 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDINO Eats CLIP: Adapting Beyond Knowns for Open-set 3D Object Retrieval
Apr 21, 2026Vision foundation models have shown great promise for open-set 3D object retrieval (3DOR) through efficient adaptation to multi-view images. Leveraging semantically aligned latent space, previous work typically adapts the CLIP encoder to build view-based 3D descriptors. Despite CLIP's strong generalization ability, its lack of fine-grainedness prompted us to explore the potential of a more recent self-supervised encoder-DINO. To address this, we propose DINO Eats CLIP (DEC), a novel framework for dynamic multi-view integration that is regularized by synthesizing data for unseen classes. We first find that simply mean-pooling over view features from a frozen DINO backbone gives decent performance. Yet, further adaptation causes severe overfitting on average view patterns of known classes. To combat it, we then design a module named Chunking and Adapting Module (CAM). It segments multi-view images into chunks and dynamically integrates local view relations, yielding more robust features than the standard pooling strategy. Finally, we propose Virtual Feature Synthesis (VFS) module to mitigate bias towards known categories explicitly. Under the hood, VFS leverages CLIP's broad, pre-aligned vision-language space to synthesize virtual features for unseen classes. By exposing DEC to these virtual features, we greatly enhance its open-set discrimination capacity. Extensive experiments on standard open-set 3DOR benchmarks demonstrate its superior efficacy.
FF-PNet: A Pyramid Network Based on Feature and Field for Brain Image Registration
May 08, 2025



