 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenAI GPT-5 System Card
Dec 19, 2025This is the system card published alongside the OpenAI GPT-5 launch, August 2025. GPT-5 is a unified system with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say 'think hard about this' in the prompt). The router is continuously trained on real signals, including when users switch models, preference rates for responses, and measured correctness, improving over time. Once usage limits are reached, a mini version of each model handles remaining queries. This system card focuses primarily on gpt-5-thinking and gpt-5-main, while evaluations for other models are available in the appendix. The GPT-5 system not only outperforms previous models on benchmarks and answers questions more quickly, but -- more importantly -- is more useful for real-world queries. We've made significant advances in reducing hallucinations, improving instruction following, and minimizing sycophancy, and have leveled up GPT-5's performance in three of ChatGPT's most common uses: writing, coding, and health. All of the GPT-5 models additionally feature safe-completions, our latest approach to safety training to prevent disallowed content. Similarly to ChatGPT agent, we have decided to treat gpt-5-thinking as High capability in the Biological and Chemical domain under our Preparedness Framework, activating the associated safeguards. While we do not have definitive evidence that this model could meaningfully help a novice to create severe biological harm -- our defined threshold for High capability -- we have chosen to take a precautionary approach.
Reasoning in Diffusion Large Language Models is Concentrated in Dynamic Confusion Zones
Nov 19, 2025



Diffusion Large Language Models (dLLMs) are rapidly emerging alongside autoregressive models as a powerful paradigm for complex reasoning, with reinforcement learning increasingly used for downstream alignment. Existing trajectory-based RL methods uniformly allocate policy gradients across denoising steps, implicitly treating all steps as equally important. We challenge this assumption by analyzing trajectories with several step-level metrics: entropy-based uncertainty, Confidence-Margin (CM) uncertainty, and Rate of Entropy Change (RoEC). These reveal structured "zones of confusion": transient spikes in uncertainty and instability that strongly predict final success or failure, while most steps remain stable. We propose Adaptive Trajectory Policy Optimization (ATPO), a lightweight step-selection strategy that dynamically reallocates gradient updates to these high-leverage steps without changing the RL objective, rewards, or compute budget. Using a hybrid RoEC+CM rule, ATPO delivers substantial gains in reasoning accuracy and training stability across benchmarks, showing that exploiting trajectory dynamics is key to advancing dLLM RL.
Kling-Avatar: Grounding Multimodal Instructions for Cascaded Long-Duration Avatar Animation Synthesis
Sep 11, 2025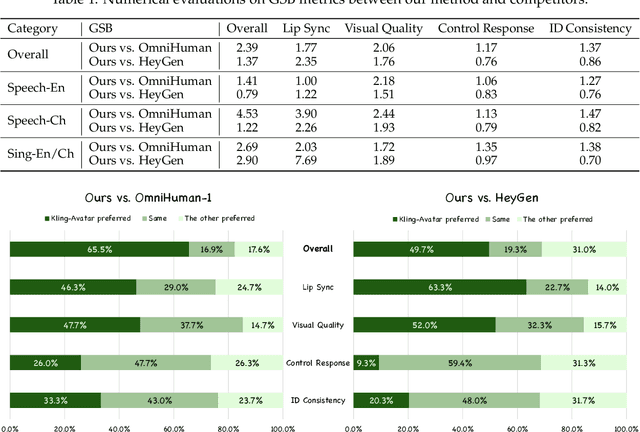
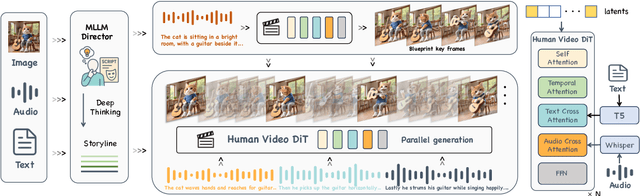


Recent advances in audio-driven avatar video generation have significantly enhanced audio-visual realism. However, existing methods treat instruction conditioning merely as low-level tracking driven by acoustic or visual cues, without modeling the communicative purpose conveyed by the instructions. This limitation compromises their narrative coherence and character expressiveness. To bridge this gap, we introduce Kling-Avatar, a novel cascaded framework that unifies multimodal instruction understanding with photorealistic portrait generation. Our approach adopts a two-stage pipeline. In the first stage, we design a multimodal large language model (MLLM) director that produces a blueprint video conditioned on diverse instruction signals, thereby governing high-level semantics such as character motion