 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOblivionis: A Lightweight Learning and Unlearning Framework for Federated Large Language Models
Aug 12, 2025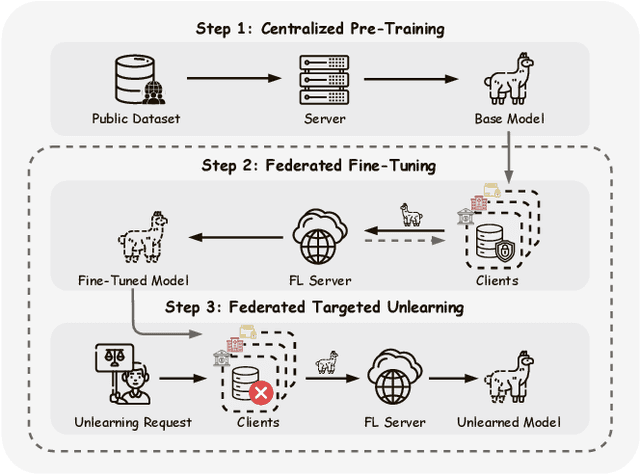
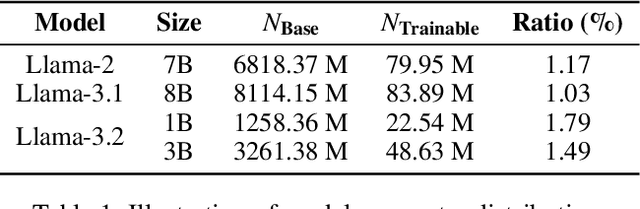
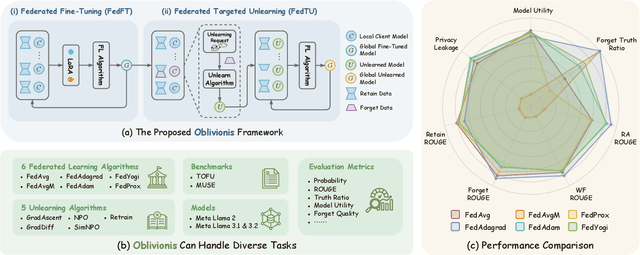
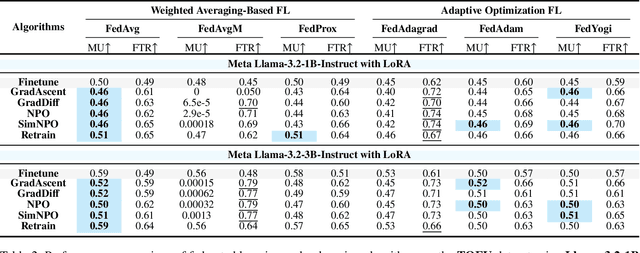
Large Language Models (LLMs) increasingly leverage Federated Learning (FL) to utilize private, task-specific datasets for fine-tuning while preserving data privacy. However, while federated LLM frameworks effectively enable collaborative training without raw data sharing, they critically lack built-in mechanisms for regulatory compliance like GDPR's right to be forgotten. Integrating private data heightens concerns over data quality and long-term governance, yet existing distributed training frameworks offer no principled way to selectively remove specific client contributions post-training. Due to distributed data silos, stringent privacy constraints, and the intricacies of interdependent model aggregation, federated LLM unlearning is significantly more complex than centralized LLM unlearning. To address this gap, we introduce Oblivionis, a lightweight learning and unlearning framework that enables clients to selectively remove specific private data during federated LLM training, enhancing trustworthiness and regulatory compliance. By unifying FL and unlearning as a dual optimization objective, we incorporate 6 FL and 5 unlearning algorithms for comprehensive evaluation and comparative analysis, establishing a robust pipeline for federated LLM unlearning. Extensive experiments demonstrate that Oblivionis outperforms local training, achieving a robust balance between forgetting efficacy and model utility, with cross-algorithm comparisons providing clear directions for future LLM development.
