 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey on Natural Language Counterfactual Generation
Jul 04, 2024



Natural Language Counterfactual generation aims to minimally modify a given text such that the modified text will be classified into a different class. The generated counterfactuals provide insight into the reasoning behind a model's predictions by highlighting which words significantly influence the outcomes. Additionally, they can be used to detect model fairness issues or augment the training data to enhance the model's robustness. A substantial amount of research has been conducted to generate counterfactuals for various NLP tasks, employing different models and methodologies. With the rapid growth of studies in this field, a systematic review is crucial to guide future researchers and developers. To bridge this gap, this survey comprehensively overview textual counterfactual generation methods, particularly including those based on Large Language Models. We propose a new taxonomy that categorizes the generation methods into four groups and systematically summarize the metrics for evaluating the generation quality. Finally, we discuss ongoing research challenges and outline promising directions for future work.
PairCFR: Enhancing Model Training on Paired Counterfactually Augmented Data through Contrastive Learning
Jun 09, 2024



Counterfactually Augmented Data (CAD) involves creating new data samples by applying minimal yet sufficient modifications to flip the label of existing data samples to other classes. Training with CAD enhances model robustness against spurious features that happen to correlate with labels by spreading the casual relationships across different classes. Yet, recent research reveals that training with CAD may lead models to overly focus on modified features while ignoring other important contextual information, inadvertently introducing biases that may impair performance on out-ofdistribution (OOD) datasets. To mitigate this issue, we employ contrastive learning to promote global feature alignment in addition to learning counterfactual clues. We theoretically prove that contrastive loss can encourage models to leverage a broader range of features beyond those modified ones. Comprehensive experiments on two human-edited CAD datasets demonstrate that our proposed method outperforms the state-of-the-art on OOD datasets.
Human Activity Recognition based on Dynamic Spatio-Temporal Relations
Jun 29, 2020
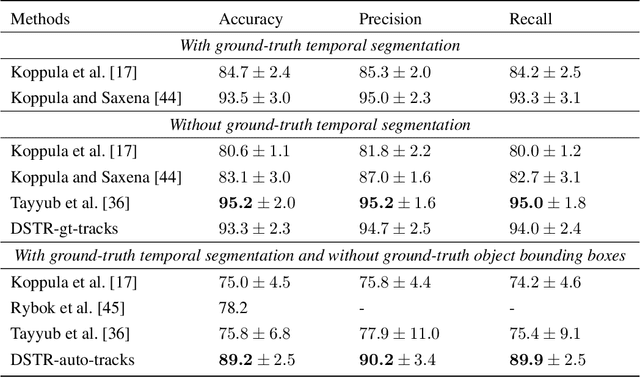
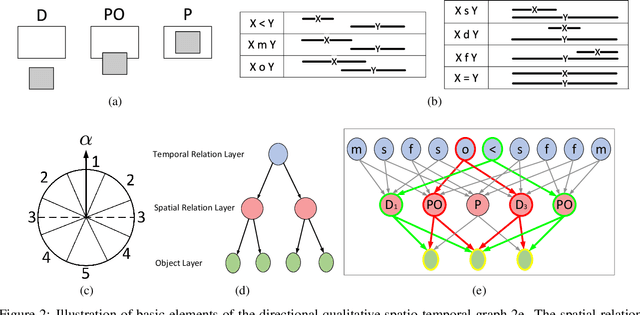
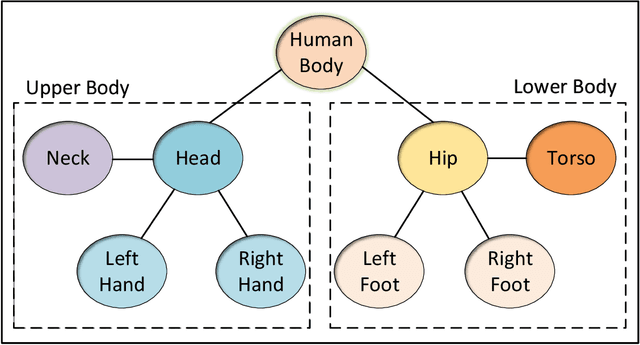
Human activity, which usually consists of several actions, generally covers interactions among persons and or objects. In particular, human actions involve certain spatial and temporal relationships, are the components of more complicated activity, and evolve dynamically over time. Therefore, the description of a single human action and the modeling of the evolution of successive human actions are two major issues in human activity recognition. In this paper, we develop a method for human activity recognition that tackles these two issues. In the proposed method, an activity is divided into several successive actions represented by spatio temporal patterns, and the evolution of these actions are captured by a sequential model. A refined comprehensive spatio temporal graph is utilized to represent a single action, which is a qualitative representation of a human action incorporating both the spatial and temporal relations of the participant objects. Next, a discrete hidden Markov model is applied to model the evolution of action sequences. Moreover, a fully automatic partition method is proposed to divide a long-term human activity video into several human actions based on variational objects and qualitative spatial relations. Finally, a hierarchical decomposition of the human body is introduced to obtain a discriminative representation for a single action. Experimental results on the Cornell Activity Dataset demonstrate the efficiency and effectiveness of the proposed approach, which will enable long videos of human activity to be better recognized.