 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCamouflage-aware Image-Text Retrieval via Expert Collaboration
Apr 01, 2026Camouflaged scene understanding (CSU) has attracted significant attention due to its broad practical implications. However, in this field, robust image-text cross-modal alignment remains under-explored, hindering deeper understanding of camouflaged scenarios and their related applications. To this end, we focus on the typical image-text retrieval task, and formulate a new task dubbed ``camouflage-aware image-text retrieval'' (CA-ITR). We first construct a dedicated camouflage image-text retrieval dataset (CamoIT), comprising $\sim$10.5K samples with multi-granularity textual annotations. Benchmark results conducted on CamoIT reveal the underlying challenges of CA-ITR for existing cutting-edge retrieval techniques, which are mainly caused by objects' camouflage properties as well as those complex image contents. As a solution, we propose a camouflage-expert collaborative network (CECNet), which features a dual-branch visual encoder: one branch captures holistic image representations, while the other incorporates a dedicated model to inject representations of camouflaged objects. A novel confidence-conditioned graph attention (C\textsuperscript{2}GA) mechanism is incorporated to exploit the complementarity across branches. Comparative experiments show that CECNet achieves $\sim$29% overall CA-ITR accuracy boost, surpassing seven representative retrieval models. The dataset and code will be available at https://github.com/jiangyao-scu/CA-ITR.
Enhancing Adaptivity of Two-Fingered Object Reorientation Using Tactile-based Online Optimization of Deconstructed Actions
Mar 14, 2025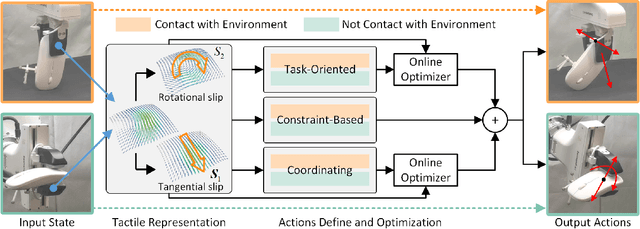
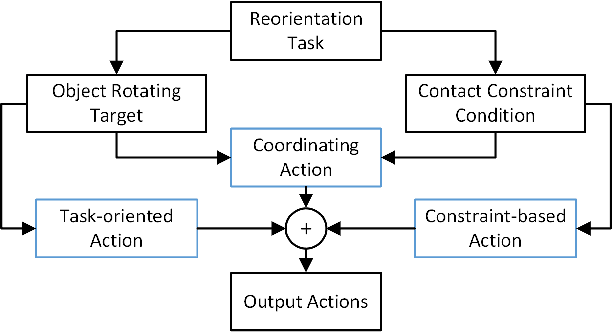
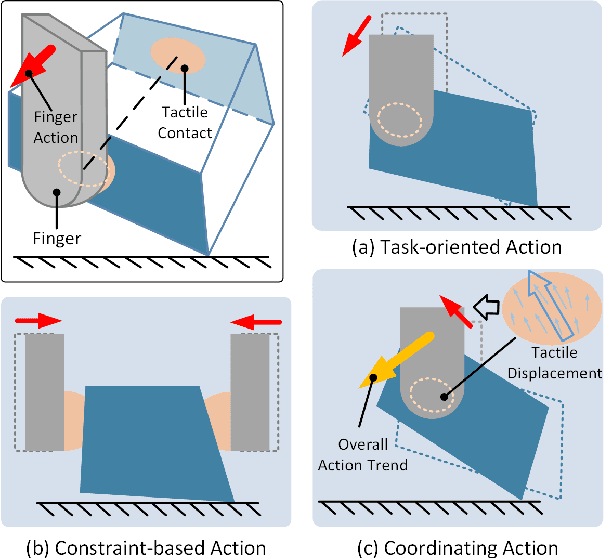
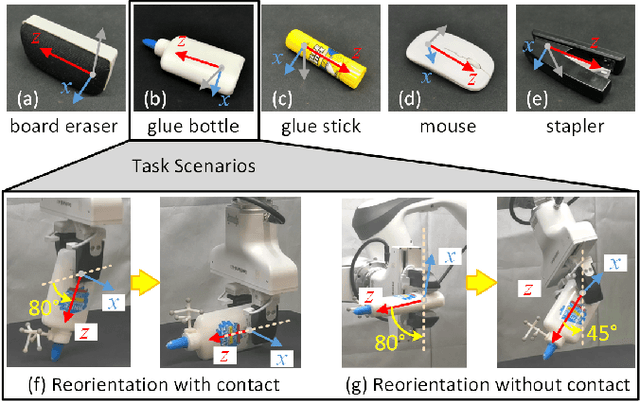
Object reorientation is a critical task for robotic grippers, especially when manipulating objects within constrained environments. The task poses significant challenges for motion planning due to the high-dimensional output actions with the complex input information, including unknown object properties and nonlinear contact forces. Traditional approaches simplify the problem by reducing degrees of freedom, limiting contact forms, or acquiring environment/object information in advance, which significantly compromises adaptability. To address these challenges, we deconstruct the complex output actions into three fundamental types based on tactile sensing: task-oriented actions, constraint-oriented actions, and coordinating actions. These actions are then optimized online using gradient optimization to enhance adaptability. Key contributions include simplifying contact state perception, decomposing complex gripper actions, and enabling online action optimization for handling unknown objects or environmental constraints. Experimental results demonstrate that the proposed method is effective across a range of everyday objects, regardless of environmental contact. Additionally, the method exhibits robust performance even in the presence of unknown contacts and nonlinear external disturbances.
