 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText Classification based on Multi-granularity Attention Hybrid Neural Network
Aug 12, 2020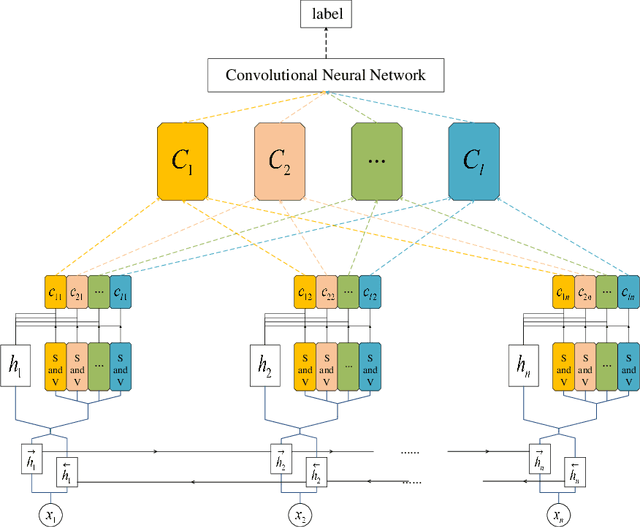
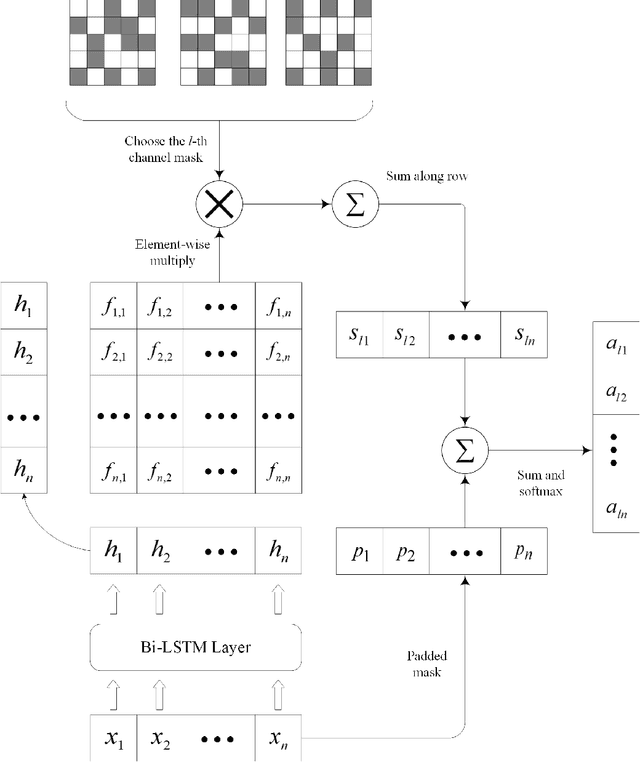

Neural network-based approaches have become the driven forces for Natural Language Processing (NLP) tasks. Conventionally, there are two mainstream neural architectures for NLP tasks: the recurrent neural network (RNN) and the convolution neural network (ConvNet). RNNs are good at modeling long-term dependencies over input texts, but preclude parallel computation. ConvNets do not have memory capability and it has to model sequential data as un-ordered features. Therefore, ConvNets fail to learn sequential dependencies over the input texts, but it is able to carry out high-efficient parallel computation. As each neural architecture, such as RNN and ConvNets, has its own pro and con, integration of different architectures is assumed to be able to enrich the semantic representation of texts, thus enhance the performance of NLP tasks. However, few investigation explores the reconciliation of these seemingly incompatible architectures. To address this issue, we propose a hybrid architecture based on a novel hierarchical multi-granularity attention mechanism, named Multi-granularity Attention-based Hybrid Neural Network (MahNN). The attention mechanism is to assign different weights to different parts of the input sequence to increase the computation efficiency and performance of neural models. In MahNN, two types of attentions are introduced: the syntactical attention and the semantical attention. The syntactical attention computes the importance of the syntactic elements (such as words or sentence) at the lower symbolic level and the semantical attention is used to compute the importance of the embedded space dimension corresponding to the upper latent semantics. We adopt the text classification as an exemplifying way to illustrate the ability of MahNN to understand texts.
Human Activity Recognition based on Dynamic Spatio-Temporal Relations
Jun 29, 2020
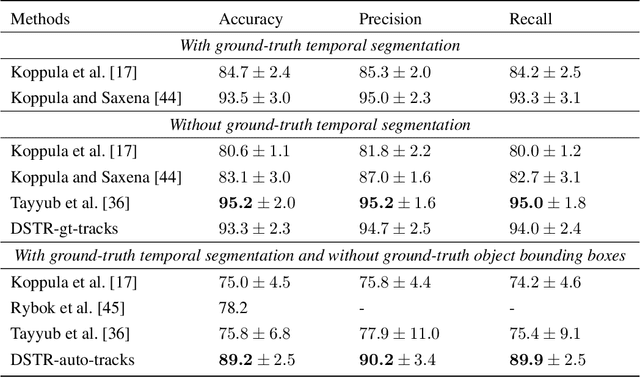
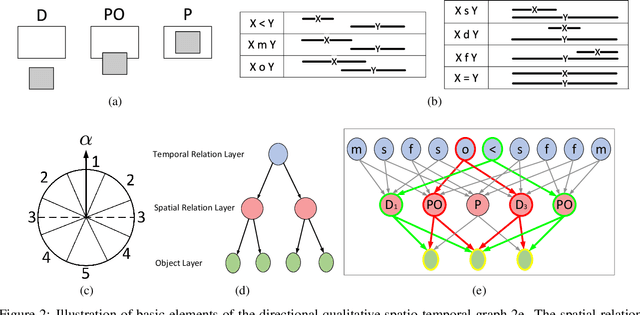
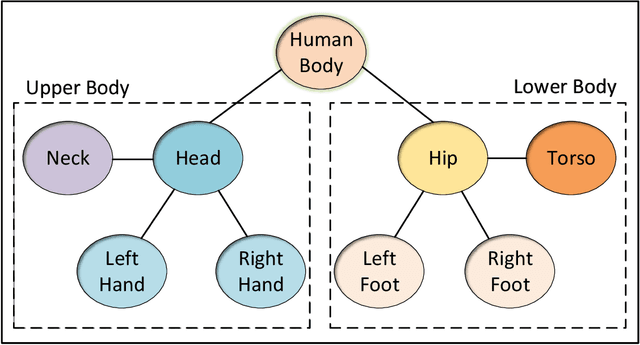
Human activity, which usually consists of several actions, generally covers interactions among persons and or objects. In particular, human actions involve certain spatial and temporal relationships, are the components of more complicated activity, and evolve dynamically over time. Therefore, the description of a single human action and the modeling of the evolution of successive human actions are two major issues in human activity recognition. In this paper, we develop a method for human activity recognition that tackles these two issues. In the proposed method, an activity is divided into several successive actions represented by spatio temporal patterns, and the evolution of these actions are captured by a sequential model. A refined comprehensive spatio temporal graph is utilized to represent a single action, which is a qualitative representation of a human action incorporating both the spatial and temporal relations of the participant objects. Next, a discrete hidden Markov model is applied to model the evolution of action sequences. Moreover, a fully automatic partition method is proposed to divide a long-term human activity video into several human actions based on variational objects and qualitative spatial relations. Finally, a hierarchical decomposition of the human body is introduced to obtain a discriminative representation for a single action. Experimental results on the Cornell Activity Dataset demonstrate the efficiency and effectiveness of the proposed approach, which will enable long videos of human activity to be better recognized.