 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Level Correlation Network For Few-Shot Image Classification
Dec 04, 2024



Few-shot image classification(FSIC) aims to recognize novel classes given few labeled images from base classes. Recent works have achieved promising classification performance, especially for metric-learning methods, where a measure at only image feature level is usually used. In this paper, we argue that measure at such a level may not be effective enough to generalize from base to novel classes when using only a few images. Instead, a multi-level descriptor of an image is taken for consideration in this paper. We propose a multi-level correlation network (MLCN) for FSIC to tackle this problem by effectively capturing local information. Concretely, we present the self-correlation module and cross-correlation module to learn the semantic correspondence relation of local information based on learned representations. Moreover, we propose a pattern-correlation module to capture the pattern of fine-grained images and find relevant structural patterns between base classes and novel classes. Extensive experiments and analysis show the effectiveness of our proposed method on four widely-used FSIC benchmarks. The code for our approach is available at: https://github.com/Yunkai696/MLCN.
Effectiveness Assessment of Recent Large Vision-Language Models
Mar 07, 2024The advent of large vision-language models (LVLMs) represents a noteworthy advancement towards the pursuit of artificial general intelligence. However, the extent of their efficacy across both specialized and general tasks warrants further investigation. This article endeavors to evaluate the competency of popular LVLMs in specialized and general tasks, respectively, aiming to offer a comprehensive comprehension of these innovative methodologies. To gauge their efficacy in specialized tasks, we tailor a comprehensive testbed comprising three distinct scenarios: natural, healthcare, and industrial, encompassing six challenging tasks. These tasks include salient, camouflaged, and transparent object detection, as well as polyp and skin lesion detection, alongside industrial anomaly detection. We examine the performance of three recent open-source LVLMs -- MiniGPT-v2, LLaVA-1.5, and Shikra -- in the realm of visual recognition and localization. Moreover, we conduct empirical investigations utilizing the aforementioned models alongside GPT-4V, assessing their multi-modal understanding capacities in general tasks such as object counting, absurd question answering, affordance reasoning, attribute recognition, and spatial relation reasoning. Our investigations reveal that these models demonstrate limited proficiency not only in specialized tasks but also in general tasks. We delve deeper into this inadequacy and suggest several potential factors, including limited cognition in specialized tasks, object hallucination, text-to-image interference, and decreased robustness in complex problems. We hope this study would provide valuable insights for the future development of LVLMs, augmenting their power in coping with both general and specialized applications.
Global and Local Sensitivity Guided Key Salient Object Re-augmentation for Video Saliency Detection
Nov 19, 2018



The existing still-static deep learning based saliency researches do not consider the weighting and highlighting of extracted features from different layers, all features contribute equally to the final saliency decision-making. Such methods always evenly detect all "potentially significant regions" and unable to highlight the key salient object, resulting in detection failure of dynamic scenes. In this paper, based on the fact that salient areas in videos are relatively small and concentrated, we propose a \textbf{key salient object re-augmentation method (KSORA) using top-down semantic knowledge and bottom-up feature guidance} to improve detection accuracy in video scenes. KSORA includes two sub-modules (WFE and KOS): WFE processes local salient feature selection using bottom-up strategy, while KOS ranks each object in global fashion by top-down statistical knowledge, and chooses the most critical object area for local enhancement. The proposed KSORA can not only strengthen the saliency value of the local key salient object but also ensure global saliency consistency. Results on three benchmark datasets suggest that our model has the capability of improving the detection accuracy on complex scenes. The significant performance of KSORA, with a speed of 17FPS on modern GPUs, has been verified by comparisons with other ten state-of-the-art algorithms.
SG-FCN: A Motion and Memory-Based Deep Learning Model for Video Saliency Detection
Sep 21, 2018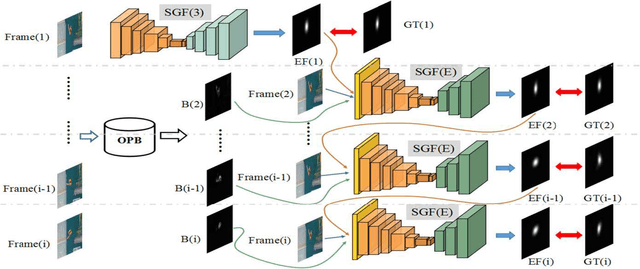
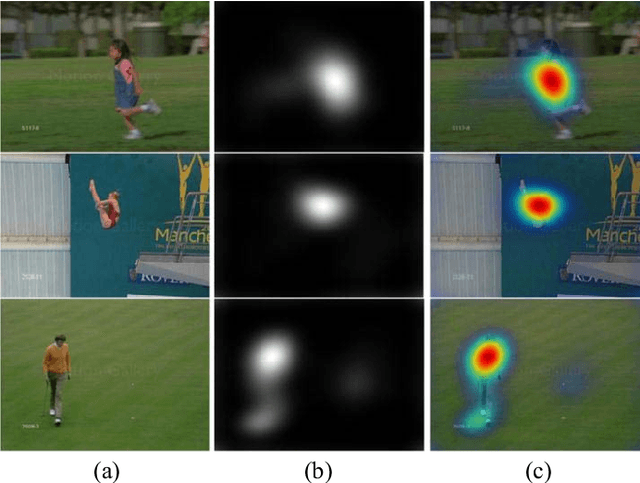
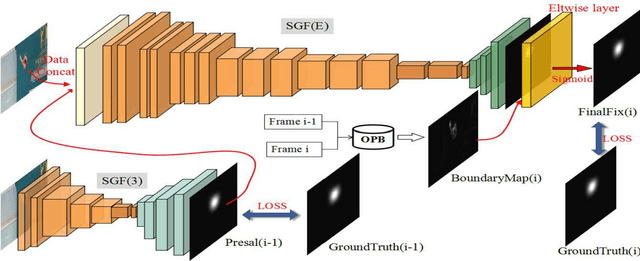
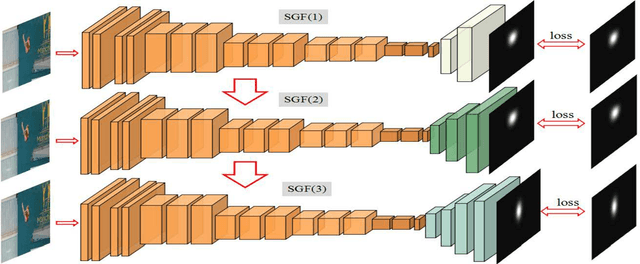
Data-driven saliency detection has attracted strong interest as a result of applying convolutional neural networks to the detection of eye fixations. Although a number of imagebased salient object and fixation detection models have been proposed, video fixation detection still requires more exploration. Different from image analysis, motion and temporal information is a crucial factor affecting human attention when viewing video sequences. Although existing models based on local contrast and low-level features have been extensively researched, they failed to simultaneously consider interframe motion and temporal information across neighboring video frames, leading to unsatisfactory performance when handling complex scenes. To this end, we propose a novel and efficient video eye fixation detection model to improve the saliency detection performance. By simulating the memory mechanism and visual attention mechanism of human beings when watching a video, we propose a step-gained fully convolutional network by combining the memory information on the time axis with the motion information on the space axis while storing the saliency information of the current frame. The model is obtained through hierarchical training, which ensures the accuracy of the detection. Extensive experiments in comparison with 11 state-of-the-art methods are carried out, and the results show that our proposed model outperforms all 11 methods across a number of publicly available datasets.