Enhancing Regrasping Efficiency Using Prior Grasping Perceptions with Soft Fingertips
Mar 14, 2025



Grasping the same object in different postures is often necessary, especially when handling tools or stacked items. Due to unknown object properties and changes in grasping posture, the required grasping force is uncertain and variable. Traditional methods rely on real-time feedback to control the grasping force cautiously, aiming to prevent slipping or damage. However, they overlook reusable information from the initial grasp, treating subsequent regrasping attempts as if they were the first, which significantly reduces efficiency. To improve this, we propose a method that utilizes perception from prior grasping attempts to predict the required grasping force, even with changes in position. We also introduce a calculation method that accounts for fingertip softness and object asymmetry. Theoretical analyses demonstrate the feasibility of predicting grasping forces across various postures after a single grasp. Experimental verifications attest to the accuracy and adaptability of our prediction method. Furthermore, results show that incorporating the predicted grasping force into feedback-based approaches significantly enhances grasping efficiency across a range of everyday objects.
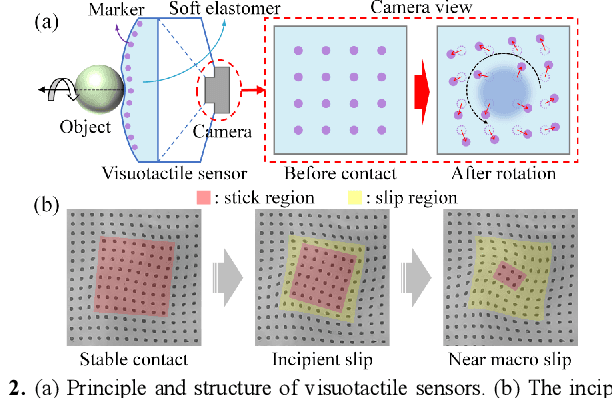
Modeling, Simulation, and Application of Spatio-Temporal Characteristics Detection in Incipient Slip
Feb 24, 2025Incipient slip detection provides critical feedback for robotic grasping and manipulation tasks. However, maintaining its adaptability under diverse object properties and complex working conditions remains challenging. This article highlights the importance of completely representing spatio-temporal features of slip, and proposes a novel approach for incipient slip modeling and detection. Based on the analysis of localized displacement phenomenon, we establish the relationship between the characteristic strain rate extreme events and the local slip state. This approach enables the detection of both the spatial distribution and temporal dynamics of stick-slip regions. Also, the proposed method can be applied to strain distribution sensing devices, such as vision-based tactile sensors. Simulations and prototype experiments validated the effectiveness of this approach under varying contact conditions, including different contact geometries, friction coefficients, and combined loads. Experiments demonstrated that this method not only accurately and reliably delineates incipient slip, but also facilitates friction parameter estimation and adaptive grasping control.
