechanisms in conversations, we introduce an explicit Idle state. On one hand, the Idle state filters redundant noise and irrelevant audio to enhance dialogue quality. On the other hand, it establishes a semantic integrity-based buffering mechanism, reducing the risk of mutual interruptions while ensuring accurate response transitions. Experimental results on the Fisher corpus demonstrate that FlexDuo reduces the false interruption rate by 24.9% and improves response accuracy by 7.6% compared to integrated full-duplex dialogue system baselines. It also outperforms voice activity detection (VAD) controlled baseline systems in both Chinese and English dialogue quality. The proposed modular architecture and state-based dialogue model provide a novel technical pathway for building flexible and efficient duplex dialogue systems.
Temporal-Aware Refinement for Video-based Human Pose and Shape Recovery
Nov 16, 2023



Though significant progress in human pose and shape recovery from monocular RGB images has been made in recent years, obtaining 3D human motion with high accuracy and temporal consistency from videos remains challenging. Existing video-based methods tend to reconstruct human motion from global image features, which lack detailed representation capability and limit the reconstruction accuracy. In this paper, we propose a Temporal-Aware Refining Network (TAR), to synchronously explore temporal-aware global and local image features for accurate pose and shape recovery. First, a global transformer encoder is introduced to obtain temporal global features from static feature sequences. Second, a bidirectional ConvGRU network takes the sequence of high-resolution feature maps as input, and outputs temporal local feature maps that maintain high resolution and capture the local motion of the human body. Finally, a recurrent refinement module iteratively updates estimated SMPL parameters by leveraging both global and local temporal information to achieve accurate and smooth results. Extensive experiments demonstrate that our TAR obtains more accurate results than previous state-of-the-art methods on popular benchmarks, i.e., 3DPW, MPI-INF-3DHP, and Human3.6M.