 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReservoir-enhanced Segment Anything Model for Subsurface Diagnosis
Apr 26, 2025Urban roads and infrastructure, vital to city operations, face growing threats from subsurface anomalies like cracks and cavities. Ground Penetrating Radar (GPR) effectively visualizes underground conditions employing electromagnetic (EM) waves; however, accurate anomaly detection via GPR remains challenging due to limited labeled data, varying subsurface conditions, and indistinct target boundaries. Although visually image-like, GPR data fundamentally represent EM waves, with variations within and between waves critical for identifying anomalies. Addressing these, we propose the Reservoir-enhanced Segment Anything Model (Res-SAM), an innovative framework exploiting both visual discernibility and wave-changing properties of GPR data. Res-SAM initially identifies apparent candidate anomaly regions given minimal prompts, and further refines them by analyzing anomaly-induced changing information within and between EM waves in local GPR data, enabling precise and complete anomaly region extraction and category determination. Real-world experiments demonstrate that Res-SAM achieves high detection accuracy (>85%) and outperforms state-of-the-art. Notably, Res-SAM requires only minimal accessible non-target data, avoids intensive training, and incorporates simple human interaction to enhance reliability. Our research provides a scalable, resource-efficient solution for rapid subsurface anomaly detection across diverse environments, improving urban safety monitoring while reducing manual effort and computational cost.
A Binary Classification Social Network Dataset for Graph Machine Learning
Mar 04, 2025Social networks have a vast range of applications with graphs. The available benchmark datasets are citation, co-occurrence, e-commerce networks, etc, with classes ranging from 3 to 15. However, there is no benchmark classification social network dataset for graph machine learning. This paper fills the gap and presents the Binary Classification Social Network Dataset (\textit{BiSND}), designed for graph machine learning applications to predict binary classes. We present the BiSND in \textit{tabular and graph} formats to verify its robustness across classical and advanced machine learning. We employ a diverse set of classifiers, including four traditional machine learning algorithms (Decision Trees, K-Nearest Neighbour, Random Forest, XGBoost), one Deep Neural Network (multi-layer perceptrons), one Graph Neural Network (Graph Convolutional Network), and three state-of-the-art Graph Contrastive Learning methods (BGRL, GRACE, DAENS). Our findings reveal that BiSND is suitable for classification tasks, with F1-scores ranging from 67.66 to 70.15, indicating promising avenues for future enhancements.
MTMT: Consolidating Multiple Thinking Modes to Form a Thought Tree for Strengthening LLM
