 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph Topology Information Enhanced Heterogeneous Graph Representation Learning
Apr 07, 2026Real-world heterogeneous graphs are inherently noisy and usually not in the optimal graph structures for downstream tasks, which often adversely affects the performance of GRL models in downstream tasks. Although Graph Structure Learning (GSL) methods have been proposed to learn graph structures and downstream tasks simultaneously, existing methods are predominantly designed for homogeneous graphs, while GSL for heterogeneous graphs remains largely unexplored. Two challenges arise in this context. Firstly, the quality of the input graph structure has a more profound impact on GNN-based heterogeneous GRL models compared to their homogeneous counterparts. Secondly, most existing homogenous GRL models encounter memory consumption issues when applied directly to heterogeneous graphs. In this paper, we propose a novel Graph Topology learning Enhanced Heterogeneous Graph Representation Learning framework (ToGRL).ToGRL learns high-quality graph structures and representations for downstream tasks by incorporating task-relevant latent topology information. Specifically, a novel GSL module is first proposed to extract downstream task-related topology information from a raw graph structure and project it into topology embeddings. These embeddings are utilized to construct a new graph with smooth graph signals. This two-stage approach to GSL separates the optimization of the adjacency matrix from node representation learning to reduce memory consumption. Following this, a representation learning module takes the new graph as input to learn embeddings for downstream tasks. ToGRL also leverages prompt tuning to better utilize the knowledge embedded in learned representations, thus enhancing adaptability to downstream tasks. Extensive experiments on five real-world datasets show that our ToGRL outperforms state-of-the-art methods by a large margin.
Semantic Item Graph Enhancement for Multimodal Recommendation
Aug 08, 2025Multimodal recommendation systems have attracted increasing attention for their improved performance by leveraging items' multimodal information. Prior methods often build modality-specific item-item semantic graphs from raw modality features and use them as supplementary structures alongside the user-item interaction graph to enhance user preference learning. However, these semantic graphs suffer from semantic deficiencies, including (1) insufficient modeling of collaborative signals among items and (2) structural distortions introduced by noise in raw modality features, ultimately compromising performance. To address these issues, we first extract collaborative signals from the interaction graph and infuse them into each modality-specific item semantic graph to enhance semantic modeling. Then, we design a modulus-based personalized embedding perturbation mechanism that injects perturbations with modulus-guided personalized intensity into embeddings to generate contrastive views. This enables the model to learn noise-robust representations through contrastive learning, thereby reducing the effect of structural noise in semantic graphs. Besides, we propose a dual representation alignment mechanism that first aligns multiple semantic representations via a designed Anchor-based InfoNCE loss using behavior representations as anchors, and then aligns behavior representations with the fused semantics by standard InfoNCE, to ensure representation consistency. Extensive experiments on four benchmark datasets validate the effectiveness of our framework.
SoftCoT++: Test-Time Scaling with Soft Chain-of-Thought Reasoning
May 16, 2025



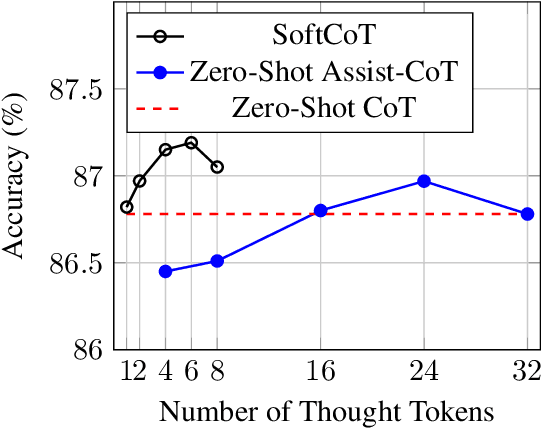
Test-Time Scaling (TTS) refers to approaches that improve reasoning performance by allocating extra computation during inference, without altering the model's parameters. While existing TTS methods operate in a discrete token space by generating more intermediate steps, recent studies in Coconut and SoftCoT have demonstrated that thinking in the continuous latent space can further enhance the reasoning performance. Such latent thoughts encode informative thinking without the information loss associated with autoregressive token generation, sparking increased interest in continuous-space reasoning. Unlike discrete decoding, where repeated sampling enables exploring diverse reasoning paths, latent representations in continuous space are fixed for a given input, which limits diverse exploration, as all decoded paths originate from the same latent thought. To overcome this limitation, we introduce SoftCoT++ to extend SoftCoT to the Test-Time Scaling paradigm by enabling diverse exploration of thinking paths. Specifically, we perturb latent thoughts via multiple specialized initial tokens and apply contrastive learning to promote diversity among soft thought representations. Experiments across five reasoning benchmarks and two distinct LLM architectures demonstrate that SoftCoT++ significantly boosts SoftCoT and also outperforms SoftCoT with self-consistency scaling. Moreover, it shows strong compatibility with conventional scaling techniques such as self-consistency. Source code is available at https://github.com/xuyige/SoftCoT.
An Intelligent and Privacy-Preserving Digital Twin Model for Aging-in-Place
Apr 04, 2025The population of older adults is steadily increasing, with a strong preference for aging-in-place rather than moving to care facilities. Consequently, supporting this growing demographic has become a significant global challenge. However, facilitating successful aging-in-place is challenging, requiring consideration of multiple factors such as data privacy, health status monitoring, and living environments to improve health outcomes. In this paper, we propose an unobtrusive sensor system designed for installation in older adults' homes. Using data from the sensors, our system constructs a digital twin, a virtual representation of events and activities that occurred in the home. The system uses neural network models and decision rules to capture residents' activities and living environments. This digital twin enables continuous health monitoring by providing actionable insights into residents' well-being. Our system is designed to be low-cost and privacy-preserving, with the aim of providing green and safe monitoring for the health of older adults. We have successfully deployed our system in two homes over a time period of two months, and our findings demonstrate the feasibility and effectiveness of digital twin technology in supporting independent living for older adults. This study highlights that our system could revolutionize elder care by enabling personalized interventions, such as lifestyle adjustments, medical treatments, or modifications to the residential environment, to enhance health outcomes.
SoftCoT: Soft Chain-of-Thought for Efficient Reasoning with LLMs
Feb 17, 2025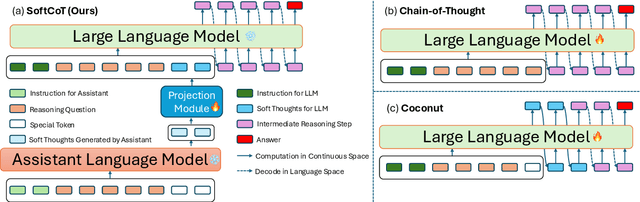