In recent years, deformable medical image registration techniques have made significant progress. However, existing models still lack efficiency in parallel extraction of coarse and fine-grained features. To address this, we construct a new pyramid registration network based on feature and deformation field (FF-PNet). For coarse-grained feature extraction, we design a Residual Feature Fusion Module (RFFM), for fine-grained image deformation, we propose a Residual Deformation Field Fusion Module (RDFFM). Through the parallel operation of these two modules, the model can effectively handle complex image deformations. It is worth emphasizing that the encoding stage of FF-PNet only employs traditional convolutional neural networks without any attention mechanisms or multilayer perceptrons, yet it still achieves remarkable improvements in registration accuracy, fully demonstrating the superior feature decoding capabilities of RFFM and RDFFM. We conducted extensive experiments on the LPBA and OASIS datasets. The results show our network consistently outperforms popular methods in metrics like the Dice Similarity Coefficient.
Tetrahedron-Net for Medical Image Registration
May 07, 2025Medical image registration plays a vital role in medical image processing. Extracting expressive representations for medical images is crucial for improving the registration quality. One common practice for this end is constructing a convolutional backbone to enable interactions with skip connections among feature extraction layers. The de facto structure, U-Net-like networks, has attempted to design skip connections such as nested or full-scale ones to connect one single encoder and one single decoder to improve its representation capacity. Despite being effective, it still does not fully explore interactions with a single encoder and decoder architectures. In this paper, we embrace this observation and introduce a simple yet effective alternative strategy to enhance the representations for registrations by appending one additional decoder. The new decoder is designed to interact with both the original encoder and decoder. In this way, it not only reuses feature presentation from corresponding layers in the encoder but also interacts with the original decoder to corporately give more accurate registration results. The new architecture is concise yet generalized, with only one encoder and two decoders forming a ``Tetrahedron'' structure, thereby dubbed Tetrahedron-Net. Three instantiations of Tetrahedron-Net are further constructed regarding the different structures of the appended decoder. Our extensive experiments prove that superior performance can be obtained on several representative benchmarks of medical image registration. Finally, such a ``Tetrahedron'' design can also be easily integrated into popular U-Net-like architectures including VoxelMorph, ViT-V-Net, and TransMorph, leading to consistent performance gains.
TeDA: Boosting Vision-Lanuage Models for Zero-Shot 3D Object Retrieval via Testing-time Distribution Alignment
May 05, 2025Learning discriminative 3D representations that generalize well to unknown testing categories is an emerging requirement for many real-world 3D applications. Existing well-established methods often struggle to attain this goal due to insufficient 3D training data from broader concepts. Meanwhile, pre-trained large vision-language models (e.g., CLIP) have shown remarkable zero-shot generalization capabilities. Yet, they are limited in extracting suitable 3D representations due to substantial gaps between their 2D training and 3D testing distributions. To address these challenges, we propose Testing-time Distribution Alignment (TeDA), a novel framework that adapts a pretrained 2D vision-language model CLIP for unknown 3D object retrieval at test time. To our knowledge, it is the first work that studies the test-time adaptation of a vision-language model for 3D feature learning. TeDA projects 3D objects into multi-view images, extracts features using CLIP, and refines 3D query embeddings with an iterative optimization strategy by confident query-target sample pairs in a self-boosting manner. Additionally, TeDA integrates textual descriptions generated by a multimodal language model (InternVL) to enhance 3D object understanding, leveraging CLIP's aligned feature space to fuse visual and textual cues. Extensive experiments on four open-set 3D object retrieval benchmarks demonstrate that TeDA greatly outperforms state-of-the-art methods, even those requiring extensive training. We also experimented with depth maps on Objaverse-LVIS, further validating its effectiveness. Code is available at https://github.com/wangzhichuan123/TeDA.
CLIP-SCGI: Synthesized Caption-Guided Inversion for Person Re-Identification
Oct 12, 2024Person re-identification (ReID) has recently benefited from large pretrained vision-language models such as Contrastive Language-Image Pre-Training (CLIP). However, the absence of concrete descriptions necessitates the use of implicit text embeddings, which demand complicated and inefficient training strategies. To address this issue, we first propose one straightforward solution by leveraging existing image captioning models to generate pseudo captions for person images, and thereby boost person re-identification with large vision language models. Using models like the Large Language and Vision Assistant (LLAVA), we generate high-quality captions based on fixed templates that capture key semantic attributes such as gender, clothing, and age. By augmenting ReID training sets from uni-modality (image) to bi-modality (image and text), we introduce CLIP-SCGI, a simple yet effective framework that leverages synthesized captions to guide the learning of discriminative and robust representations. Built on CLIP, CLIP-SCGI fuses image and text embeddings through two modules to enhance the training process. To address quality issues in generated captions, we introduce a caption-guided inversion module that captures semantic attributes from images by converting relevant visual information into pseudo-word tokens based on the descriptions. This approach helps the model better capture key information and focus on relevant regions. The extracted features are then utilized in a cross-modal fusion module, guiding the model to focus on regions semantically consistent with the caption, thereby facilitating the optimization of the visual encoder to extract discriminative and robust representations. Extensive experiments on four popular ReID benchmarks demonstrate that CLIP-SCGI outperforms the state-of-the-art by a significant margin.
Attention-Guided Perturbation for Unsupervised Image Anomaly Detection
Aug 14, 2024Reconstruction-based methods have significantly advanced modern unsupervised anomaly detection. However, the strong capacity of neural networks often violates the underlying assumptions by reconstructing abnormal samples well. To alleviate this issue, we present a simple yet effective reconstruction framework named Attention-Guided Pertuation Network (AGPNet), which learns to add perturbation noise with an attention mask, for accurate unsupervised anomaly detection. Specifically, it consists of two branches, \ie, a plain reconstruction branch and an auxiliary attention-based perturbation branch. The reconstruction branch is simply a plain reconstruction network that learns to reconstruct normal samples, while the auxiliary branch aims to produce attention masks to guide the noise perturbation process for normal samples from easy to hard. By doing so, we are expecting to synthesize hard yet more informative anomalies for training, which enable the reconstruction branch to learn important inherent normal patterns both comprehensively and efficiently. Extensive experiments are conducted on three popular benchmarks covering MVTec-AD, VisA, and MVTec-3D, and show that our framework obtains leading anomaly detection performance under various setups including few-shot, one-class, and multi-class setups.
SimpleFusion: A Simple Fusion Framework for Infrared and Visible Images
Jun 27, 2024Integrating visible and infrared images into one high-quality image, also known as visible and infrared image fusion, is a challenging yet critical task for many downstream vision tasks. Most existing works utilize pretrained deep neural networks or design sophisticated frameworks with strong priors for this task, which may be unsuitable or lack flexibility. This paper presents SimpleFusion, a simple yet effective framework for visible and infrared image fusion. Our framework follows the decompose-and-fusion paradigm, where the visible and the infrared images are decomposed into reflectance and illumination components via Retinex theory and followed by the fusion of these corresponding elements. The whole framework is designed with two plain convolutional neural networks without downsampling, which can perform image decomposition and fusion efficiently. Moreover, we introduce decomposition loss and a detail-to-semantic loss to preserve the complementary information between the two modalities for fusion. We conduct extensive experiments on the challenging benchmarks, verifying the superiority of our method over previous state-of-the-arts. Code is available at \href{https://github.com/hxwxss/SimpleFusion-A-Simple-Fusion-Framework-for-Infrared-and-Visible-Images}{https://github.com/hxwxss/SimpleFusion-A-Simple-Fusion-Framework-for-Infrared-and-Visible-Images}
GL-GAN: Adaptive Global and Local Bilevel Optimization model of Image Generation
Aug 06, 2020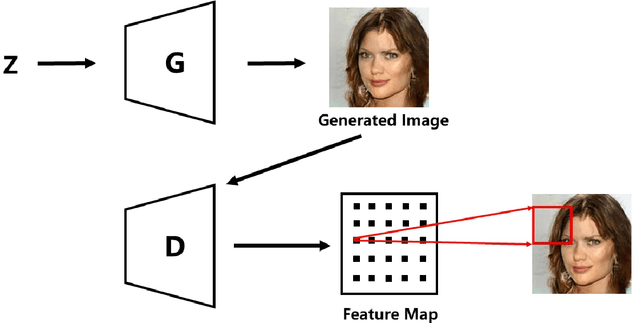