Dec 05, 2024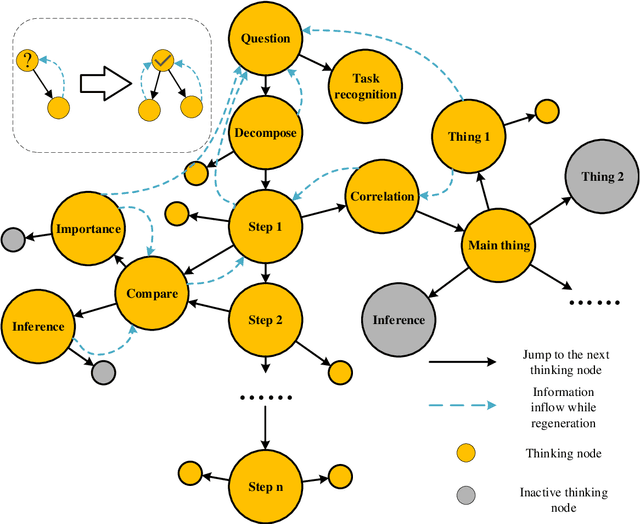
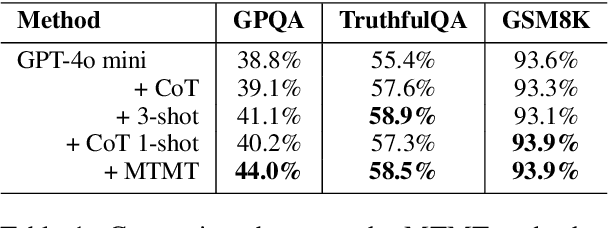
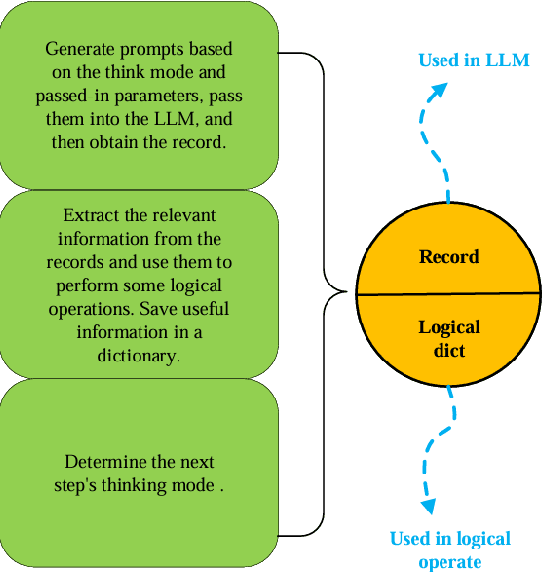
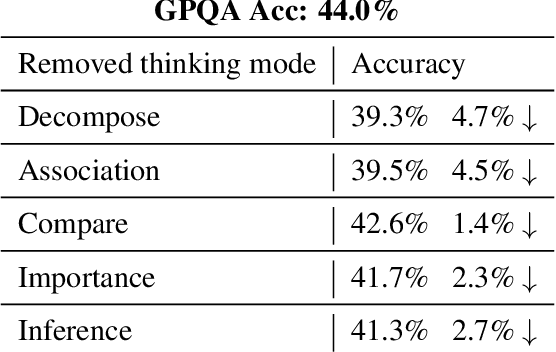
Large language models (LLMs) have shown limitations in tasks requiring complex logical reasoning and multi-step problem-solving. To address these challenges, researchers have employed carefully designed prompts and flowcharts, simulating human cognitive processes to enhance LLM performance, such as the Chain of Thought approach. In this paper, we introduce MTMT (Multi-thinking Modes Tree), a novel method that interacts with LLMs to construct a thought tree, simulating various advanced cognitive processes, including but not limited to association, counterfactual thinking, task decomposition, and comparison. By breaking down the original complex task into simpler sub-questions, MTMT facilitates easier problem-solving for LLMs, enabling more effective utilization of the latent knowledge within LLMs. We evaluate the performance of MTMT under different parameter configurations, using GPT-4o mini as the base model. Our results demonstrate that integrating multiple modes of thinking significantly enhances the ability of LLMs to handle complex tasks.
From Overfitting to Robustness: Quantity, Quality, and Variety Oriented Negative Sample Selection in Graph Contrastive Learning
Jun 21, 2024



Graph contrastive learning (GCL) aims to contrast positive-negative counterparts to learn the node embeddings, whereas graph data augmentation methods are employed to generate these positive-negative samples. The variation, quantity, and quality of negative samples compared to positive samples play crucial roles in learning meaningful embeddings for node classification downstream tasks. Less variation, excessive quantity, and low-quality negative samples cause the model to be overfitted for particular nodes, resulting in less robust models. To solve the overfitting problem in the GCL paradigm, this study proposes a novel Cumulative Sample Selection (CSS) algorithm by comprehensively considering negative samples' quality, variations, and quantity. Initially, three negative sample pools are constructed: easy, medium, and hard negative samples, which contain 25%, 50%, and 25% of the total available negative samples, respectively. Then, 10% negative samples are selected from each of these three negative sample pools for training the model. After that, a decision agent module evaluates model training results and decides whether to explore more negative samples from three negative sample pools by increasing the ratio or keep exploiting the current sampling ratio. The proposed algorithm is integrated into a proposed graph contrastive learning framework named NegAmplify. NegAmplify is compared with the SOTA methods on nine graph node classification datasets, with seven achieving better node classification accuracy with up to 2.86% improvement.