Reservoir-enhanced Segment Anything Model for Subsurface Diagnosis
Apr 26, 2025Urban roads and infrastructure, vital to city operations, face growing threats from subsurface anomalies like cracks and cavities. Ground Penetrating Radar (GPR) effectively visualizes underground conditions employing electromagnetic (EM) waves; however, accurate anomaly detection via GPR remains challenging due to limited labeled data, varying subsurface conditions, and indistinct target boundaries. Although visually image-like, GPR data fundamentally represent EM waves, with variations within and between waves critical for identifying anomalies. Addressing these, we propose the Reservoir-enhanced Segment Anything Model (Res-SAM), an innovative framework exploiting both visual discernibility and wave-changing properties of GPR data. Res-SAM initially identifies apparent candidate anomaly regions given minimal prompts, and further refines them by analyzing anomaly-induced changing information within and between EM waves in local GPR data, enabling precise and complete anomaly region extraction and category determination. Real-world experiments demonstrate that Res-SAM achieves high detection accuracy (>85%) and outperforms state-of-the-art. Notably, Res-SAM requires only minimal accessible non-target data, avoids intensive training, and incorporates simple human interaction to enhance reliability. Our research provides a scalable, resource-efficient solution for rapid subsurface anomaly detection across diverse environments, improving urban safety monitoring while reducing manual effort and computational cost.
Tokenize Image Patches: Global Context Fusion for Effective Haze Removal in Large Images
Apr 13, 2025Global contextual information and local detail features are essential for haze removal tasks. Deep learning models perform well on small, low-resolution images, but they encounter difficulties with large, high-resolution ones due to GPU memory limitations. As a compromise, they often resort to image slicing or downsampling. The former diminishes global information, while the latter discards high-frequency details. To address these challenges, we propose DehazeXL, a haze removal method that effectively balances global context and local feature extraction, enabling end-to-end modeling of large images on mainstream GPU hardware. Additionally, to evaluate the efficiency of global context utilization in haze removal performance, we design a visual attribution method tailored to the characteristics of haze removal tasks. Finally, recognizing the lack of benchmark datasets for haze removal in large images, we have developed an ultra-high-resolution haze removal dataset (8KDehaze) to support model training and testing. It includes 10000 pairs of clear and hazy remote sensing images, each sized at 8192 $\times$ 8192 pixels. Extensive experiments demonstrate that DehazeXL can infer images up to 10240 $\times$ 10240 pixels with only 21 GB of memory, achieving state-of-the-art results among all evaluated methods. The source code and experimental dataset are available at https://github.com/CastleChen339/DehazeXL.
Effectiveness Assessment of Recent Large Vision-Language Models
Mar 07, 2024The advent of large vision-language models (LVLMs) represents a noteworthy advancement towards the pursuit of artificial general intelligence. However, the extent of their efficacy across both specialized and general tasks warrants further investigation. This article endeavors to evaluate the competency of popular LVLMs in specialized and general tasks, respectively, aiming to offer a comprehensive comprehension of these innovative methodologies. To gauge their efficacy in specialized tasks, we tailor a comprehensive testbed comprising three distinct scenarios: natural, healthcare, and industrial, encompassing six challenging tasks. These tasks include salient, camouflaged, and transparent object detection, as well as polyp and skin lesion detection, alongside industrial anomaly detection. We examine the performance of three recent open-source LVLMs -- MiniGPT-v2, LLaVA-1.5, and Shikra -- in the realm of visual recognition and localization. Moreover, we conduct empirical investigations utilizing the aforementioned models alongside GPT-4V, assessing their multi-modal understanding capacities in general tasks such as object counting, absurd question answering, affordance reasoning, attribute recognition, and spatial relation reasoning. Our investigations reveal that these models demonstrate limited proficiency not only in specialized tasks but also in general tasks. We delve deeper into this inadequacy and suggest several potential factors, including limited cognition in specialized tasks, object hallucination, text-to-image interference, and decreased robustness in complex problems. We hope this study would provide valuable insights for the future development of LVLMs, augmenting their power in coping with both general and specialized applications.