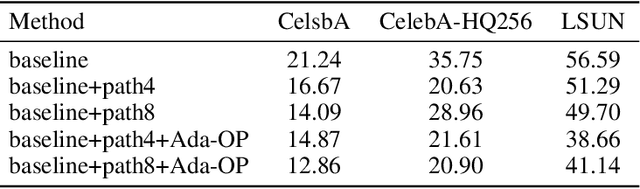
Although Generative Adversarial Networks have shown remarkable performance in image generation, there are some challenges in image realism and convergence speed. The results of some models display the imbalances of quality within a generated image, in which some defective parts appear compared with other regions. Different from general single global optimization methods, we introduce an adaptive global and local bilevel optimization model(GL-GAN). The model achieves the generation of high-resolution images in a complementary and promoting way, where global optimization is to optimize the whole images and local is only to optimize the low-quality areas. With a simple network structure, GL-GAN is allowed to effectively avoid the nature of imbalance by local bilevel optimization, which is accomplished by first locating low-quality areas and then optimizing them. Moreover, by using feature map cues from discriminator output, we propose the adaptive local and global optimization method(Ada-OP) for specific implementation and find that it boosts the convergence speed. Compared with the current GAN methods, our model has shown impressive performance on CelebA, CelebA-HQ and LSUN datasets.
ClsGAN: Selective Attribute Editing Based On Classification Adversarial Network
Oct 25, 2019

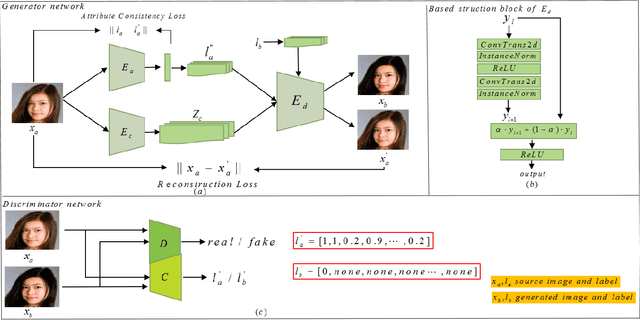

Attribution editing has shown remarking progress by the incorporating of encoder-decoder structure and generative adversarial network. However, there are still some challenges in the quality and attribute transformation of the generated images. Encoder-decoder structure leads to blurring of images and the skip-connection of encoder-decoder structure weakens the attribute transfer ability. To address these limitations, we propose a classification adversarial model(Cls-GAN) that can balance between attribute transfer and generated photo-realistic images. Considering that the transfer images are affected by the original attribute using skip-connection, we introduce upper convolution residual network(Tr-resnet) to selectively extract information from the source image and target label. Specially, we apply to the attribute classification adversarial network to learn about the defects of attribute transfer images so as to guide the generator. Finally, to meet the requirement of multimodal and improve reconstruction effect, we build two encoders including the content and style network, and select a attribute label approximation between source label and the output of style network. Experiments that operates at the dataset of CelebA show that images are superiority against the existing state-of-the-art models in image quality and transfer accuracy. Experiments on wikiart and seasonal datasets demonstrate that ClsGAN can effectively implement styel transfer.
Data-driven Approach for Quality Evaluation on Knowledge Sharing Platform
Mar 01, 2019

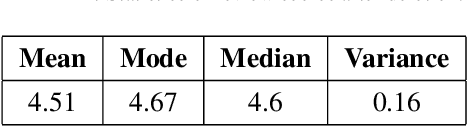

In recent years, voice knowledge sharing and question answering (Q&A) platforms have attracted much attention, which greatly facilitate the knowledge acquisition for people. However, little research has evaluated on the quality evaluation on voice knowledge sharing. This paper presents a data-driven approach to automatically evaluate the quality of a specific Q&A platform (Zhihu Live). Extensive experiments demonstrate the effectiveness of the proposed method. Furthermore, we introduce a dataset of Zhihu Live as an open resource for researchers in related areas. This dataset will facilitate the development of new methods on knowledge sharing services quality evaluation.