Causal Structure Learning Supervised by Large Language Model
Nov 20, 2023



Causal discovery from observational data is pivotal for deciphering complex relationships. Causal Structure Learning (CSL), which focuses on deriving causal Directed Acyclic Graphs (DAGs) from data, faces challenges due to vast DAG spaces and data sparsity. The integration of Large Language Models (LLMs), recognized for their causal reasoning capabilities, offers a promising direction to enhance CSL by infusing it with knowledge-based causal inferences. However, existing approaches utilizing LLMs for CSL have encountered issues, including unreliable constraints from imperfect LLM inferences and the computational intensity of full pairwise variable analyses. In response, we introduce the Iterative LLM Supervised CSL (ILS-CSL) framework. ILS-CSL innovatively integrates LLM-based causal inference with CSL in an iterative process, refining the causal DAG using feedback from LLMs. This method not only utilizes LLM resources more efficiently but also generates more robust and high-quality structural constraints compared to previous methodologies. Our comprehensive evaluation across eight real-world datasets demonstrates ILS-CSL's superior performance, setting a new standard in CSL efficacy and showcasing its potential to significantly advance the field of causal discovery. The codes are available at \url{https://github.com/tyMadara/ILS-CSL}.
Reinforcement Learning-based Non-Autoregressive Solver for Traveling Salesman Problems
Aug 01, 2023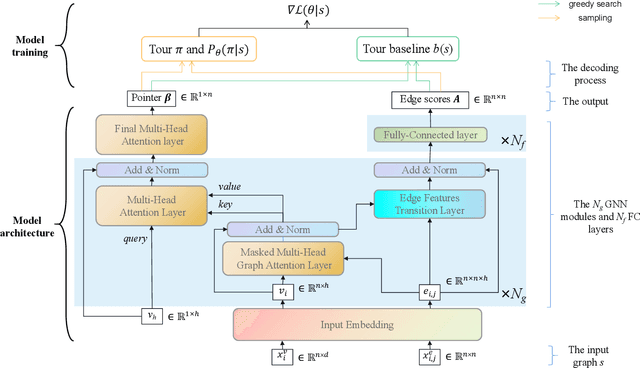

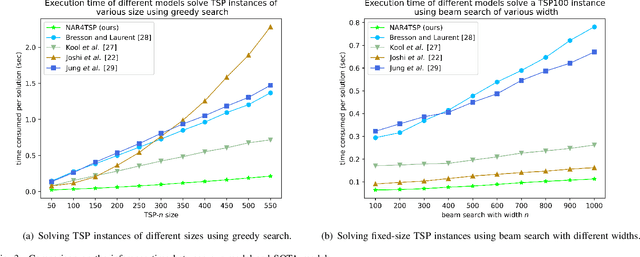
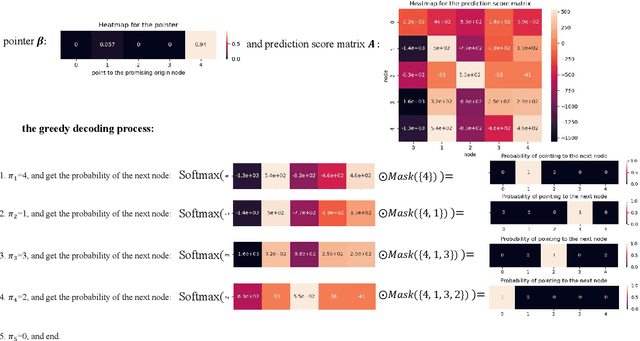
The Traveling Salesman Problem (TSP) is a well-known problem in combinatorial optimization with applications in various domains. However, existing TSP solvers face challenges in producing high-quality solutions with low latency. To address this issue, we propose NAR4TSP, which produces TSP solutions in a Non-Autoregressive (NAR) manner using a specially designed Graph Neural Network (GNN), achieving faster inference speed. Moreover, NAR4TSP is trained using an enhanced Reinforcement Learning (RL) strategy, eliminating the dependency on costly labels used to train conventional supervised learning-based NAR models. To the best of our knowledge, NAR4TSP is the first TSP solver that successfully combines RL and NAR decoding. The experimental results on both synthetic and real-world TSP instances demonstrate that NAR4TSP outperforms four state-of-the-art models in terms of solution quality, inference latency, and generalization ability. Lastly, we present visualizations of NAR4TSP's decoding process and its overall path planning to showcase the feasibility of implementing NAR4TSP in an end-to-end manner and its effectiveness, respectively.