and emotions. In the second stage, guided by blueprint keyframes, we generate multiple sub-clips in parallel using a first-last frame strategy. This global-to-local framework preserves fine-grained details while faithfully encoding the high-level intent behind multimodal instructions. Our parallel architecture also enables fast and stable generation of long-duration videos, making it suitable for real-world applications such as digital human livestreaming and vlogging. To comprehensively evaluate our method, we construct a benchmark of 375 curated samples covering diverse instructions and challenging scenarios. Extensive experiments demonstrate that Kling-Avatar is capable of generating vivid, fluent, long-duration videos at up to 1080p and 48 fps, achieving superior performance in lip synchronization accuracy, emotion and dynamic expressiveness, instruction controllability, identity preservation, and cross-domain generalization. These results establish Kling-Avatar as a new benchmark for semantically grounded, high-fidelity audio-driven avatar synthesis.
Decoding RobKiNet: Insights into Efficient Training of Robotic Kinematics Informed Neural Network
Sep 09, 2025In robots task and motion planning (TAMP), it is crucial to sample within the robot's configuration space to meet task-level global constraints and enhance the efficiency of subsequent motion planning. Due to the complexity of joint configuration sampling under multi-level constraints, traditional methods often lack efficiency. This paper introduces the principle of RobKiNet, a kinematics-informed neural network, for end-to-end sampling within the Continuous Feasible Set (CFS) under multiple constraints in configuration space, establishing its Optimization Expectation Model. Comparisons with traditional sampling and learning-based approaches reveal that RobKiNet's kinematic knowledge infusion enhances training efficiency by ensuring stable and accurate gradient optimization.Visualizations and quantitative analyses in a 2-DOF space validate its theoretical efficiency, while its application on a 9-DOF autonomous mobile manipulator robot(AMMR) demonstrates superior whole-body and decoupled control, excelling in battery disassembly tasks. RobKiNet outperforms deep reinforcement learning with a training speed 74.29 times faster and a sampling accuracy of up to 99.25%, achieving a 97.33% task completion rate in real-world scenarios.
MIDAS: Multimodal Interactive Digital-humAn Synthesis via Real-time Autoregressive Video Generation
Aug 28, 2025Recently, interactive digital human video generation has attracted widespread attention and achieved remarkable progress. However, building such a practical system that can interact with diverse input signals in real time remains challenging to existing methods, which often struggle with heavy computational cost and limited controllability. In this work, we introduce an autoregressive video generation framework that enables interactive multimodal control and low-latency extrapolation in a streaming manner. With minimal modifications to a standard large language model (LLM), our framework accepts multimodal condition encodings including audio, pose, and text, and outputs spatially and semantically coherent representations to guide the denoising process of a diffusion head. To support this, we construct a large-scale dialogue dataset of approximately 20,000 hours from multiple sources, providing rich conversational scenarios for training. We further introduce a deep compression autoencoder with up to 64$\times$ reduction ratio, which effectively alleviates the long-horizon inference burden of the autoregressive model. Extensive experiments on duplex conversation, multilingual human synthesis, and interactive world model highlight the advantages of our approach in low latency, high efficiency, and fine-grained multimodal controllability.
