 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Prefix Cache to Fusion RAG Cache: Accelerating LLM Inference in Retrieval-Augmented Generation
Jan 19, 2026Retrieval-Augmented Generation enhances Large Language Models by integrating external knowledge, which reduces hallucinations but increases prompt length. This increase leads to higher computational costs and longer Time to First Token (TTFT). To mitigate this issue, existing solutions aim to reuse the preprocessed KV cache of each retrieved chunk to accelerate RAG. However, the lack of cross-chunk contextual information leads to a significant drop in generation quality, leaving the potential benefits of KV cache reuse largely unfulfilled. The challenge lies in how to reuse the precomputed KV cache of chunks while preserving generation quality. We propose FusionRAG, a novel inference framework that optimizes both the preprocessing and reprocessing stages of RAG. In the offline preprocessing stage, we embed information from other related text chunks into each chunk, while in the online reprocessing stage, we recompute the KV cache for tokens that the model focuses on. As a result, we achieve a better trade-off between generation quality and efficiency. According to our experiments, FusionRAG significantly improves generation quality at the same recomputation ratio compared to previous state-of-the-art solutions. By recomputing fewer than 15% of the tokens, FusionRAG achieves up to 70% higher normalized F1 scores than baselines and reduces TTFT by 2.66x-9.39x compared to Full Attention.
Human Activity Recognition based on Dynamic Spatio-Temporal Relations
Jun 29, 2020
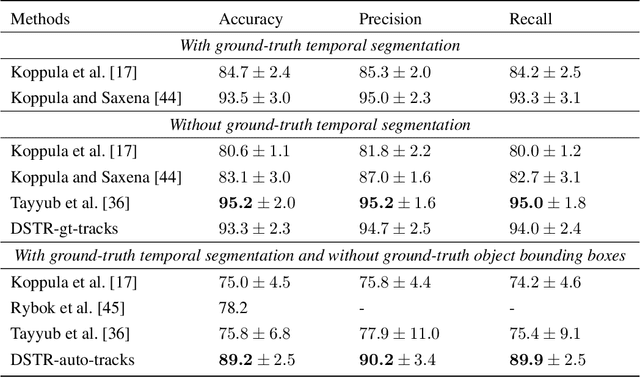
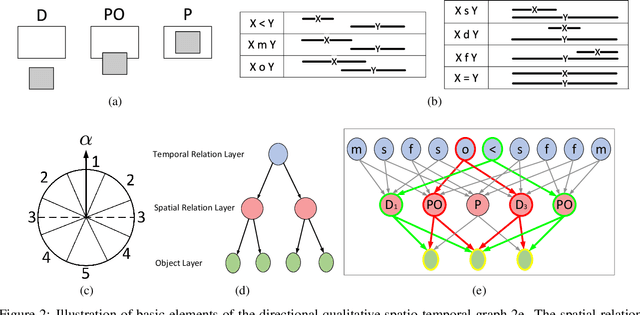
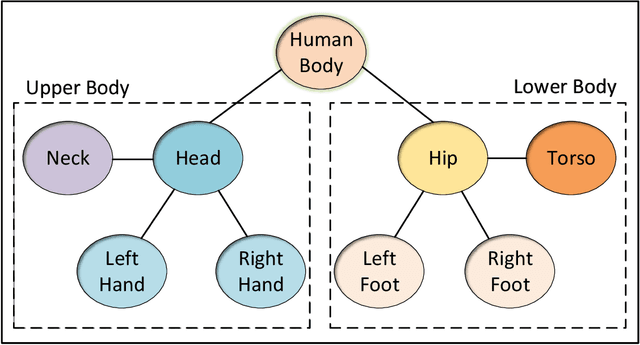
Human activity, which usually consists of several actions, generally covers interactions among persons and or objects. In particular, human actions involve certain spatial and temporal relationships, are the components of more complicated activity, and evolve dynamically over time. Therefore, the description of a single human action and the modeling of the evolution of successive human actions are two major issues in human activity recognition. In this paper, we develop a method for human activity recognition that tackles these two issues. In the proposed method, an activity is divided into several successive actions represented by spatio temporal patterns, and the evolution of these actions are captured by a sequential model. A refined comprehensive spatio temporal graph is utilized to represent a single action, which is a qualitative representation of a human action incorporating both the spatial and temporal relations of the participant objects. Next, a discrete hidden Markov model is applied to model the evolution of action sequences. Moreover, a fully automatic partition method is proposed to divide a long-term human activity video into several human actions based on variational objects and qualitative spatial relations. Finally, a hierarchical decomposition of the human body is introduced to obtain a discriminative representation for a single action. Experimental results on the Cornell Activity Dataset demonstrate the efficiency and effectiveness of the proposed approach, which will enable long videos of human activity to be better recognized.