From Query Tools to Causal Architects: Harnessing Large Language Models for Advanced Causal Discovery from Data
Jun 29, 2023



Large Language Models (LLMs) exhibit exceptional abilities for causal analysis between concepts in numerous societally impactful domains, including medicine, science, and law. Recent research on LLM performance in various causal discovery and inference tasks has given rise to a new ladder in the classical three-stage framework of causality. In this paper, we advance the current research of LLM-driven causal discovery by proposing a novel framework that combines knowledge-based LLM causal analysis with data-driven causal structure learning. To make LLM more than a query tool and to leverage its power in discovering natural and new laws of causality, we integrate the valuable LLM expertise on existing causal mechanisms into statistical analysis of objective data to build a novel and practical baseline for causal structure learning. We introduce a universal set of prompts designed to extract causal graphs from given variables and assess the influence of LLM prior causality on recovering causal structures from data. We demonstrate the significant enhancement of LLM expertise on the quality of recovered causal structures from data, while also identifying critical challenges and issues, along with potential approaches to address them. As a pioneering study, this paper aims to emphasize the new frontier that LLMs are opening for classical causal discovery and inference, and to encourage the widespread adoption of LLM capabilities in data-driven causal analysis.
Mitigating Prior Errors in Causal Structure Learning: Towards LLM driven Prior Knowledge
Jun 12, 2023Causal structure learning, a prominent technique for encoding cause and effect relationships among variables, through Bayesian Networks (BNs). Merely recovering causal structures from real-world observed data lacks precision, while the development of Large Language Models (LLM) is opening a new frontier of causality. LLM presents strong capability in discovering causal relationships between variables with the "text" inputs defining the investigated variables, leading to a potential new hierarchy and new ladder of causality. We aim an critical issue in the emerging topic of LLM based causal structure learning, to tackle erroneous prior causal statements from LLM, which is seldom considered in the current context of expert dominating prior resources. As a pioneer attempt, we propose a BN learning strategy resilient to prior errors without need of human intervention. Focusing on the edge-level prior, we classify the possible prior errors into three types: order-consistent, order-reversed, and irrelevant, and provide their theoretical impact on the Structural Hamming Distance (SHD) under the presumption of sufficient data. Intriguingly, we discover and prove that only the order-reversed error contributes to an increase in a unique acyclic closed structure, defined as a "quasi-circle". Leveraging this insight, a post-hoc strategy is employed to identify the order-reversed prior error by its impact on the increment of "quasi-circles". Through empirical evaluation on both real and synthetic datasets, we demonstrate our strategy's robustness against prior errors. Specifically, we highlight its substantial ability to resist order-reversed errors while maintaining the majority of correct prior knowledge.
Underground Diagnosis Based on GPR and Learning in the Model Space
Nov 25, 2022Ground Penetrating Radar (GPR) has been widely used in pipeline detection and underground diagnosis. In practical applications, the characteristics of the GPR data of the detected area and the likely underground anomalous structures could be rarely acknowledged before fully analyzing the obtained GPR data, causing challenges to identify the underground structures or abnormals automatically. In this paper, a GPR B-scan image diagnosis method based on learning in the model space is proposed. The idea of learning in the model space is to use models fitted on parts of data as more stable and parsimonious representations of the data. For the GPR image, 2-Direction Echo State Network (2D-ESN) is proposed to fit the image segments through the next item prediction. By building the connections between the points on the image in both the horizontal and vertical directions, the 2D-ESN regards the GPR image segment as a whole and could effectively capture the dynamic characteristics of the GPR image. And then, semi-supervised and supervised learning methods could be further implemented on the 2D-ESN models for underground diagnosis. Experiments on real-world datasets are conducted, and the results demonstrate the effectiveness of the proposed model.