Performance Analysis of OAMP Detection for ODDM Modulation in Satellite Communications
Jun 24, 2025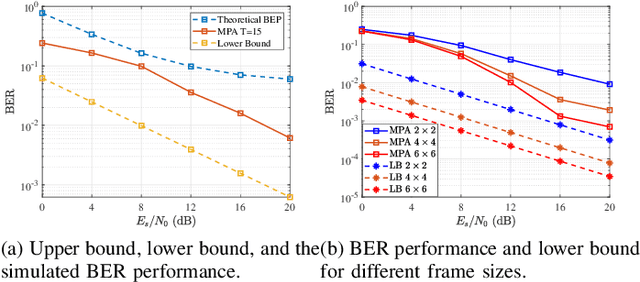
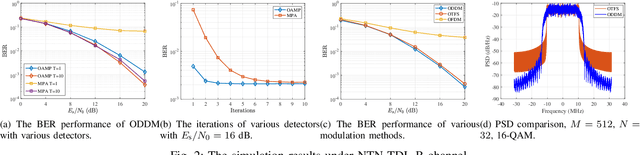
Towards future 6G wireless networks, low earth orbit (LEO) satellites have been widely considered as a promising component to enhance the terrestrial communications. To ensure the link reliability of high-mobility satellite communication scenarios, the emerging orthogonal delay-Doppler division multiplexing (ODDM) modulation has attracted significant research attention. In this paper, we study the diversity gain achieved by ODDM modulation along with the mathematical analysis and numerical simulations. Additionally, we propose an orthogonal approximate message passing (OAMP) algorithm based detector to harvest the diversity gain promised by ODDM modulation. By operating the linear and non-linear estimator iteratively, the orthogonal approximate message passing (OAMP) detector can utilize the sparsity of the effective delay-Doppler (DD) domain channel and extract the full diversity. Simulation results reveal the relationship between diversity gain and system parameters, and demonstrate that our proposed detector can achieve better performance than the conventional message passing methods with significantly reduced complexity.
Towards Universal Offline Black-Box Optimization via Learning Language Model Embeddings
Jun 08, 2025The pursuit of universal black-box optimization (BBO) algorithms is a longstanding goal. However, unlike domains such as language or vision, where scaling structured data has driven generalization, progress in offline BBO remains hindered by the lack of unified representations for heterogeneous numerical spaces. Thus, existing offline BBO approaches are constrained to single-task and fixed-dimensional settings, failing to achieve cross-domain universal optimization. Recent advances in language models (LMs) offer a promising path forward: their embeddings capture latent relationships in a unifying way, enabling universal optimization across different data types possible. In this paper, we discuss multiple potential approaches, including an end-to-end learning framework in the form of next-token prediction, as well as prioritizing the learning of latent spaces with strong representational capabilities. To validate the effectiveness of these methods, we collect offline BBO tasks and data from open-source academic works for training. Experiments demonstrate the universality and effectiveness of our proposed methods. Our findings suggest that unifying language model priors and learning string embedding space can overcome traditional barriers in universal BBO, paving the way for general-purpose BBO algorithms. The code is provided at https://github.com/lamda-bbo/universal-offline-bbo.