Chain-of-Thought (CoT) reasoning enables Large Language Models (LLMs) to solve complex reasoning tasks by generating intermediate reasoning steps. However, most existing approaches focus on hard token decoding, which constrains reasoning within the discrete vocabulary space and may not always be optimal. While recent efforts explore continuous-space reasoning, they often suffer from catastrophic forgetting, limiting their applicability to state-of-the-art LLMs that already perform well in zero-shot settings with a proper instruction. To address this challenge, we propose a novel approach for continuous-space reasoning that does not require modifying the underlying LLM. Specifically, we employ a lightweight assistant model to generate instance-specific soft thought tokens speculatively as the initial chain of thoughts, which are then mapped into the LLM's representation space via a projection module. Experimental results on five reasoning benchmarks demonstrate that our method enhances LLM reasoning performance through supervised, parameter-efficient fine-tuning.
RevMUX: Data Multiplexing with Reversible Adapters for Efficient LLM Batch Inference
Oct 06, 2024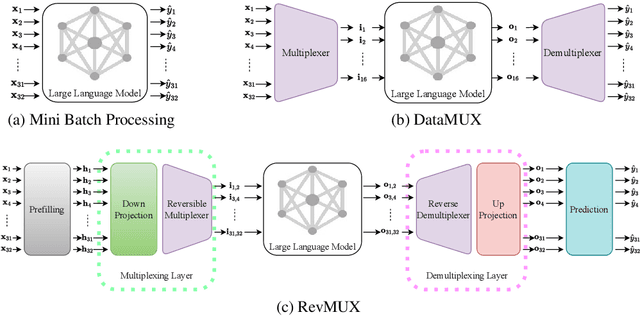
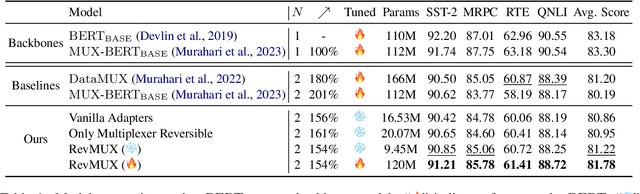
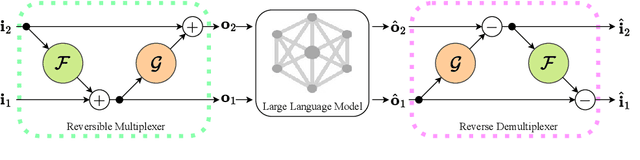
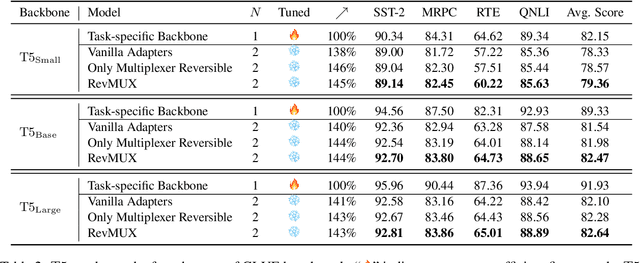
Large language models (LLMs) have brought a great breakthrough to the natural language processing (NLP) community, while leading the challenge of handling concurrent customer queries due to their high throughput demands. Data multiplexing addresses this by merging multiple inputs into a single composite input, allowing more efficient inference through a shared forward pass. However, as distinguishing individuals from a composite input is challenging, conventional methods typically require training the entire backbone, yet still suffer from performance degradation. In this paper, we introduce RevMUX, a parameter-efficient data multiplexing framework that incorporates a reversible design in the multiplexer, which can be reused by the demultiplexer to perform reverse operations and restore individual samples for classification. Extensive experiments on four datasets and three types of LLM backbones demonstrate the effectiveness of RevMUX for enhancing LLM inference efficiency while retaining a satisfactory classification performance.
Low-Dimensional Federated Knowledge Graph Embedding via Knowledge Distillation
Aug 11, 2024

