 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman Activity Recognition based on Dynamic Spatio-Temporal Relations
Jun 29, 2020
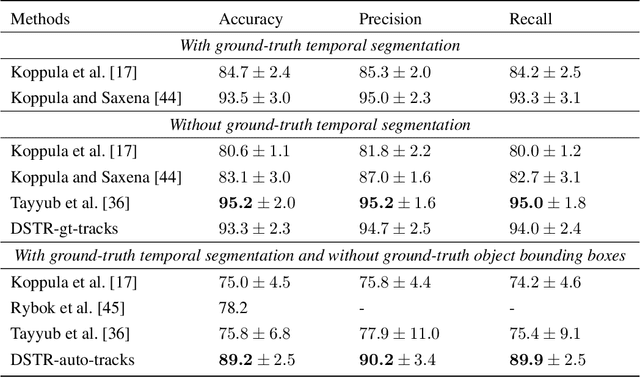
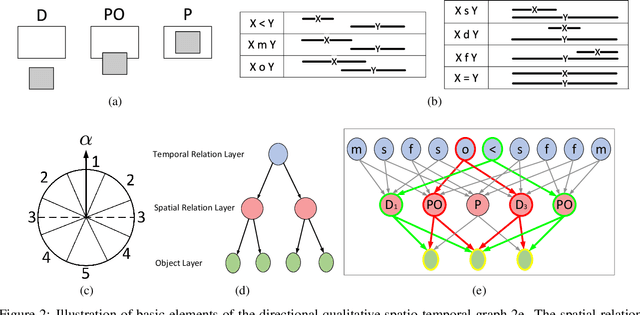
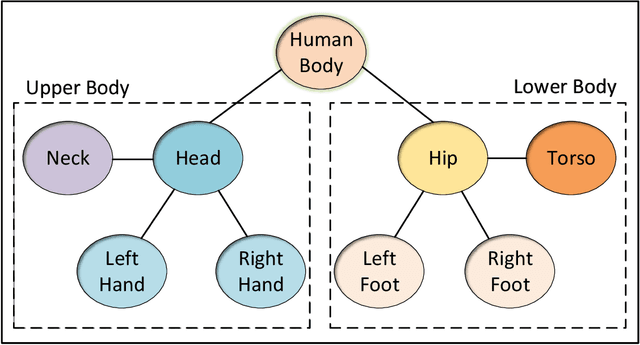
Human activity, which usually consists of several actions, generally covers interactions among persons and or objects. In particular, human actions involve certain spatial and temporal relationships, are the components of more complicated activity, and evolve dynamically over time. Therefore, the description of a single human action and the modeling of the evolution of successive human actions are two major issues in human activity recognition. In this paper, we develop a method for human activity recognition that tackles these two issues. In the proposed method, an activity is divided into several successive actions represented by spatio temporal patterns, and the evolution of these actions are captured by a sequential model. A refined comprehensive spatio temporal graph is utilized to represent a single action, which is a qualitative representation of a human action incorporating both the spatial and temporal relations of the participant objects. Next, a discrete hidden Markov model is applied to model the evolution of action sequences. Moreover, a fully automatic partition method is proposed to divide a long-term human activity video into several human actions based on variational objects and qualitative spatial relations. Finally, a hierarchical decomposition of the human body is introduced to obtain a discriminative representation for a single action. Experimental results on the Cornell Activity Dataset demonstrate the efficiency and effectiveness of the proposed approach, which will enable long videos of human activity to be better recognized.