LLM-OptiRA: LLM-Driven Optimization of Resource Allocation for Non-Convex Problems in Wireless Communications
May 04, 2025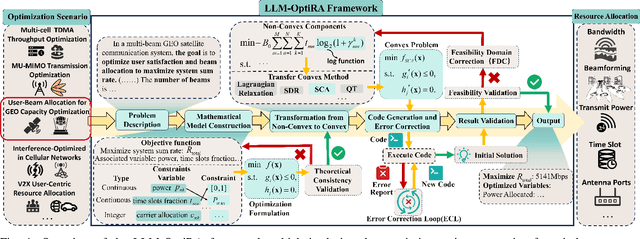
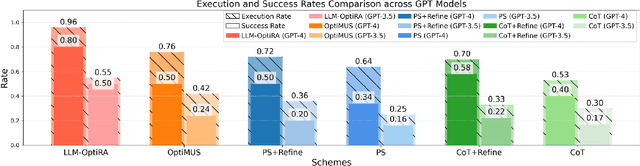
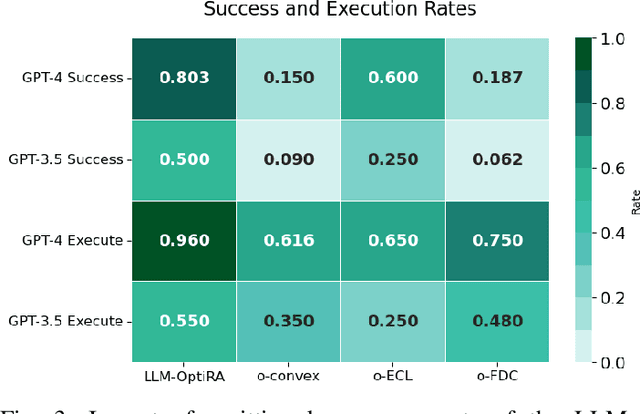
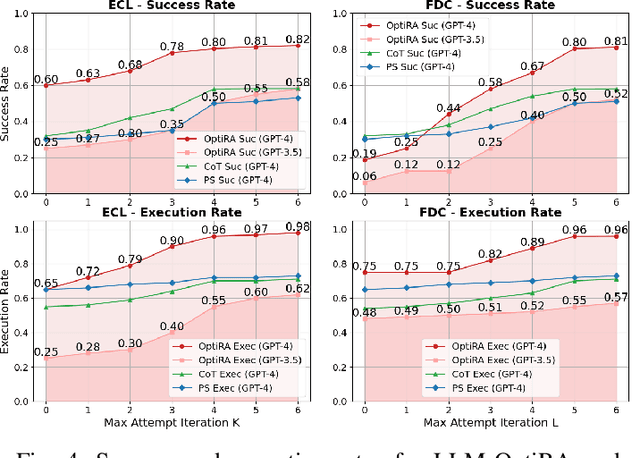
Solving non-convex resource allocation problems poses significant challenges in wireless communication systems, often beyond the capability of traditional optimization techniques. To address this issue, we propose LLM-OptiRA, the first framework that leverages large language models (LLMs) to automatically detect and transform non-convex components into solvable forms, enabling fully automated resolution of non-convex resource allocation problems in wireless communication systems. LLM-OptiRA not only simplifies problem-solving by reducing reliance on expert knowledge, but also integrates error correction and feasibility validation mechanisms to ensure robustness. Experimental results show that LLM-OptiRA achieves an execution rate of 96% and a success rate of 80% on GPT-4, significantly outperforming baseline approaches in complex optimization tasks across diverse scenarios.
An Intelligent and Privacy-Preserving Digital Twin Model for Aging-in-Place
Apr 04, 2025The population of older adults is steadily increasing, with a strong preference for aging-in-place rather than moving to care facilities. Consequently, supporting this growing demographic has become a significant global challenge. However, facilitating successful aging-in-place is challenging, requiring consideration of multiple factors such as data privacy, health status monitoring, and living environments to improve health outcomes. In this paper, we propose an unobtrusive sensor system designed for installation in older adults' homes. Using data from the sensors, our system constructs a digital twin, a virtual representation of events and activities that occurred in the home. The system uses neural network models and decision rules to capture residents' activities and living environments. This digital twin enables continuous health monitoring by providing actionable insights into residents' well-being. Our system is designed to be low-cost and privacy-preserving, with the aim of providing green and safe monitoring for the health of older adults. We have successfully deployed our system in two homes over a time period of two months, and our findings demonstrate the feasibility and effectiveness of digital twin technology in supporting independent living for older adults. This study highlights that our system could revolutionize elder care by enabling personalized interventions, such as lifestyle adjustments, medical treatments, or modifications to the residential environment, to enhance health outcomes.