BRIEF but Powerful: Byzantine-Robust and Privacy-Preserving Federated Learning via Model Segmentation and Secure clustering
Aug 22, 2022
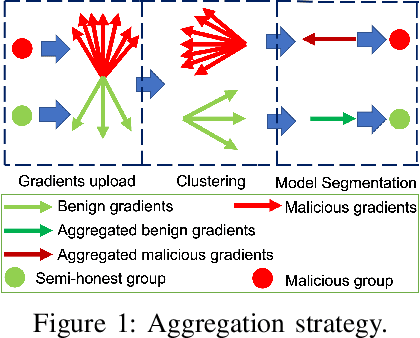
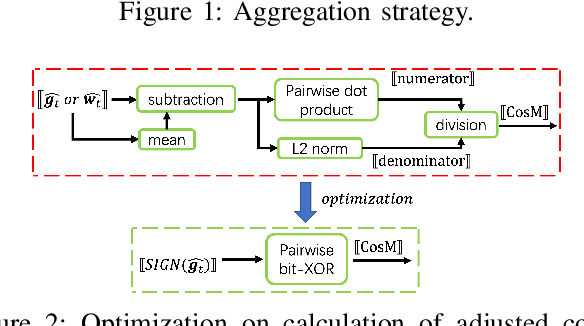
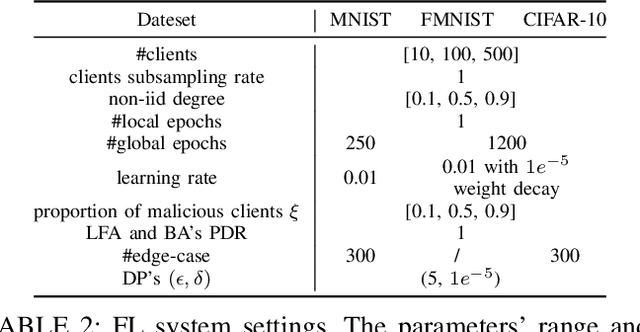
Byzantine-robust Federated Learning (FL) aims to counter malicious clients and to train an accurate global model while maintaining an extremely low attack success rate. Most of the existing systems, however, are only robust in honest/semi-honest majority settings. FLTrust (NDSS '21) extends the context to the malicious majority for clients but with a strong restriction that the server should be provided with an auxiliary dataset before training in order to filter malicious inputs. Private FLAME/FLGUARD (USENIX '22) gives a solution to guarantee both robustness and updates confidentiality in the semi-honest majority context. It is so far impossible to balance the trade-off among malicious context, robustness, and updates confidentiality. To tackle this problem, we propose a novel Byzantine-robust and privacy-preserving FL system, called BRIEF, to capture malicious minority and majority for server and client sides. Specifically, based on the DBSCAN algorithm, we design a new method for clustering via pairwise adjusted cosine similarity to boost the accuracy of the clustering results. To thwart attacks of malicious majority, we develop an algorithm called Model Segmentation, where local updates in the same cluster are aggregated together, and the aggregations are sent back to corresponding clients correctly. We also leverage multiple cryptographic tools to conduct clustering tasks without sacrificing training correctness and updates confidentiality. We present detailed security proof and empirical evaluation along with convergence analysis for BRIEF. The experimental results demonstrate that the testing accuracy of BRIEF is practically close to the FL baseline (0.8% gap on average). At the same time, the attack success rate is around 0%-5%. We further optimize our design so that the communication overhead and runtime can be decreased by {67%-89.17% and 66.05%-68.75%}, respectively.