Short Isometric Shapelet Transform for Binary Time Series Classification
Dec 27, 2019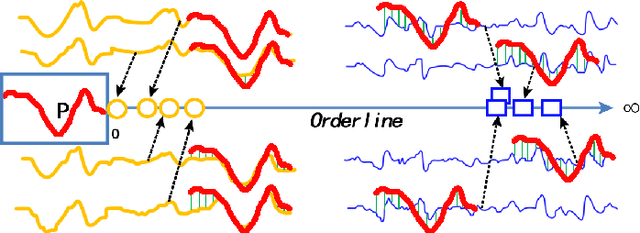
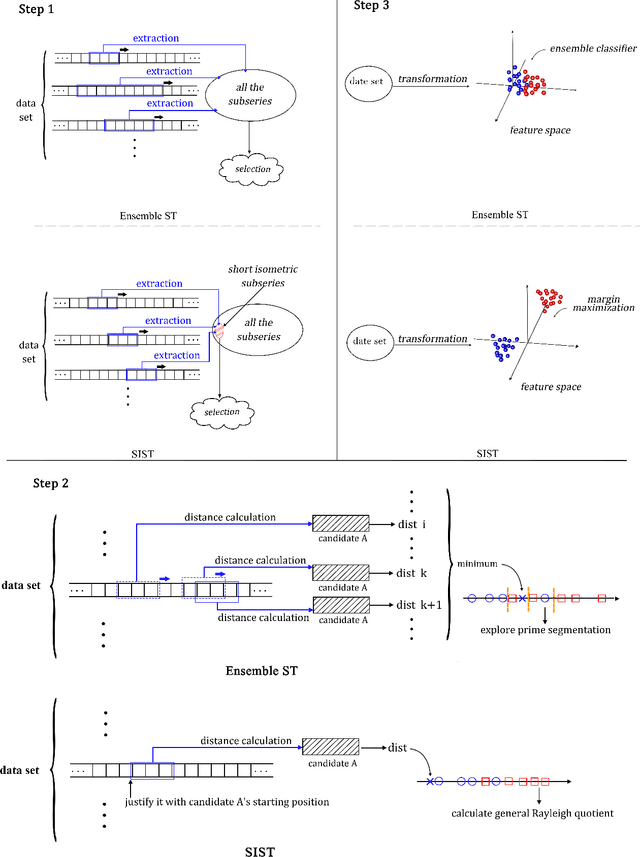
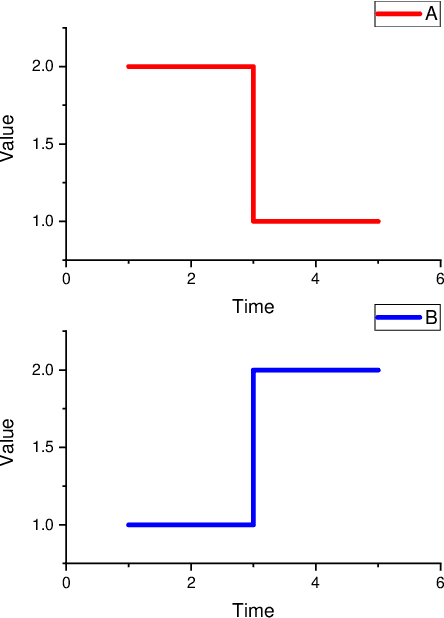
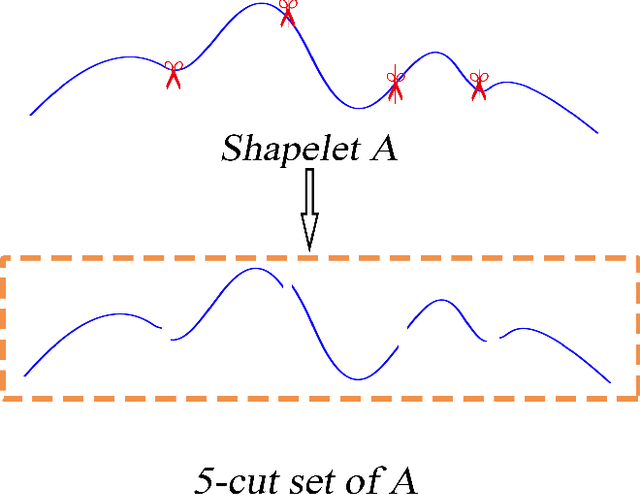
In the research area of time series classification (TSC), ensemble shapelet transform (ST) algorithm is one of state-of-the-art algorithms for classification. However, the time complexity of it is often higher than other algorithms. Hence, two strategies of reducing the high time complexity are proposed in this paper. The first one is to only exploit shapelet candidates whose length is a given small value, whereas the ensemble ST uses shapelet candidates of all the feasible lengths. The second one is to train a single linear classifier in the feature space, whereas the ensemble ST requires an ensemble classifier trained in the feature space. This paper focuses on the theoretical evidences and the empirical implementation of these two strategies. The theoretical part guarantees a near-lossless accuracy under some preconditions while reducing the time complexity. In the empirical part, an algorithm is proposed as a model implementation of these two strategies. The superior performance of the proposed algorithm on some experiments shows the effectiveness of these two strategies.