An Adaptive Grasping Force Tracking Strategy for Nonlinear and Time-Varying Object Behaviors
Dec 03, 2024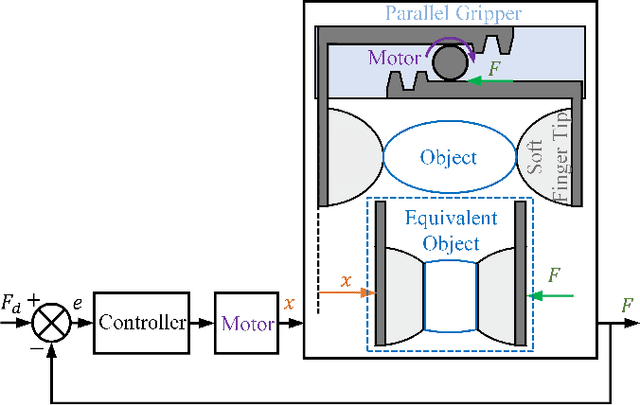

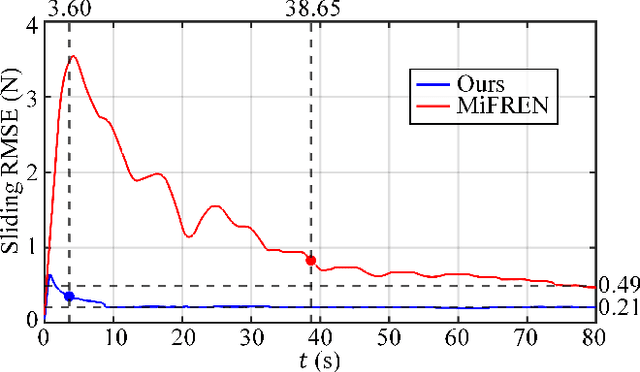

Accurate grasp force control is one of the key skills for ensuring successful and damage-free robotic grasping of objects. Although existing methods have conducted in-depth research on slip detection and grasping force planning, they often overlook the issue of adaptive tracking of the actual force to the target force when handling objects with different material properties. The optimal parameters of a force tracking controller are significantly influenced by the object's stiffness, and many adaptive force tracking algorithms rely on stiffness estimation. However, real-world objects often exhibit viscous, plastic, or other more complex nonlinear time-varying behaviors, and existing studies provide insufficient support for these materials in terms of stiffness definition and estimation. To address this, this paper introduces the concept of generalized stiffness, extending the definition of stiffness to nonlinear time-varying grasp system models, and proposes an online generalized stiffness estimator based on Long Short-Term Memory (LSTM) networks. Based on generalized stiffness, this paper proposes an adaptive parameter adjustment strategy using a PI controller as an example, enabling dynamic force tracking for objects with varying characteristics. Experimental results demonstrate that the proposed method achieves high precision and short probing time, while showing better adaptability to non-ideal objects compared to existing methods. The method effectively solves the problem of grasp force tracking in unknown, nonlinear, and time-varying grasp systems, enhancing the robotic grasping ability in unstructured environments.
Learning Gentle Grasping from Human-Free Force Control Demonstration
Sep 16, 2024Humans can steadily and gently grasp unfamiliar objects based on tactile perception. Robots still face challenges in achieving similar performance due to the difficulty of learning accurate grasp-force predictions and force control strategies that can be generalized from limited data. In this article, we propose an approach for learning grasping from ideal force control demonstrations, to achieve similar performance of human hands with limited data size. Our approach utilizes objects with known contact characteristics to automatically generate reference force curves without human demonstrations. In addition, we design the dual convolutional neural networks (Dual-CNN) architecture which incorporating a physics-based mechanics module for learning target grasping force predictions from demonstrations. The described method can be effectively applied in vision-based tactile sensors and enables gentle and stable grasping of objects from the ground. The described prediction model and grasping strategy were validated in offline evaluations and online experiments, and the accuracy and generalizability were demonstrated.
