 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuided Focal Stack Refinement Network for Light Field Salient Object Detection
Paper and Code
May 09, 2023


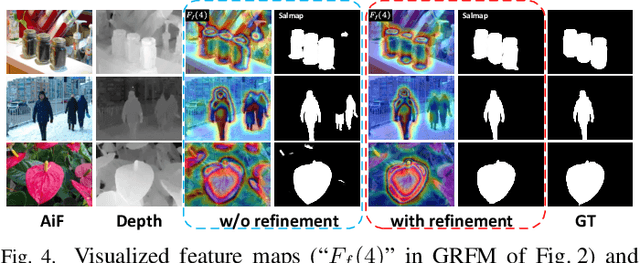
Light field salient object detection (SOD) is an emerging research direction attributed to the richness of light field data. However, most existing methods lack effective handling of focal stacks, therefore making the latter involved in a lot of interfering information and degrade the performance of SOD. To address this limitation, we propose to utilize multi-modal features to refine focal stacks in a guided manner, resulting in a novel guided focal stack refinement network called GFRNet. To this end, we propose a guided refinement and fusion module (GRFM) to refine focal stacks and aggregate multi-modal features. In GRFM, all-in-focus (AiF) and depth modalities are utilized to refine focal stacks separately, leading to two novel sub-modules for different modalities, namely AiF-based refinement module (ARM) and depth-based refinement module (DRM). Such refinement modules enhance structural and positional information of salient objects in focal stacks, and are able to improve SOD accuracy. Experimental results on four benchmark datasets demonstrate the superiority of our GFRNet model against 12 state-of-the-art models.