Bayesian Optimization with Directionally Constrained Search
Jun 22, 2019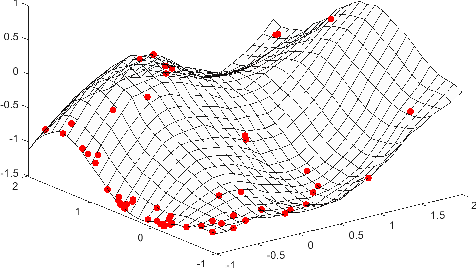
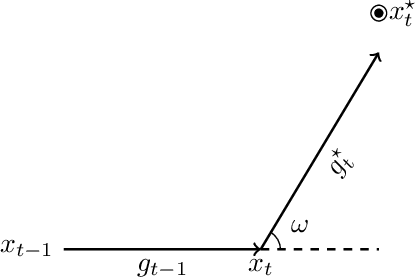

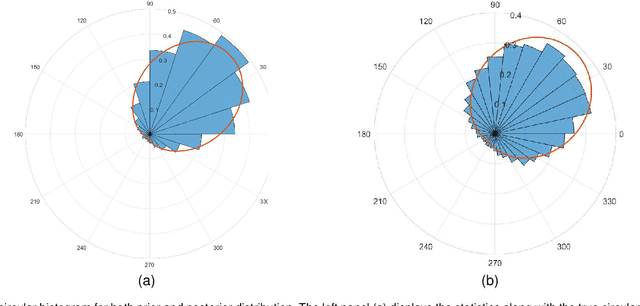
Bayesian optimization offers a flexible framework to optimize an objective function that is expensive to be evaluated. A Bayesian optimizer iteratively queries the function values on its carefully selected points. Subsequently, it makes a sensible recommendation about where the optimum locates based on its accumulated knowledge. This procedure usually demands a long execution time. In practice, however, there often exists a computational budget or an evaluation limitation allocated to an optimizer, due to the resource scarcity. This constraint demands an optimizer to be aware of its remaining budget and able to spend it wisely, in order to return as better a point as possible. In this paper, we propose a Bayesian optimization approach in this evaluation-limited scenario. Our approach is based on constraining searching directions so as to dedicate the model capability to the most promising area. It could be viewed as a combination of local and global searching policies, which aims at reducing inefficient exploration in the local searching areas, thus making a searching policy more efficient. Experimental studies are conducted on both synthetic and real-world applications. The results demonstrate the superior performance of our newly proposed approach in searching for the optimum within a prescribed evaluation budget.