ExGes: Expressive Human Motion Retrieval and Modulation for Audio-Driven Gesture Synthesis
Mar 09, 2025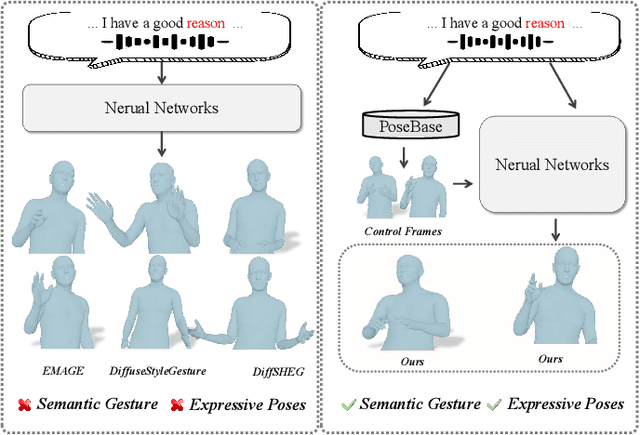
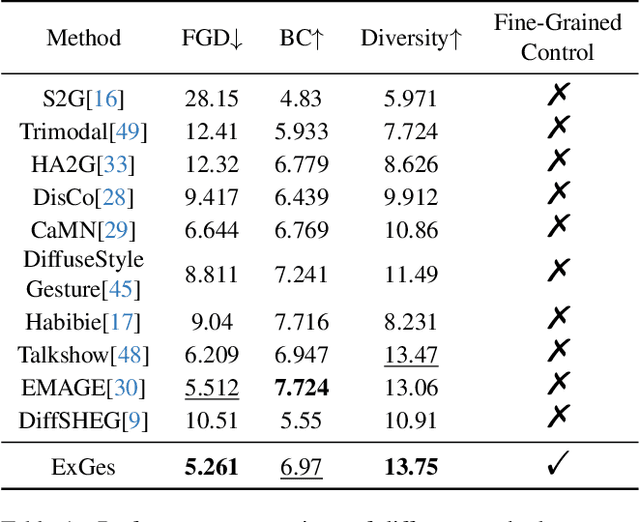
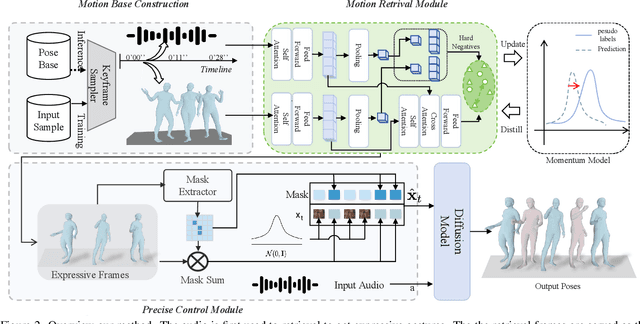
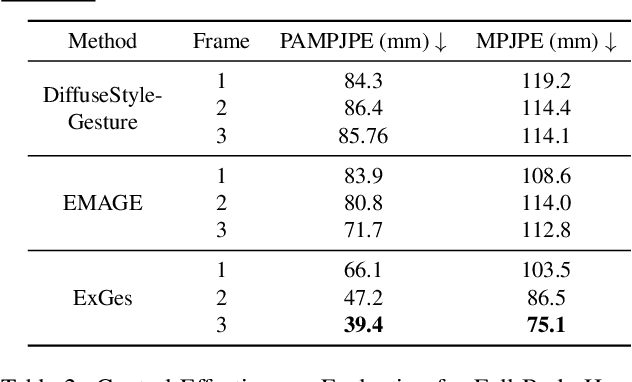
Audio-driven human gesture synthesis is a crucial task with broad applications in virtual avatars, human-computer interaction, and creative content generation. Despite notable progress, existing methods often produce gestures that are coarse, lack expressiveness, and fail to fully align with audio semantics. To address these challenges, we propose ExGes, a novel retrieval-enhanced diffusion framework with three key designs: (1) a Motion Base Construction, which builds a gesture library using training dataset; (2) a Motion Retrieval Module, employing constrative learning and momentum distillation for fine-grained reference poses retreiving; and (3) a Precision Control Module, integrating partial masking and stochastic masking to enable flexible and fine-grained control. Experimental evaluations on BEAT2 demonstrate that ExGes reduces Fr\'echet Gesture Distance by 6.2\% and improves motion diversity by 5.3\% over EMAGE, with user studies revealing a 71.3\% preference for its naturalness and semantic relevance. Code will be released upon acceptance.