Federated Knowledge Graph Embedding (FKGE) aims to facilitate collaborative learning of entity and relation embeddings from distributed Knowledge Graphs (KGs) across multiple clients, while preserving data privacy. Training FKGE models with higher dimensions is typically favored due to their potential for achieving superior performance. However, high-dimensional embeddings present significant challenges in terms of storage resource and inference speed. Unlike traditional KG embedding methods, FKGE involves multiple client-server communication rounds, where communication efficiency is critical. Existing embedding compression methods for traditional KGs may not be directly applicable to FKGE as they often require multiple model trainings which potentially incur substantial communication costs. In this paper, we propose a light-weight component based on Knowledge Distillation (KD) which is titled FedKD and tailored specifically for FKGE methods. During client-side local training, FedKD facilitates the low-dimensional student model to mimic the score distribution of triples from the high-dimensional teacher model using KL divergence loss. Unlike traditional KD way, FedKD adaptively learns a temperature to scale the score of positive triples and separately adjusts the scores of corresponding negative triples using a predefined temperature, thereby mitigating teacher over-confidence issue. Furthermore, we dynamically adjust the weight of KD loss to optimize the training process. Extensive experiments on three datasets support the effectiveness of FedKD.
A Survey on Natural Language Counterfactual Generation
Jul 04, 2024



Natural Language Counterfactual generation aims to minimally modify a given text such that the modified text will be classified into a different class. The generated counterfactuals provide insight into the reasoning behind a model's predictions by highlighting which words significantly influence the outcomes. Additionally, they can be used to detect model fairness issues or augment the training data to enhance the model's robustness. A substantial amount of research has been conducted to generate counterfactuals for various NLP tasks, employing different models and methodologies. With the rapid growth of studies in this field, a systematic review is crucial to guide future researchers and developers. To bridge this gap, this survey comprehensively overview textual counterfactual generation methods, particularly including those based on Large Language Models. We propose a new taxonomy that categorizes the generation methods into four groups and systematically summarize the metrics for evaluating the generation quality. Finally, we discuss ongoing research challenges and outline promising directions for future work.
Communication-Efficient Federated Knowledge Graph Embedding with Entity-Wise Top-K Sparsification
Jun 19, 2024



Federated Knowledge Graphs Embedding learning (FKGE) encounters challenges in communication efficiency stemming from the considerable size of parameters and extensive communication rounds. However, existing FKGE methods only focus on reducing communication rounds by conducting multiple rounds of local training in each communication round, and ignore reducing the size of parameters transmitted within each communication round. To tackle the problem, we first find that universal reduction in embedding precision across all entities during compression can significantly impede convergence speed, underscoring the importance of maintaining embedding precision. We then propose bidirectional communication-efficient FedS based on Entity-Wise Top-K Sparsification strategy. During upload, clients dynamically identify and upload only the Top-K entity embeddings with the greater changes to the server. During download, the server first performs personalized embedding aggregation for each client. It then identifies and transmits the Top-K aggregated embeddings to each client. Besides, an Intermittent Synchronization Mechanism is used by FedS to mitigate negative effect of embedding inconsistency among shared entities of clients caused by heterogeneity of Federated Knowledge Graph. Extensive experiments across three datasets showcase that FedS significantly enhances communication efficiency with negligible (even no) performance degradation.
Personalized Federated Knowledge Graph Embedding with Client-Wise Relation Graph
Jun 17, 2024



Federated Knowledge Graph Embedding (FKGE) has recently garnered considerable interest due to its capacity to extract expressive representations from distributed knowledge graphs, while concurrently safeguarding the privacy of individual clients. Existing FKGE methods typically harness the arithmetic mean of entity embeddings from all clients as the global supplementary knowledge, and learn a replica of global consensus entities embeddings for each client. However, these methods usually neglect the inherent semantic disparities among distinct clients. This oversight not only results in the globally shared complementary knowledge being inundated with too much noise when tailored to a specific client, but also instigates a discrepancy between local and global optimization objectives. Consequently, the quality of the learned embeddings is compromised. To address this, we propose Personalized Federated knowledge graph Embedding with client-wise relation Graph (PFedEG), a novel approach that employs a client-wise relation graph to learn personalized embeddings by discerning the semantic relevance of embeddings from other clients. Specifically, PFedEG learns personalized supplementary knowledge for each client by amalgamating entity embedding from its neighboring clients based on their "affinity" on the client-wise relation graph. Each client then conducts personalized embedding learning based on its local triples and personalized supplementary knowledge. We conduct extensive experiments on four benchmark datasets to evaluate our method against state-of-the-art models and results demonstrate the superiority of our method.