Multiple Kernel $k$-Means Clustering by Selecting Representative Kernels
Nov 01, 2018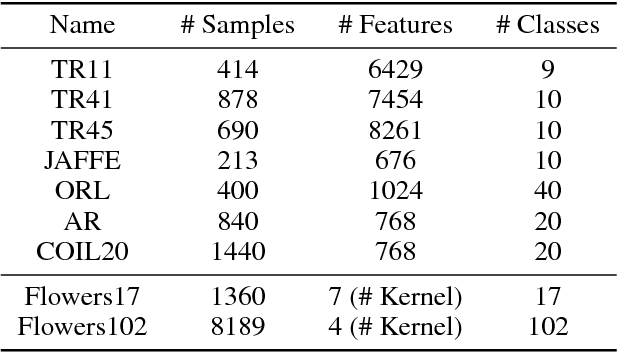
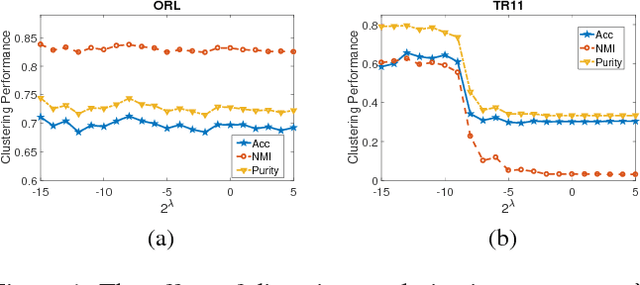
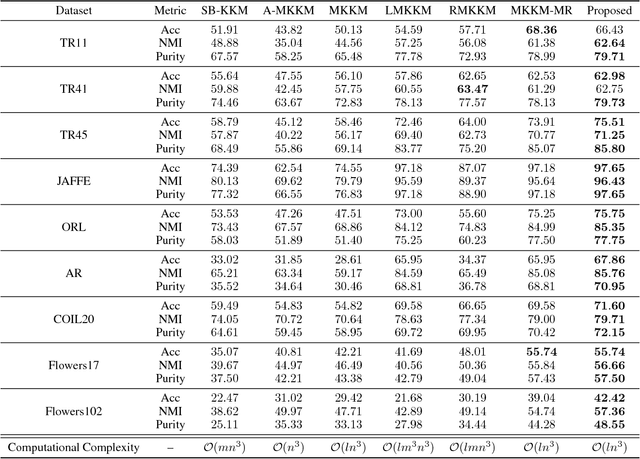
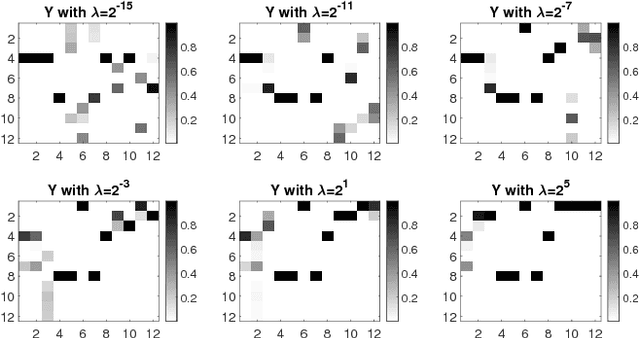
To cluster data that are not linearly separable in the original feature space, $k$-means clustering was extended to the kernel version. However, the performance of kernel $k$-means clustering largely depends on the choice of kernel function. To mitigate this problem, multiple kernel learning has been introduced into the $k$-means clustering to obtain an optimal kernel combination for clustering. Despite the success of multiple kernel $k$-means clustering in various scenarios, few of the existing work update the combination coefficients based on the diversity of kernels, which leads to the result that the selected kernels contain high redundancy and would degrade the clustering performance and efficiency. In this paper, we propose a simple but efficient strategy that selects a diverse subset from the pre-specified kernels as the representative kernels, and then incorporate the subset selection process into the framework of multiple $k$-means clustering. The representative kernels can be indicated as the significant combination weights. Due to the non-convexity of the obtained objective function, we develop an alternating minimization method to optimize the combination coefficients of the selected kernels and the cluster membership alternatively. We evaluate the proposed approach on several benchmark and real-world datasets. The experimental results demonstrate the competitiveness of our approach in comparison with the state-of-the-art methods.