EasyCalib: Simple and Low-Cost In-Situ Calibration for Force Reconstruction with Vision-Based Tactile Sensors
Mar 15, 2024For elastomer-based tactile sensors, represented by visuotactile sensors, routine calibration of mechanical parameters (Young's modulus and Poisson's ratio) has been shown to be important for force reconstruction. However, the reliance on existing in-situ calibration methods for accurate force measurements limits their cost-effective and flexible applications. This article proposes a new in-situ calibration scheme that relies only on comparing contact deformation. Based on the detailed derivations of the normal contact and torsional contact theories, we designed a simple and low-cost calibration device, EasyCalib, and validated its effectiveness through extensive finite element analysis. We also explored the accuracy of EasyCalib in the practical application and demonstrated that accurate contact distributed force reconstruction can be realized based on the mechanical parameters obtained. EasyCalib balances low hardware cost, ease of operation, and low dependence on technical expertise and is expected to provide the necessary accuracy guarantees for wide applications of visuotactile sensors in the wild.
Effectiveness Assessment of Recent Large Vision-Language Models
Mar 07, 2024The advent of large vision-language models (LVLMs) represents a noteworthy advancement towards the pursuit of artificial general intelligence. However, the extent of their efficacy across both specialized and general tasks warrants further investigation. This article endeavors to evaluate the competency of popular LVLMs in specialized and general tasks, respectively, aiming to offer a comprehensive comprehension of these innovative methodologies. To gauge their efficacy in specialized tasks, we tailor a comprehensive testbed comprising three distinct scenarios: natural, healthcare, and industrial, encompassing six challenging tasks. These tasks include salient, camouflaged, and transparent object detection, as well as polyp and skin lesion detection, alongside industrial anomaly detection. We examine the performance of three recent open-source LVLMs -- MiniGPT-v2, LLaVA-1.5, and Shikra -- in the realm of visual recognition and localization. Moreover, we conduct empirical investigations utilizing the aforementioned models alongside GPT-4V, assessing their multi-modal understanding capacities in general tasks such as object counting, absurd question answering, affordance reasoning, attribute recognition, and spatial relation reasoning. Our investigations reveal that these models demonstrate limited proficiency not only in specialized tasks but also in general tasks. We delve deeper into this inadequacy and suggest several potential factors, including limited cognition in specialized tasks, object hallucination, text-to-image interference, and decreased robustness in complex problems. We hope this study would provide valuable insights for the future development of LVLMs, augmenting their power in coping with both general and specialized applications.
Incipient Slip-Based Rotation Measurement via Visuotactile Sensing During In-Hand Object Pivoting
Sep 14, 2023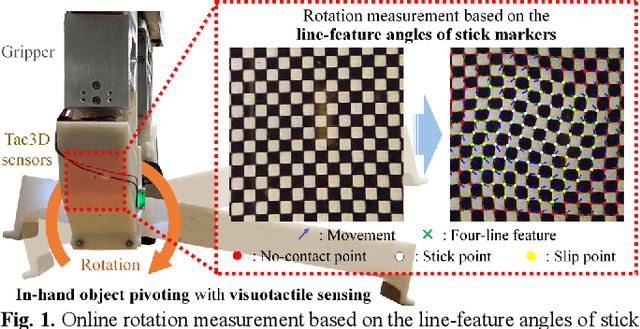
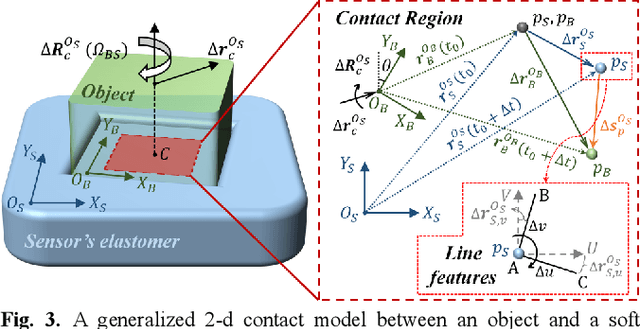
In typical in-hand manipulation tasks represented by object pivoting, the real-time perception of rotational slippage has been proven beneficial for improving the dexterity and stability of robotic hands. An effective strategy is to obtain the contact properties for measuring rotation angle through visuotactile sensing. However, existing methods for rotation estimation did not consider the impact of the incipient slip during the pivoting process, which introduces measurement errors and makes it hard to determine the boundary between stable contact and macro slip. This paper describes a generalized 2-d contact model under pivoting, and proposes a rotation measurement method based on the line-features in the stick region. The proposed method was applied to the Tac3D vision-based tactile sensors using continuous marker patterns. Experiments show that the rotation measurement system could achieve an average static measurement error of 0.17 degree and an average dynamic measurement error of 1.34 degree. Besides, the proposed method requires no training data and can achieve real-time sensing during the in-hand object pivoting.
Real-time and Robust Feature Detection of Continuous Marker Pattern for Dense 3-D Deformation Measurement
May 22, 2023
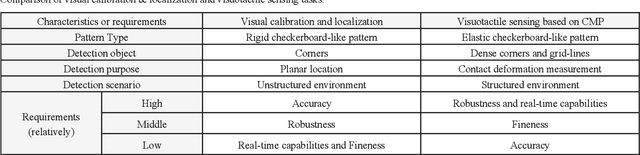
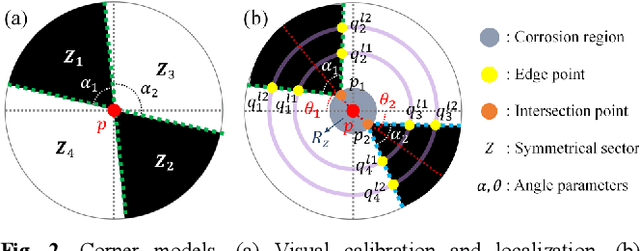
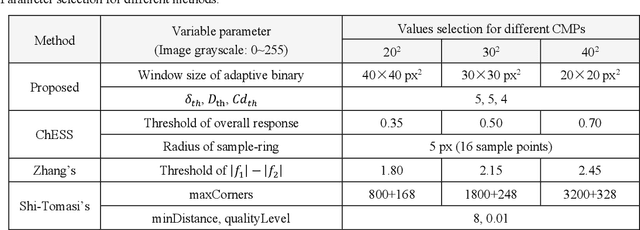
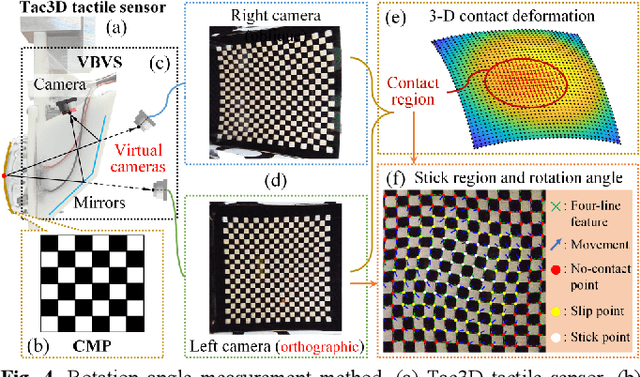
Visuotactile sensing technology has received much attention in recent years. This article proposes a feature detection method applicable to visuotactile sensors based on continuous marker patterns (CMP) to measure 3-d deformation. First, we construct the feature model of checkerboard-like corners under contact deformation, and design a novel double-layer circular sampler. Then, we propose the judging criteria and response function of corner features by analyzing sampling signals' amplitude-frequency characteristics and circular cross-correlation behavior. The proposed feature detection algorithm fully considers the boundary characteristics retained by the corners with geometric distortion, thus enabling reliable detection at a low calculation cost. The experimental results show that the proposed method has significant advantages in terms of real-time and robustness. Finally, we have achieved the high-density 3-d contact deformation visualization based on this detection method. This technique is able to clearly record the process of contact deformation, thus enabling inverse sensing of dynamic contact processes.