Skeleton-based Activity Recognition with Local Order Preserving Match of Linear Patches
Nov 01, 2018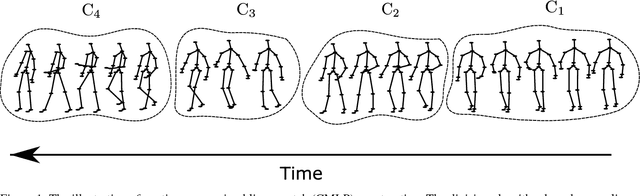
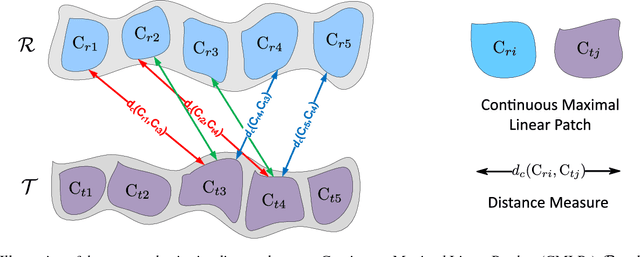

Human activity recognition has drawn considerable attention recently in the field of computer vision due to the development of commodity depth cameras, by which the human activity is represented as a sequence of 3D skeleton postures. Assuming human body 3D joint locations of an activity lie on a manifold, the problem of recognizing human activity is formulated as the computation of activity manifold-manifold distance (AMMD). In this paper, we first design an efficient division method to decompose a manifold into ordered continuous maximal linear patches (CMLPs) that denote meaningful action snippets of the action sequence. Then the CMLP is represented by its position (average value of points) and the first principal component, which specify the major posture and main evolving direction of an action snippet, respectively. Finally, we compute the distance between CMLPs by taking both the posture and direction into consideration. Based on these preparations, an intuitive distance measure that preserves the local order of action snippets is proposed to compute AMMD. The performance on two benchmark datasets demonstrates the effectiveness of the proposed approach.
Ensemble Pruning based on Objection Maximization with a General Distributed Framework
Jun 16, 2018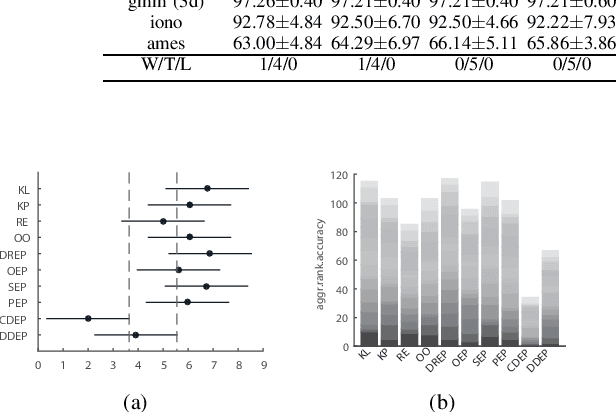
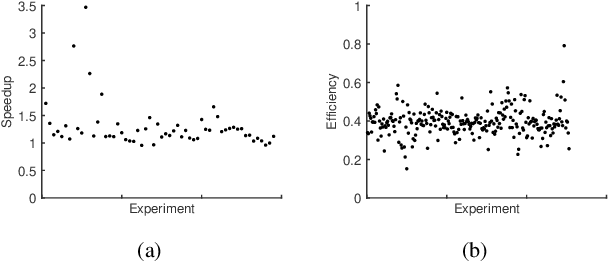


Ensemble pruning, selecting a subset of individual learners from an original ensemble, alleviates the deficiencies of ensemble learning on the cost of time and space. Accuracy and diversity serve as two crucial factors while they usually conflict with each other. To balance both of them, we formalize the ensemble pruning problem as an objection maximization problem based on information entropy. Then we propose an ensemble pruning method including a centralized version and a distributed version, in which the latter is to speed up the former's execution. At last, we extract a general distributed framework for ensemble pruning, which can be widely suitable for most of existing ensemble pruning methods and achieve less time consuming without much accuracy decline. Experimental results validate the efficiency of our framework and methods, particularly with regard to a remarkable improvement of the execution speed, accompanied by gratifying accuracy performance.